本文推出了 EVA,一个基于强化学习的端到端视频智能体(End-to-End Video Agent)。该框架通过“先规划后感知”(Planning-before-perception)的迭代机制,使多模态大模型能够自主决定视频观看的时机与方式,在长内容理解上显著提升了效率与准确度。
TL;DR
在视频理解领域,模型通常是被“喂”什么看什么。商汤科技团队推出的 EVA (Efficient Video Agent) 彻底颠覆了这一逻辑。它提倡**“先规划后感知” (Planning-before-perception)**,让模型像人一样先根据问题思考该看哪段、怎么看,随后才调用工具调取视频。通过 SFT -> KTO -> GRPO 三阶段进化,EVA 在将视觉 Token 消耗降低 10 倍以上的同时,性能却超越了目前的 SOTA 基线。
1. 痛点:视频理解中的“采样困境”
当前的视频大模型(MLLM)面临一个尴尬的局面:
- 暴力全量采样:Token 数量爆炸,由于自注意力机制的复杂度,长上下文处理变得极度缓慢且昂贵。
- 均匀稀疏采样:极易丢失关键帧。如果一个 2 小时的视频只抽 32 帧,哪怕最先进的模型也会因信息缺失而“胡说八道”。
- 感知优先的陷阱:现有智能体通常先看一遍视频再思考。但在长视频中,这种“先看再想”的行为本身就已经造成了巨大的资源浪费。
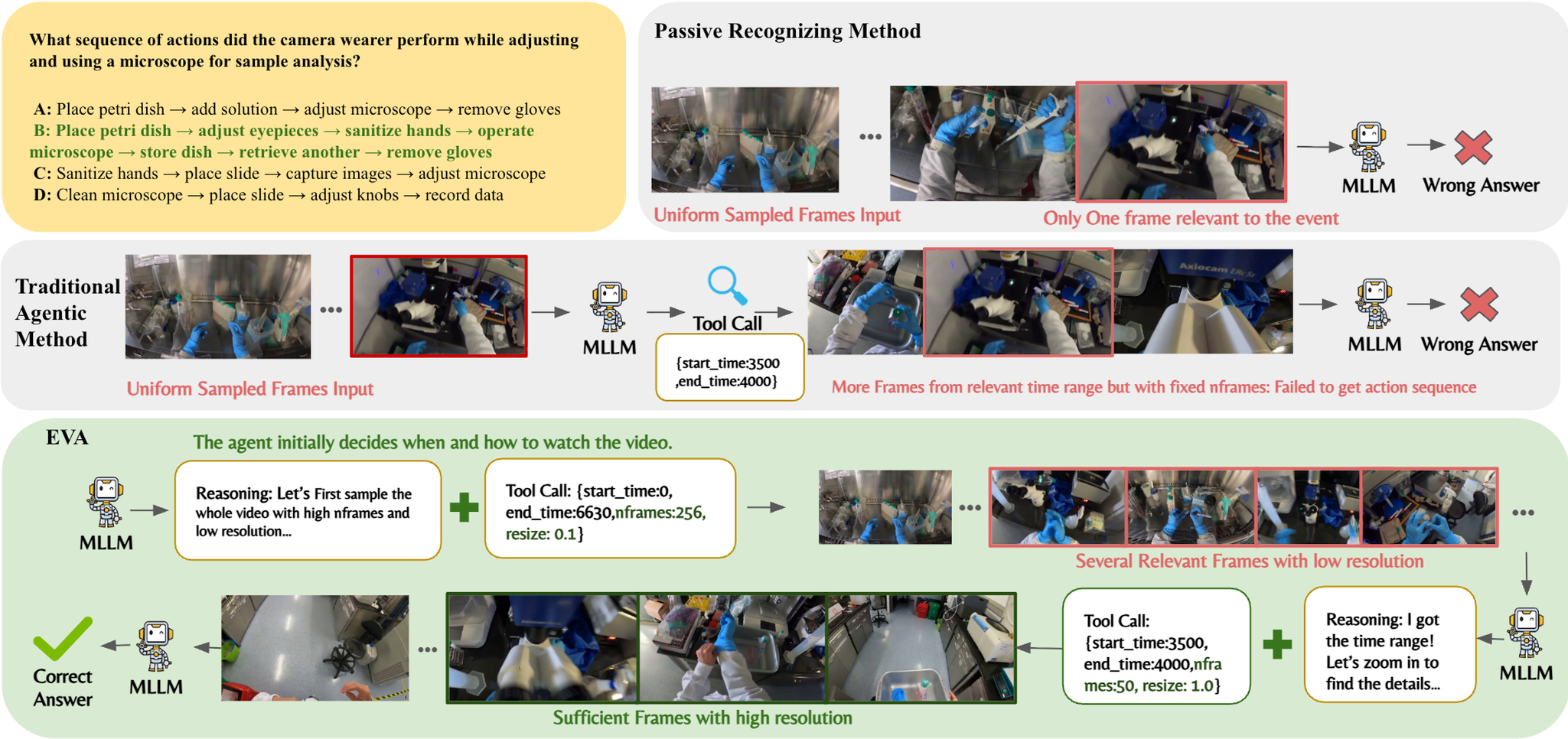 图 1:EVA 与传统方法对比。EVA 可以先以低分辨率概览全图,定位后通过高分辨率“特写”获取细节。
图 1:EVA 与传统方法对比。EVA 可以先以低分辨率概览全图,定位后通过高分辨率“特写”获取细节。
2. 核心机制:Iterative Reasoning 环路
EVA 的核心在于一套 Summary-Plan-Action-Reflection 的闭环:
- Summary(摘要):描述已观察到的内容。
- Planning(规划):根据问题和已知信息,思考接下来需要补充哪些视觉证据(时间点、分辨率、帧率)。
- Action(动作):生成具体的工具调用指令(
frame_select)。 - Reflection(反思):判断当前信息是否足以回答问题,若不足,则继续循环。
这种机制将 MLLM 从一个“图像识别器”变成了一个具备主动探索能力的“视频观察者”。
3. 训练三部曲:SFT -> KTO -> GRPO
要让一个模型学会“聪明地看视频”并不容易,作者设计了精妙的训练路径:
