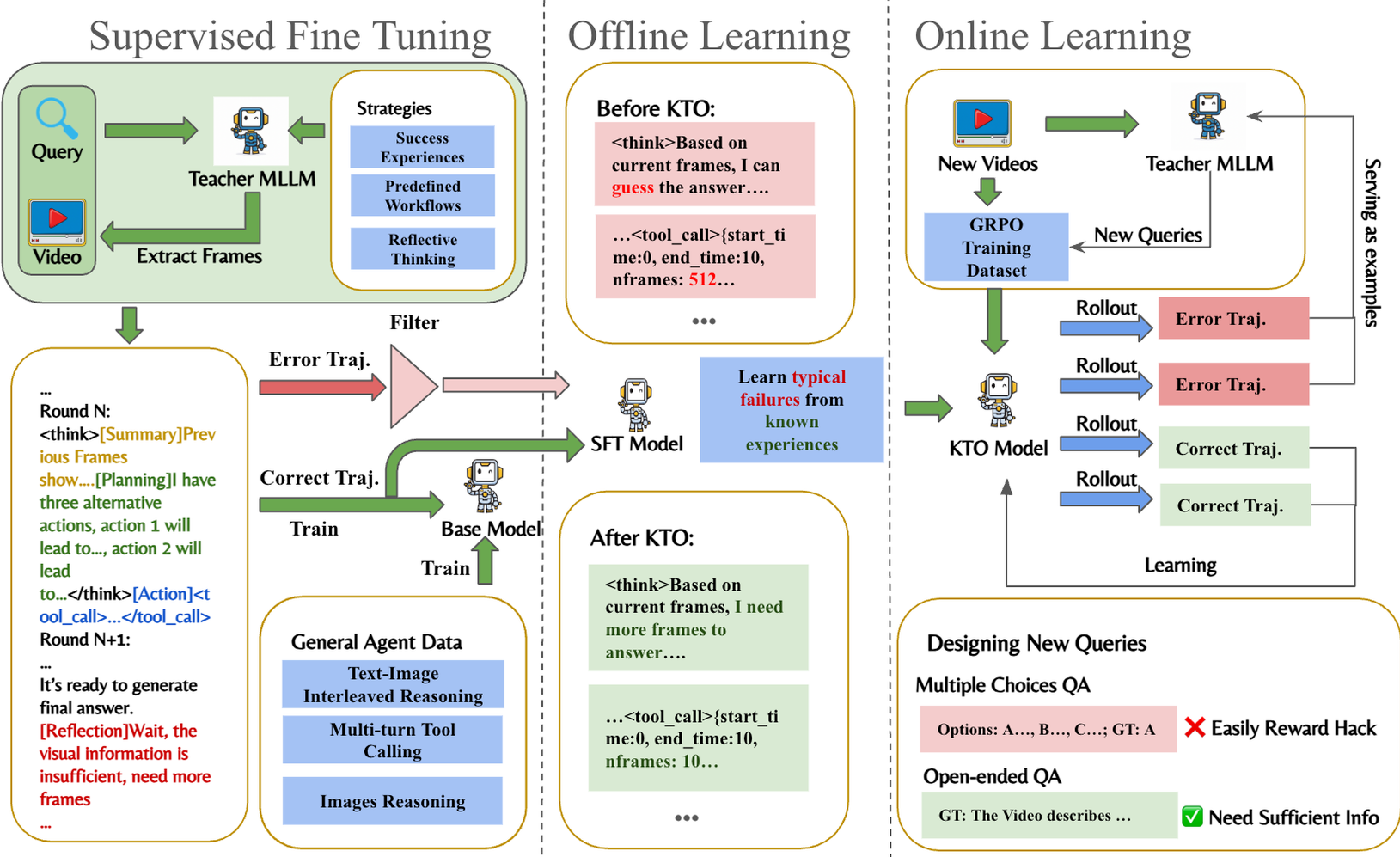
EVA is an efficient reinforcement learning framework for end-to-end video agents that transforms MLLMs from passive recognizers into active observers. By adopting a "planning-before-perception" paradigm and a three-stage training pipeline (SFT, KTO, and GRPO), it achieves a 6–12% improvement over general MLLM baselines while significantly reducing visual token consumption.
Executive Summary
TL;DR: EVA (Efficient Video Agent) is a breakthrough framework that flips the script on video understanding. Instead of feeding a model thousands of frames and asking it to "find the needle," EVA empowers the model to plan its observation strategy first. By utilizing a three-stage RL pipeline (SFT -> KTO -> GRPO), EVA learns to navigate long videos (up to 6600s) with surgical precision, reducing token usage by over 90% while actually increasing accuracy by 6-12%.
Background Positioning: This work represents a shift from Passive Perception (standard MLLMs) to Active Agency. In the landscape of SOTA video models, EVA moves beyond fixed-sampling baselines and rigid tool-use to achieve a truly autonomous, iterative reasoning loop.
The Core Problem: The Sampling Dilemma
Current Video-LLMs face a paradox:
- Dense Sampling: High accuracy but hits the "context wall" and burns massive compute.
- Uniform Sampling: Efficient but misses brief, critical events (the "needle in a haystack" problem).
