This paper introduces Experiential Reflective Learning (ERL), a self-improvement framework for LLM agents that distills past task trajectories into a pool of reusable, structured heuristics. By retrieving and injecting 20 relevant heuristics into the agent's context at test time, ERL achieves a 56.1% success rate on the Gaia2 benchmark, significantly outperforming standard ReAct baselines and prior experiential learning methods.
TL;DR
LLM agents often act like "Goldfish"—they forget lessons learned from one task when tackling the next. Experiential Reflective Learning (ERL) fixes this by allowing agents to reflect on single-attempt successes or failures, distilling them into a structured "Heuristic Library." During new tasks, the agent selectively retrieves these "cheat sheets," boosting success rates on the Gaia2 benchmark by nearly 8% and significantly increasing operational reliability.
The "Tabula Rasa" Problem in Agentic Systems
Despite the reasoning prowess of GPT-5-class models, most agents are deployed in a Tabula Rasa state. Every time an agent encounters a domain-specific quirk—like a specific tool's API sensitivity—it has to rediscover the solution through trial and error.
Previous attempts to solve this, such as ExpeL or AutoGuide, faced two major hurdles:
- Efficiency: They often required "contrastive pairs" (running a task multiple times to see what went wrong), which is expensive and often impossible in production.
- Scalability: Appending every past lesson to every prompt (context stuffing) eventually leads to "lost in the middle" phenomena and massive token costs.
Methodology: The Reflection-Retrieval Loop
ERL moves away from raw memory and toward abstracted wisdom. The process is split into two distinct phases.
1. Heuristic Generation (The Reflection)
Instead of saving the entire messy log (trajectory) of a task, ERL asks the LLM to reflect: "What was the critical move here? What should I do differently next time?" The result is a structured Heuristic:
- Analysis: Why did we succeed or fail?
- Guideline: A "When-Then" rule (e.g., "When rescheduling, always create the new event before deleting the old one").
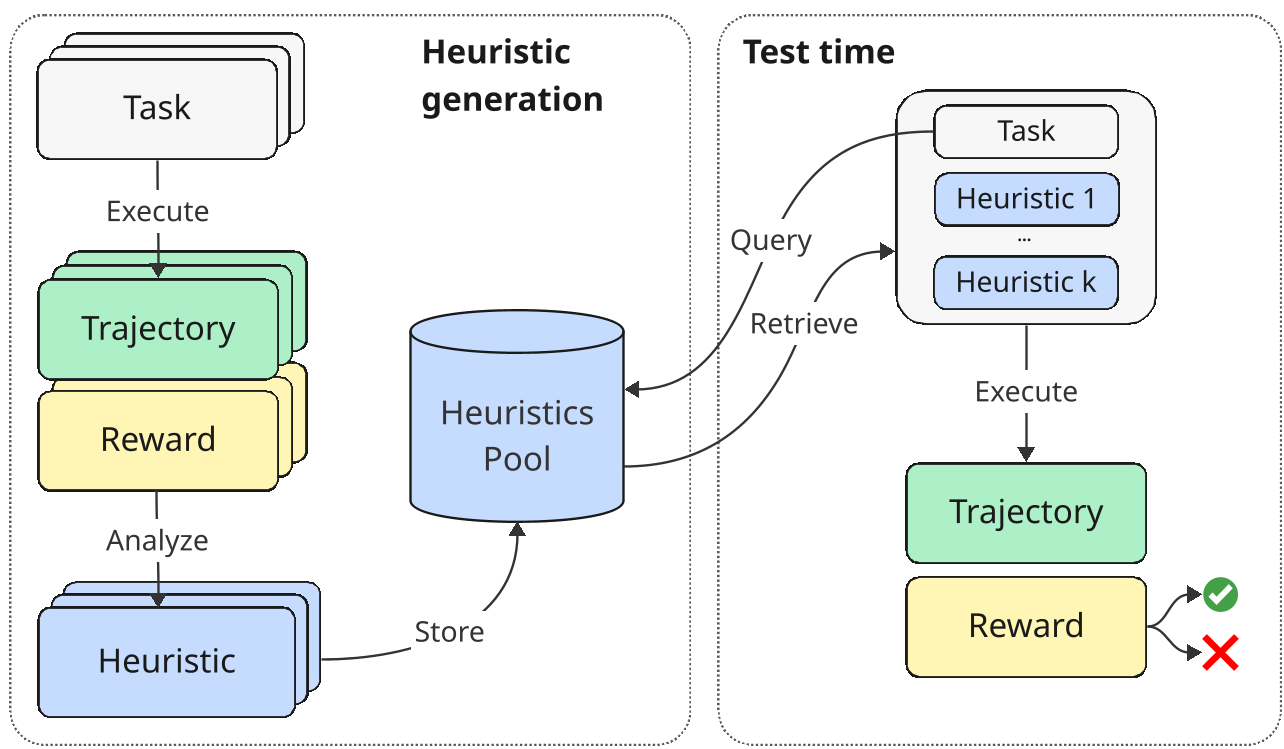 Figure 1: The ERL framework showing the dual-loop of experience accumulation and retrieval-augmented execution.
