F2LLM-v2 is a new family of multilingual embedding models ranging from 80M to 14B parameters, supporting over 200 languages. It utilizes a two-stage training pipeline with Matryoshka learning and knowledge distillation, achieving SOTA results across 11 MTEB benchmarks, including high-resource and underserved languages.
TL;DR
F2LLM-v2 is a comprehensive suite of 8 embedding models (80M to 14B parameters) that shatters the performance-to-size barrier. By training on a custom 60M multilingual dataset and employing Matryoshka learning and Knowledge Distillation, it achieves SOTA results on 11 MTEB leaderboards. Unlike many "black-box" industry models, F2LLM-v2 releases its full training recipe, weights, and data to promote global AI equity.
Moving Beyond "English-Only" AI
The AI community has a hidden problem: most "multilingual" models are actually English models with a thin veneer of other languages. High-resource languages like English and Chinese dominate training sets, leaving 200+ other languages as second-class citizens.
Furthermore, as embedding models shift from BERT-style encoders to massive LLM-based decoders, they have become too heavy for edge deployment. The researchers behind F2LLM-v2 from Ant Group and SJTU aimed to solve two things: Linguistic Inclusivity (supporting the "long tail" of languages) and Computational Inclusivity (making models run on your phone without sacrificing accuracy).
Methodology: The "Secret Sauce" of Compact Performance
The F2LLM-v2 pipeline is built on three pillars:
1. The Global Corpus (60M Samples)
The authors moved away from benchmark-chasing and instead focused on real-world data availability. Their dataset covers 282 natural languages and 40+ programming languages.
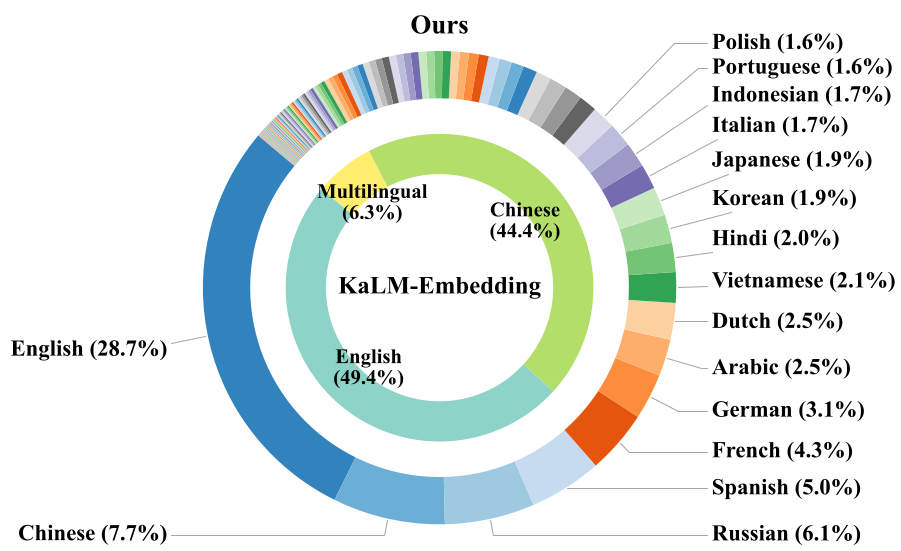 Figure: Comparison showing F2LLM-v2's significantly broader language coverage compared to existing open datasets like KaLM.
Figure: Comparison showing F2LLM-v2's significantly broader language coverage compared to existing open datasets like KaLM.
2. Matryoshka Representation Learning (MRL)
MRL allows a single model to output embeddings that can be "truncated." You can use the full 1024 dimensions for maximum accuracy, or just the first 64 dimensions for lightning-fast retrieval with minimal performance loss.
3. Pruning + Knowledge Distillation
To create the 80M, 160M, and 330M models, the team didn't just train from scratch. They pruned the 0.6B Qwen3-based model and used the larger models as "teachers." By minimizing the Mean Squared Error (MSE) between the teacher's and student's output vectors, the small models "inherit" the reasoning capabilities of the 14B giant.

Experimental Results: SOTA Across the Board
F2LLM-v2 was evaluated on 17 MTEB benchmarks (430 tasks). The results are striking:
- 14B Model: Swept the benchmarks, ranking 1st in 11 categories (Code, INDIC, Persian, etc.).
- Compact Models: The 330M model outperformed EmbeddingGemma (size-agnostic comparison) on almost all language-specific tasks.