- Stage 1: SFT Cold-Start:利用教师模型(如 Qwen2.5-VL-72B)生成高质量的推理迹线,教会模型基本的工具格式和逻辑模板。
- Stage 2: KTO Correction:引入前景理论(Prospect Theory)启发的 KTO 算法。针对模型容易“瞎猜”或“过度采样”的失败案例进行偏好学习,让模型学会在不确定时“不要急着回答,再去多看一眼”。
- Stage 3: Data-Enhanced GRPO:
- 采用 DeepSeek 系列火爆的 GRPO 进行在线强化学习。
- 数据增强:动态收集当前策略的失败案例,让教师模型生成新的、更具挑战性的 QA 对进行再训练。
- 奖励塑造:结合了多选验证(CSV Reward)和开放式生成的 ROUGE 分数,全方位引导模型提升准确度。
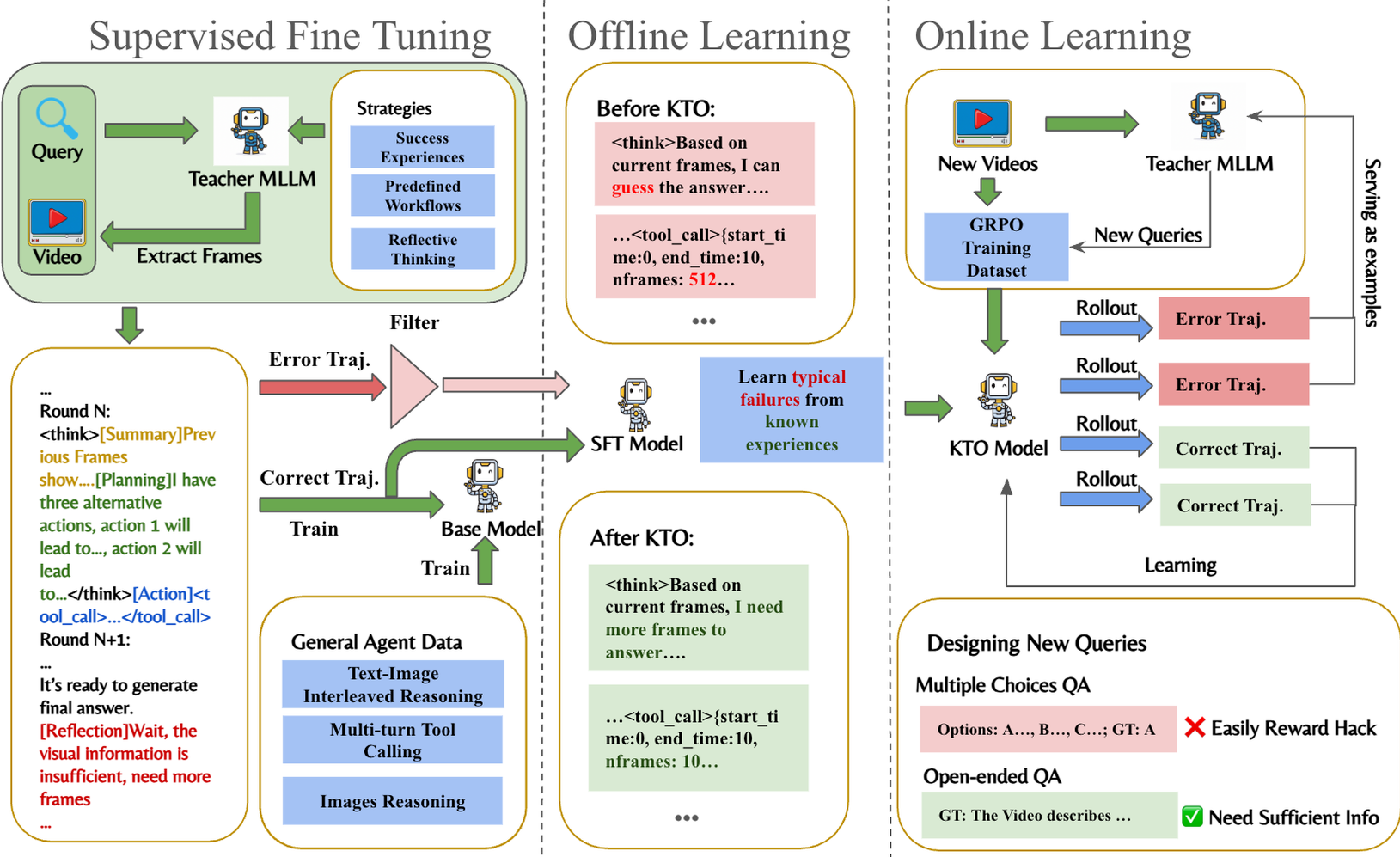 图 2:EVA 的三阶段训练流水线。
图 2:EVA 的三阶段训练流水线。
4. 实验战绩:低功耗,高智商
在 LSDBench(长视频抽样困境基准)测试中,EVA 的表现令人惊艳:
- Token 效率:在精度(51.8%)超过 Qwen2.5-VL 基线的情况下,使用的视觉 Token 仅为后者的 1/16。
