The paper introduces a scalable, data-efficient cascaded framework for conversational TTS that combines textual style tokens with human-curated audio prompts using In-Context Learning (ICL). It achieves fine-grained prosody and timbre control and further refines quality via a novel ICL-based online Reinforcement Learning (RL) strategy optimized by aesthetic rewards.
TL;DR
Meta AI researchers have developed a new framework for conversational Text-to-Speech (TTS) that bypasses the need for massive labeled emotional datasets. By treating short audio clips as In-Context Learning (ICL) prompts and refining the output through Online Reinforcement Learning (RL), the system achieves state-of-the-art naturalness and expressivity, even outperforming commercial benchmarks like GPT-4o in nuanced emotional dimensions.
Problem & Motivation: The Data Bottleneck
Creating a "human-like" AI voice usually requires a trade-off. You either use coarse-grained labels (Happy, Sad, Angry), which lack nuance, or you collect thousands of hours of meticulously annotated emotional speech, which is prohibitively expensive.
Furthermore, in multi-turn conversations, maintaining speaker consistency while allowing for dynamic emotional shifts is a major technical hurdle. Previous models often suffered from "speaker drift" or "hallucinations"—where the model makes up sounds or skips words in an attempt to sound more emotional.
Methodology: The Cascaded ICL Approach
The core insight of this paper is that LLMs are already great at predicting how something should be said. The authors bridge the gap between LLM "intent" and TTS "execution" through two key mechanisms:
1. Cascaded Prompting (The "How-to" Guide)
The architecture splits the task:
- Autoregressive (AR) Prosody Model: Takes a textual style token (e.g., "[Whimsical]") and a high-quality human audio prompt. It learns the rhythm and intonation (prosody) from the prompt via ICL.
- Diffusion-based Acoustic Model: Focuses on timbre and voice quality. Interestingly, the authors found that prosody and timbre can be decoupled. You don't need the same prompt speaker for both models; the acoustic model defines "who" is talking, while the AR model defines "how" they talk.
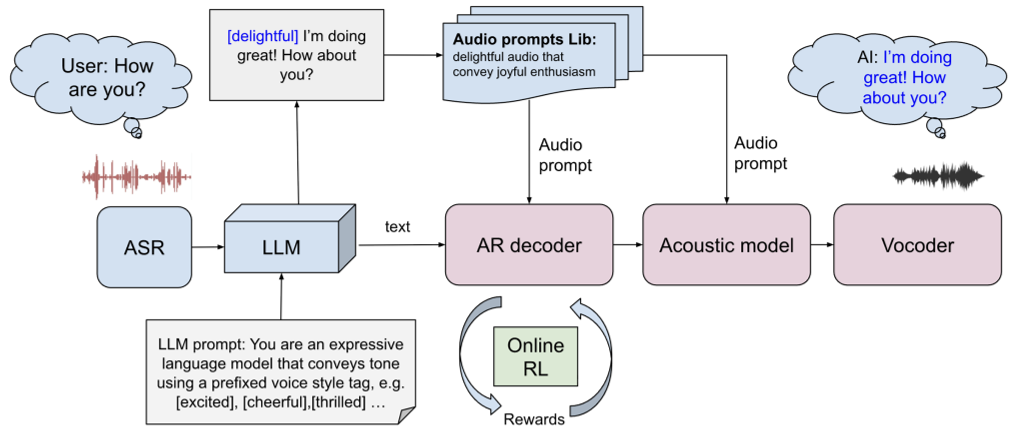 Figure 1: The framework integrates LLM-generated style tokens with curated audio prompts.
Figure 1: The framework integrates LLM-generated style tokens with curated audio prompts.
2. Online RL with Structural Constraints
To avoid the high latency of "sampling and re-ranking" at inference time, the authors fine-tune the prosody model using Online Reinforcement Learning.
- The Reward: They use AES-CE (Aesthetic Quality Score), which mimics human preference for pleasant audio.
- The Guardrail: To prevent the model from "cheating" (e.g., making beautiful but nonsensical noises), they add a CTC (Connectionist Temporal Classification) Loss. This ensures the audio stays perfectly aligned with the written text.
Experiments & Results
The researchers tested their system against standard zero-shot baselines and the GPT-4o API using a metric called CVAD (Clarity, Valence, Arousal, Dominance).
- Expressivity Leap: The ICL-based approach showed a +79.6% improvement in CVAD scores over the baseline.
- Consistency: By grouping fine-grained styles into coarser categories for the acoustic model, they significantly reduced speaker drift in long dialogues.
- RL Gains: Adding the Online RL step provided a +7.1% net win rate over simple Supervised Fine-Tuning (SFT).
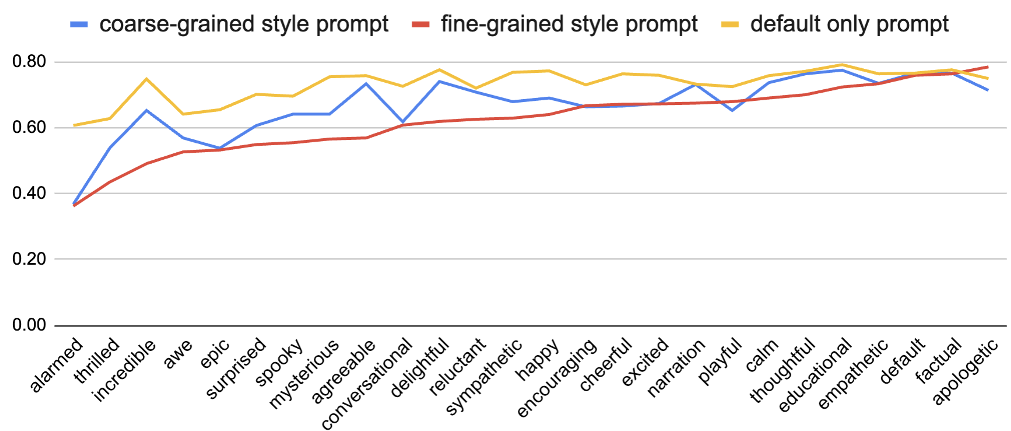 Figure 2: Analysis of speaker similarity across different style granularities.
Figure 2: Analysis of speaker similarity across different style granularities.
Critical Analysis & Conclusion
Takeaway
This research proves that context is king. Instead of hard-coding emotions, providing the model with a "reference vibe" (audio prompt) and a "directional token" (textual style) allows for much more flexible and human-like interactions. The integration of CTC loss as a regularizer for RL is a brilliant "safety first" approach for generative audio.
Limitations & Future Work
The process still involves a "human-in-the-loop" for initial prompt selection, which, while scalable, isn't fully autonomous. Future iterations might focus on automated style discovery where the LLM can synthesize its own reference prompts to steer the TTS system without any human intervention.
For those looking to build the next generation of voice assistants, this paper provides a robust blueprint: Cascaded architecture + ICL Prompting + Constrained RL Alignment.