本文提出了 Experiential Reflective Learning (ERL),一种旨在通过经验积累实现自我进化的 LLM Agent 框架。ERL 通过反思任务轨迹生成可复用的启发式准则(Heuristics),并在测试时动态检索相关准则注入 Context。在 Gaia2 基准测试中,该方法将 ReAct 基线的成功率提升了 7.8%,显著增强了 Agent 处理复杂长程任务的可靠性。
TL;DR
面对陌生环境,人类会总结经验教训以防重蹈覆辙,但 LLM Agent 通常“记吃不记打”,每个任务都从头开始。本文提出的 Experiential Reflective Learning (ERL) 框架通过将过往的成功或失败轨迹反思为启发式准则 (Heuristics),并在新任务中精准检索和应用这些准则,使 Agent 具备了持续自我进化的能力。在 Gaia2 基准上,该方法不仅刷新了 SOTA,更在任务执行的稳定性上实现了质的飞跃。
痛点深挖:为什么 LLM Agent 难以“久经沙场”?
当前的 LLM Agent(如 ReAct 架构)在处理多步规划时存在两个核心局限:
- 经验孤岛:Agent 不会存储过往与工具交互的细节,导致即使之前在同一类任务上栽过跟头,下次由于上下文刷新,依然会犯同样的错。
- 泛化瓶颈:现有的经验学习方法(如把之前的对话作为 Few-shot)太吃 Context 长度,且原始轨迹中充满了噪声,模型很难直接从长长的 Log 中学习抽象规律。
核心方法:从轨迹到启发式准则 (Heuristics)
ERL 的核心直觉是:轨迹是具体的,但逻辑是通用的。
1. 结构化反思 (Heuristic Generation)
Agent 在完成(或失败)一个任务后,会启动一个反思模块。它不仅仅记录“我做了什么”,而是生成一个包含以下要素的准则:
- 分析 (Analysis):识别导致成功的关键步骤或导致失败的陷阱。
- 准则 (Guideline):带有明确触发条件(Trigger Conditions)的操作建议。例如:“在调用发送邮件 API 前,务必先通过联系人工具解析姓名”。
2. 模型架构与流程
如图 1 所示,ERL 分为经验累积和检索执行两个阶段。