- 推理深度:随着训练从 SFT 进化到 GRPO,可以看到模型不再倾向于在第一轮就草率给出答案,而是学会了增加交互轮数(Rounds)来交换更少的单轮帧数(Frames),这体现了极其先进的策略演化。
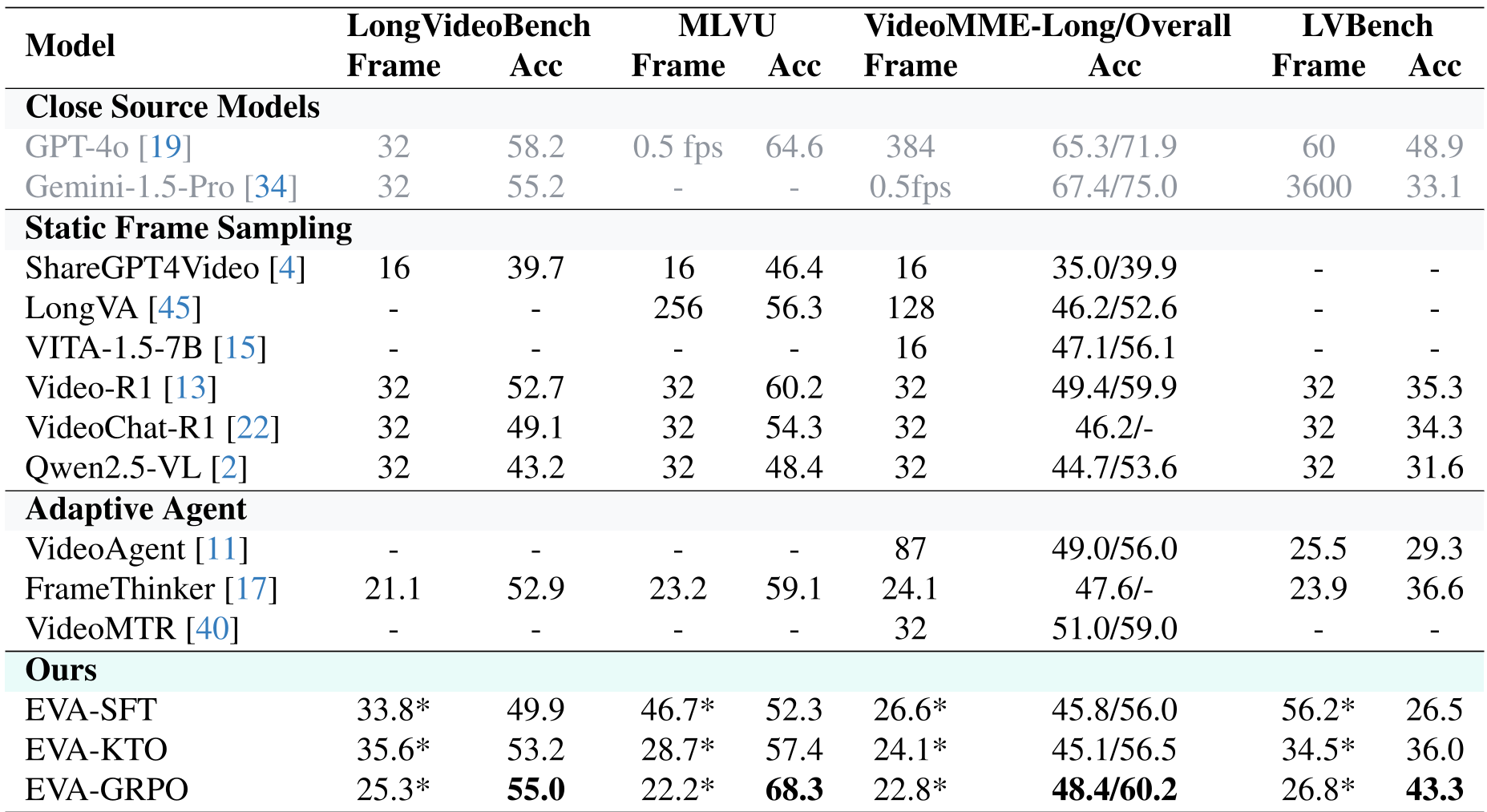 表 1:在各大长视频基准测试中,EVA 稳居开源模型第一梯队。
表 1:在各大长视频基准测试中,EVA 稳居开源模型第一梯队。
5. 深度洞察:为什么先规划更重要?
论文在附录中给出了精辟的解释:感知往往会带来偏见。 传统的“感知优先”模型如果第一波均匀采样的帧里包含误导性动作,模型会陷入“锚定效应”,试图强行解释这些无关动作。而 EVA 的“先规划”强制模型先逻辑化地推导“为了回答这个问题我应该寻找什么”,这种**意图驱动(Intention-driven)**的观察能有效过滤噪声。
总结
EVA 证明了在视频理解领域,单纯依靠 Scaling Laws 堆砌算力和上下文长度并非最优解。通过引入迭代推理和强化学习下的策略优化,模型可以表现得更像一个真正的“Agent”——它不仅理解视频,更懂得如何按需、高效、精准地去“读”视频。
随着 MLLM 算力成本的敏感度日益提升,这种“以思考换显存”的范式很可能成为未来视频交互的主流。