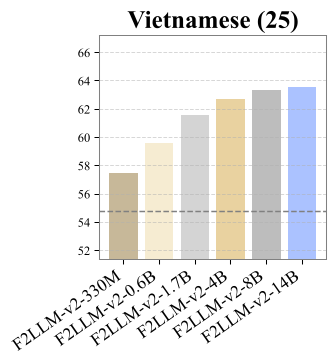 Figure: F2LLM-v2 dominating across various language-specific benchmarks, often surpassing previous SOTA by a wide margin.
Figure: F2LLM-v2 dominating across various language-specific benchmarks, often surpassing previous SOTA by a wide margin.
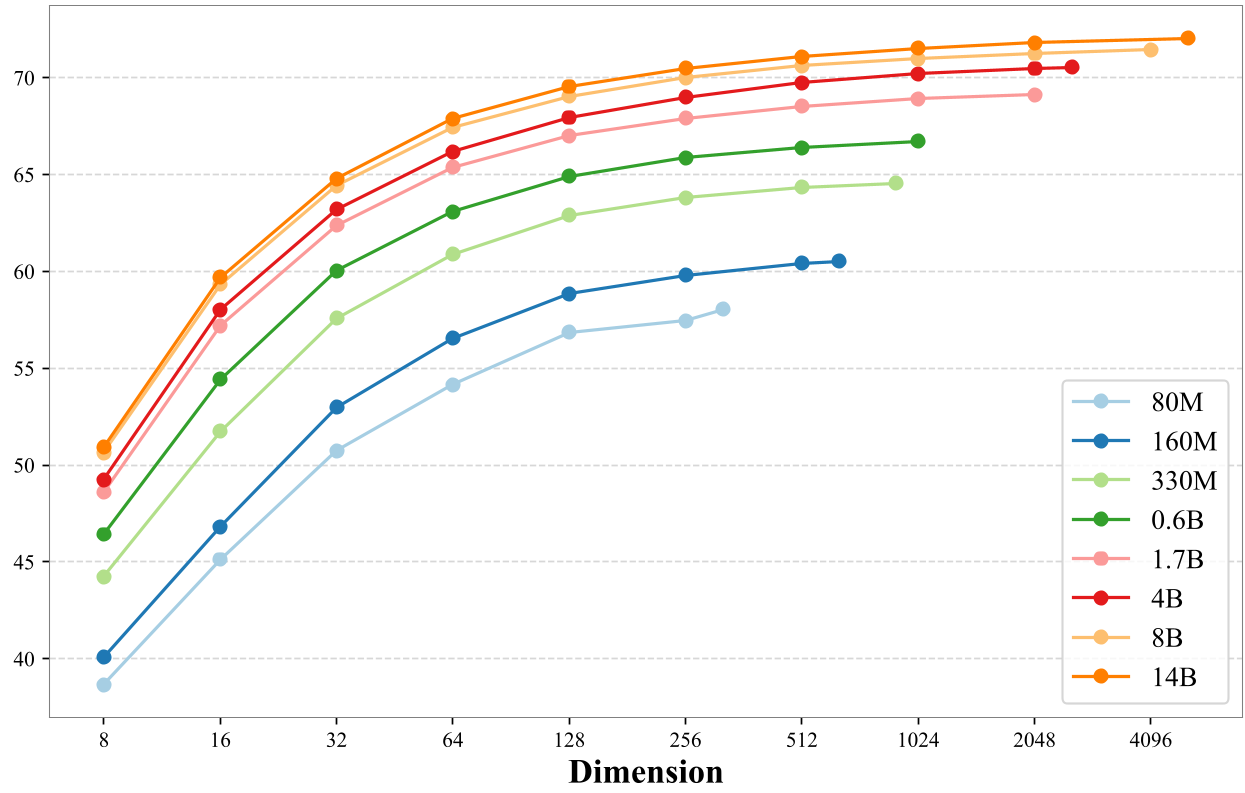
The Power of Truncation
As shown in the ablation studies, MRL works beautifully. The 14B model at just 128 dimensions still beats many smaller models at their full size. This allows for a "Dynamic Retrieval" strategy—use 64 dims for the first pass and 5120 dims for the final re-ranking.
Critical Insights & Conclusion
The real value of F2LLM-v2 isn't just the Benchmark scores; it's the Open-Source Recipe. By releasing intermediate checkpoints and the data curation strategy, the authors provide a blueprint for others to build inclusive AI.
Takeaway: If you are building a RAG (Retrieval-Augmented Generation) system for a global audience, F2LLM-v2 is currently the most versatile and efficient choice. It proves that with the right distillation strategy, you don't need 100B parameters to understand the nuances of Polish or Vietnamese.
Limitations: While performant, the distillation process still requires heavy compute for the "teacher" phase, and the 14B model remains heavy for standard consumer GPUs. However, for 99% of use cases, the 1.7B or 0.6B variants offer the best "Goldilocks" zone of speed and accuracy.