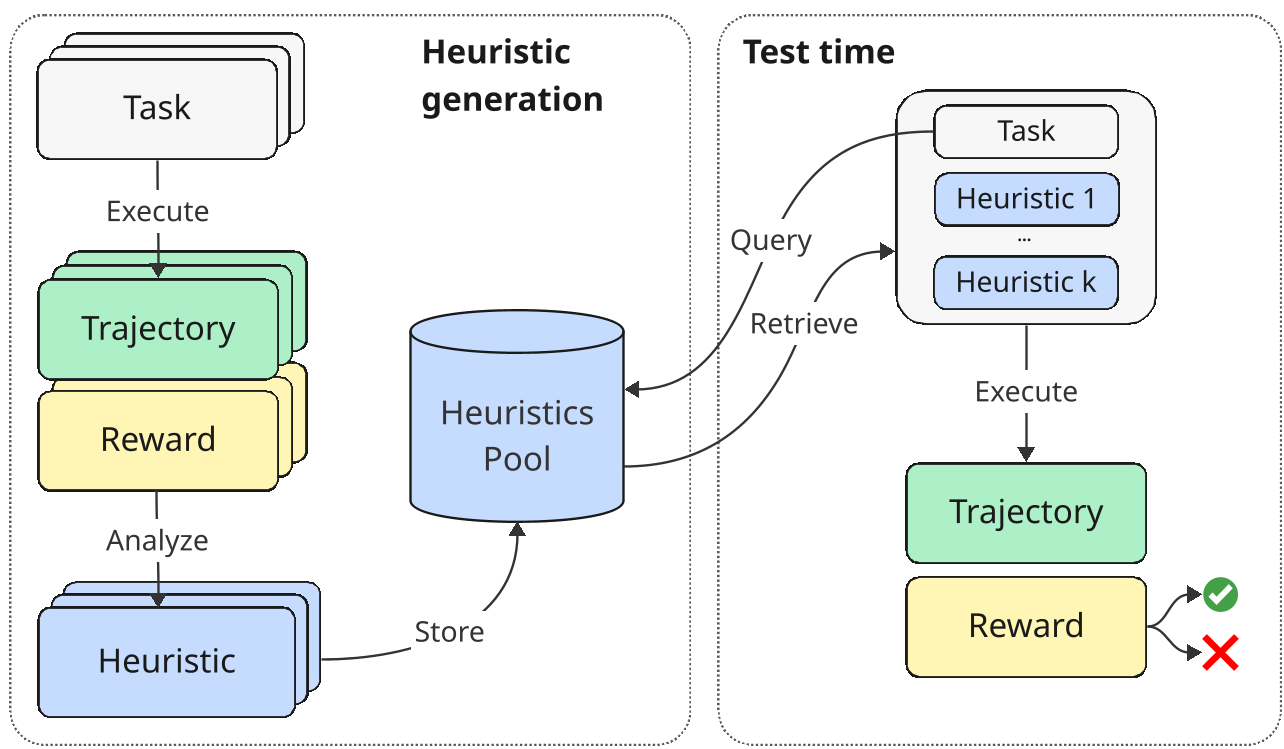
3. 基于 LLM 的精准检索
与传统的 Embedding 向量检索不同,ERL 发现单纯依靠语义相似度是不够的。作者使用 LLM(如 GPT-5.2)作为 Ranker,分析当前任务可能遇到的挑战,从库中选出最具有“教训意义”的 Top-20 准则注入 Prompt。
实验与结果:可靠性的巨大飞跃
ERL 在 Gaia2 这一公认的 Agent 难题集上进行了验证。该基准包含 12 个应用和 101 个工具,极度考验模型的工具调用能力。
SOTA 对比
在执行(Execution)和搜索(Search)任务中,ERL 全面超越了基线和竞争对手。
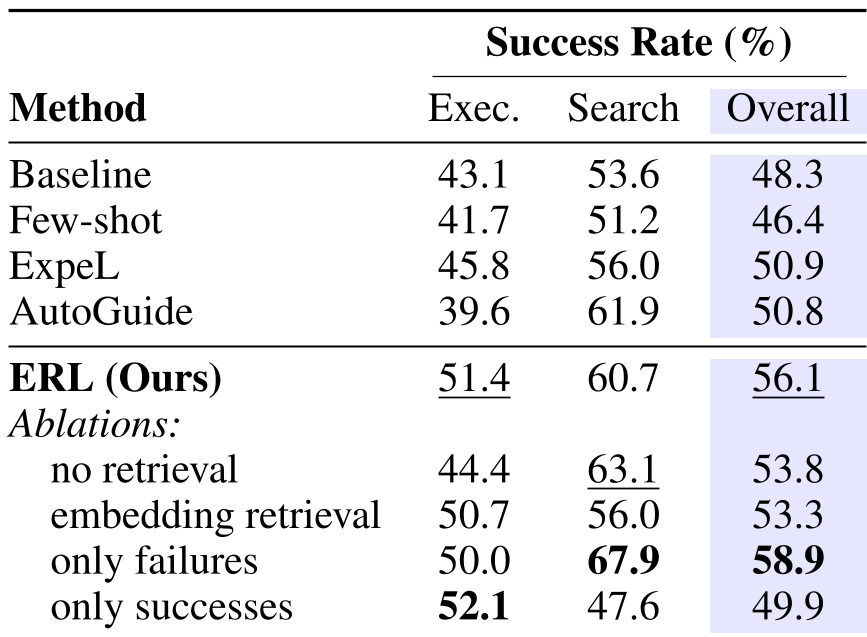
核心洞察:失败 vs. 成功
论文提出了一个非常有意思的视角:
- 学习失败经验:对“搜索类”任务提升巨大。失败的教训像是一种“负约束”,告诉 Agent 哪些坑不要踩。
- 学习成功经验:对“执行类”任务更有帮助。成功的案例提供了清晰的“成功模板”,强化了正确的操作序列。
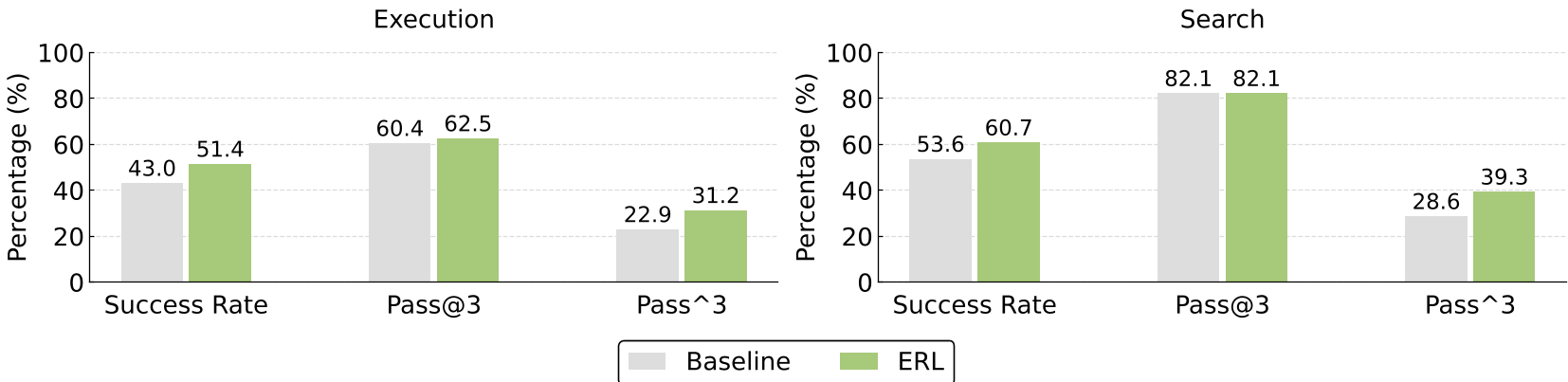
稳定性分析 (Pass^3)
ERL 最令人印象深刻的提升在于 pass^3 指标(即连续三次尝试都必须成功)。如图 3 所示,ERL 显著增强了 Agent 的可靠性,这意味着它不再是“偶尔撞大运”,而是真正掌握了环境的逻辑。
深度思考:启发式准则的“降维打击”
实验还对比了直接提供原始轨迹(Few-shot)的效果。结果证明,即使在同样的 Token 预算下,启发式准则的泛化性能远超原始轨迹。这说明对经验的“二次加工”和“抽象化”是智能进化的关键。Agent 不应该只是复读机,而应该成为能够总结方法论的思考者。
总结与未来展望
ERL 提供了一个简单且高效的框架,使得 LLM Agent 可以在不更新模型参数的情况下,通过“吃一堑长一智”实现性能增长。
局限性:随着经验库的无限增长,如何处理冲突的准则(Conflicting Guidelines)以及如何维持高昂的检索成本将是未来的挑战。
启示:对于开发者而言,建立一个环境相关的“避坑指南”数据库,并动态喂给 Agent,可能比单纯追求更强的基础模型更有效。