The authors argue the root cause is Perception-First architecture. Models are conditioned to look at what they are given. EVA proposes a Planning-First approach: "Tell me what you’re looking for, and I’ll decide which frames are worth my attention."
Methodology: Planning-Before-Perception
EVA operates on a Markov Decision Process (MDP) through an iterative cycle: Summary $\rightarrow$ Plan $\rightarrow$ Action $\rightarrow$ Reflection.
1. The Flexible Toolset
Unlike prior agents restricted to temporal windowing, EVA controls:
- start_time / end_time: Precise temporal localization.
- nframes: Temporal density.
- resize: Spatial resolution (zooming in for fine details).
2. The Three-Stage Evolution
- Stage 1: SFT Cold-Start: Teaches the model the "language" of tools and basic interaction formats.
- Stage 2: KTO (Kahneman-Tversky Optimization): Instead of complex pairwise rankings, KTO uses binary "success/failure" labels to help the model avoid common strategic pitfalls (like "guessing" without enough data).
- Stage 3: Data-Enhanced GRPO: An online RL phase where the model explores self-generated trajectories. Crucially, the authors use a "Data-Enhanced" loop, generating new, harder QA pairs based on current model failures to prevent policy stagnation.
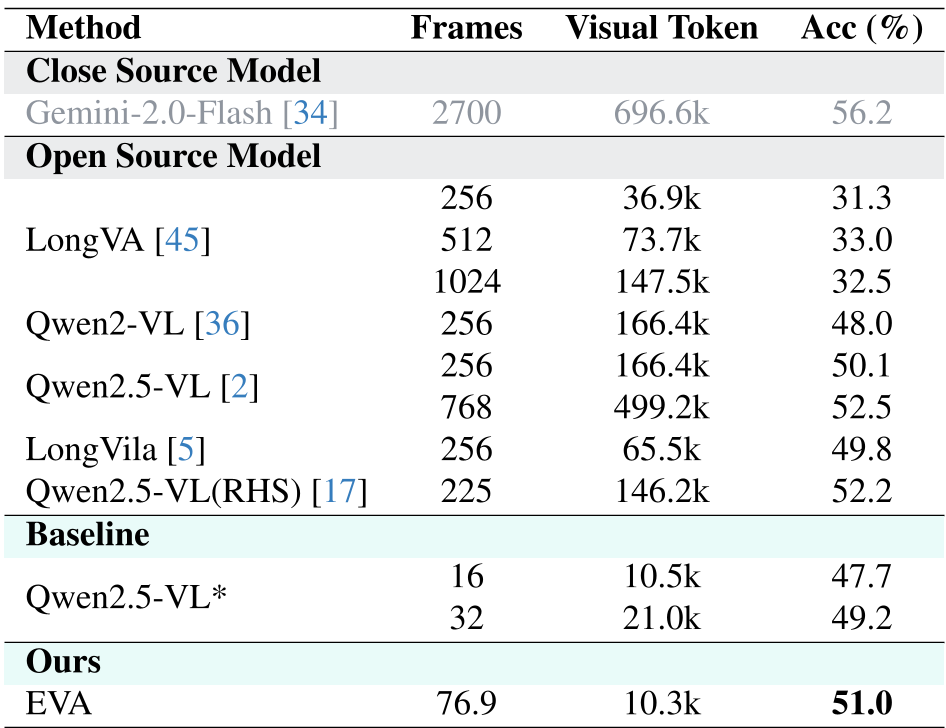
Experimental Performance: Efficiency Meets Power
EVA was tested against heavyweights like Gemini 2.0 and GPT-4o. The results on LSDBench are particularly striking:
- Baseline (Qwen2.5-VL): 50.1% Acc @ 166k tokens.
- EVA: 51.0% Acc @ 10.3k tokens.
EVA achieves a roughly 16x reduction in visual token costs while maintaining higher accuracy.
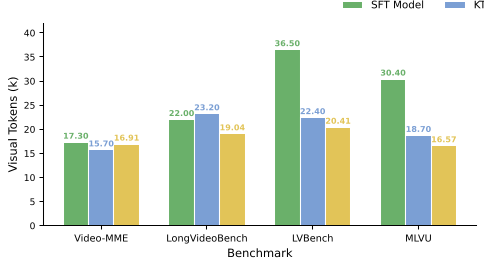
Ablation Insight: Why GRPO Matters
The ablation study (Figure 4) shows that as the model progresses from SFT to GRPO, it learns to be smarter, not faster. GRPO-trained agents use fewer total frames but engage in more interaction rounds—effectively "thinking twice" before committing to an answer.
Critical Analysis & Takeaways
Why it works: EVA succeeds because it treats "watching a video" as a resource allocation problem. By explicitly modeling Reflection, the model learns to say "I don't have enough info yet, let me zoom in on the 02:30 mark" rather than hallucinating based on a blurry global average.
Limitations: The framework currently relies on a fixed API for "frame selection." If the tool itself fails to capture motion (e.g., fast-moving tiny objects), the agent is still limited by its "eyes."
Future Outlook: The "Planning-before-perception" philosophy is a blueprint for the next generation of AI agents. Expect this logic to move into web navigation and robotic manipulation, where the cost of "looking everywhere" is simply too high.
References
- Zhang et al., (2025). "EVA: Efficient Reinforcement Learning for End-to-End Video Agent." SenseTime Research.