Figure 1: The ERL framework showing the dual-loop of experience accumulation and retrieval-augmented execution.
2. Retrieval-Augmented Execution
When a new task starts, the agent doesn't look at all heuristics. It uses an LLM-based ranker to pick the Top-k (k=20) most relevant strategies. This ensures the prompt stays lean while still being highly specialized for the current environment.
Experimental Insights: Wisdom > Raw Data
The authors tested ERL on Gaia2, a benchmark involving complex search and multi-tool execution.
Key Result 1: Heuristics Generalize Better
A fascinating finding shown in the "Token-Matched Comparison" is that raw trajectories (few-shot) actually hurt performance as they scale, likely due to noise. In contrast, distilled heuristics provide a clean, actionable signal that continues to improve performance as the library grows.
Key Result 2: Reliability (Pass^3)
ERL doesn't just help agents solve more tasks; it helps them solve tasks consistently. The pass^3 metric (success on three out of three tries) saw a double-digit jump in Search tasks (+10.6%), proving that heuristics mitigate the stochastic "flukiness" of LLM reasoning.
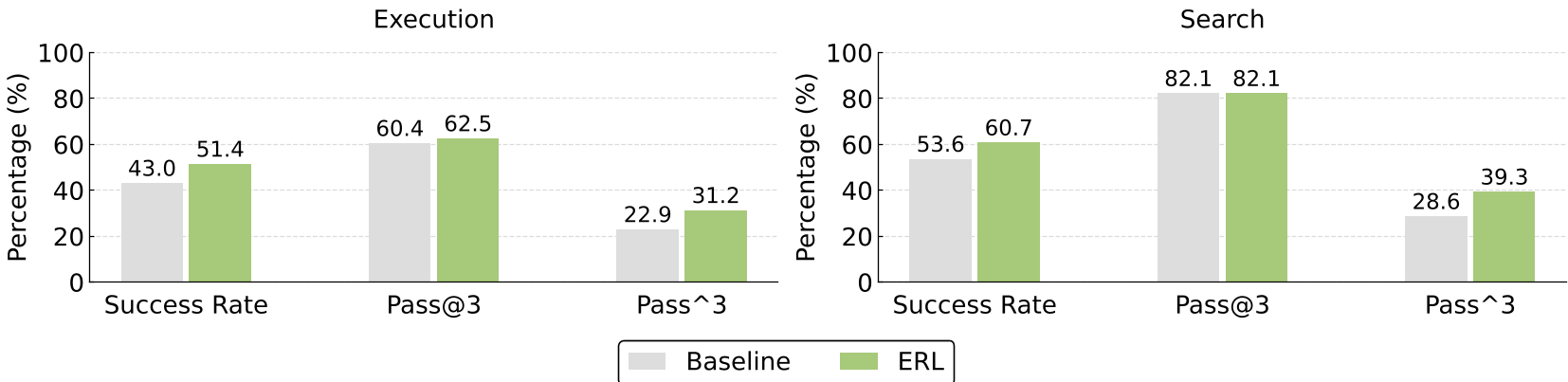 Figure 2: Performance gains in success rate and reliability metrics (pass@3 vs pass^3) comparing ERL to the baseline.
Figure 2: Performance gains in success rate and reliability metrics (pass@3 vs pass^3) comparing ERL to the baseline.
Key Result 3: Failures are the Best Teachers for Search
The study found a curious split:
- Search tasks benefited most from Failure Heuristics (learning what not to do helps prune the search space).
- Execution tasks benefited more from Success Heuristics (learning a proven sequence of tool calls).
Critical Analysis & Future Outlook
Takeaway: ERL proves that "system-level" learning (parameter-free) can be just as effective as fine-tuning for specialized environments, provided the distillation process is rigorous.
Limitations:
- Cost: ERL adds roughly 40% to API costs due to the retrieval and reflection steps.
- Conflicting Advice: As the heuristic pool grows to thousands of entries, how will the agent handle two heuristics that contradict each other? This remains an open challenge for long-term agent evolution.
ERL represents a significant step toward agents that actually grow with their users, transforming every failure into a permanent, retrievable asset.
Disclaimer: This blog is based on the paper "EXPERIENTIAL REFLECTIVE LEARNING FOR SELF-IMPROVING LLM AGENTS".