Fast-dVLA is a novel acceleration framework for Discrete Diffusion Vision-Language-Action (dVLA) models that achieves 2.8x–4.1x speedups, enabling real-time 30Hz robotic control. It introduces a block-wise diffusion strategy and attention mechanism to allow Key-Value (KV) cache reuse and inter-block parallel decoding.
TL;DR
Fast-dVLA bridges the gap between the high-quality sequence generation of discrete diffusion models and the strict real-time requirements of robotics. By rethinking the attention pattern and introducing a pipelined decoding strategy, it achieves a 4.1x speedup, hitting the 30Hz standard for real-world deployment without losing the "reasoning" capabilities of SOTA VLA models.
Problem & Motivation: The Bidirectional Bottleneck
Discrete Diffusion VLAs (dVLAs) have recently emerged as powerful competitors to standard Autoregressive (AR) models. They denoise tokens in parallel and better preserve pretrained VLM knowledge. However, they harbor a "hidden tax": Bidirectional Attention.
In a standard dVLA, every token attends to every other token. When you move from denoising step $t$ to $t-1$, the underlying representations change globally. This makes the KV Cache—the secret sauce that makes LLMs fast—completely useless. Consequently, dVLAs are often stuck at sub-real-time frequencies, making them "think" too slowly for a robot needing to catch a moving object on a conveyor belt.
The authors made a key observation: even with bidirectional masks, dVLAs naturally exhibit a Left-to-Right decoding tendency (as shown in the heatmap below). This suggests that we can enforce a block-wise causal structure without destroying the model's performance.
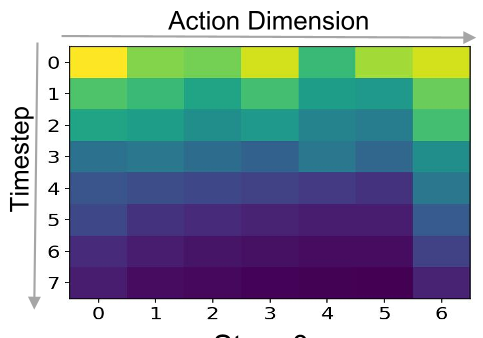
Methodology: Block-Wise Acceleration
Fast-dVLA restructures the denoising process through three core innovations:
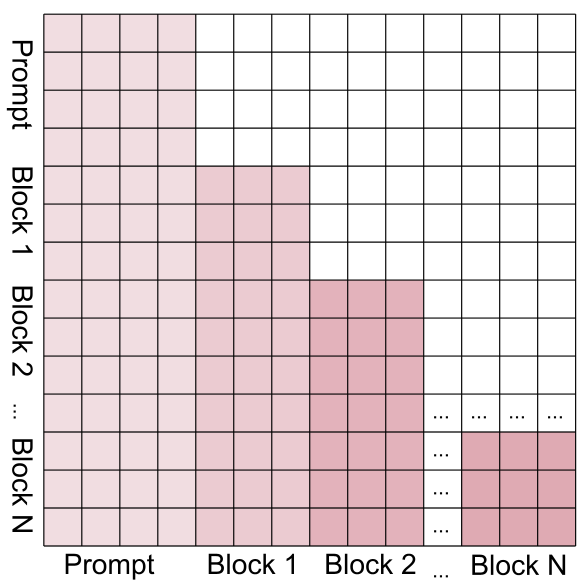
1. Block-wise Attention & KV Cache
Instead of full bidirectionality, the model uses a block-causal mask. Tokens within a block can see each other and all preceding blocks, but they cannot see the "future." Once a block is fully denoised, its KV states are "locked" and cached.
2. Diffusion Forcing for Parallelism
The method doesn't just wait for Block A to finish before starting Block B. It uses monotonically increasing noise levels. While Block 1 is almost clean (low $t$), Block 2 is partially masked, and Block 3 is mostly noise. This allows the model to refine multiple temporal segments of an action sequence simultaneously.
3. Asymmetric Distillation
Training a new architecture from scratch is expensive. The authors used Asymmetric Distillation, where a student (with the new block-mask) learns from a pretrained bidirectional teacher. This allows the model to converge 10x faster than training from scratch.
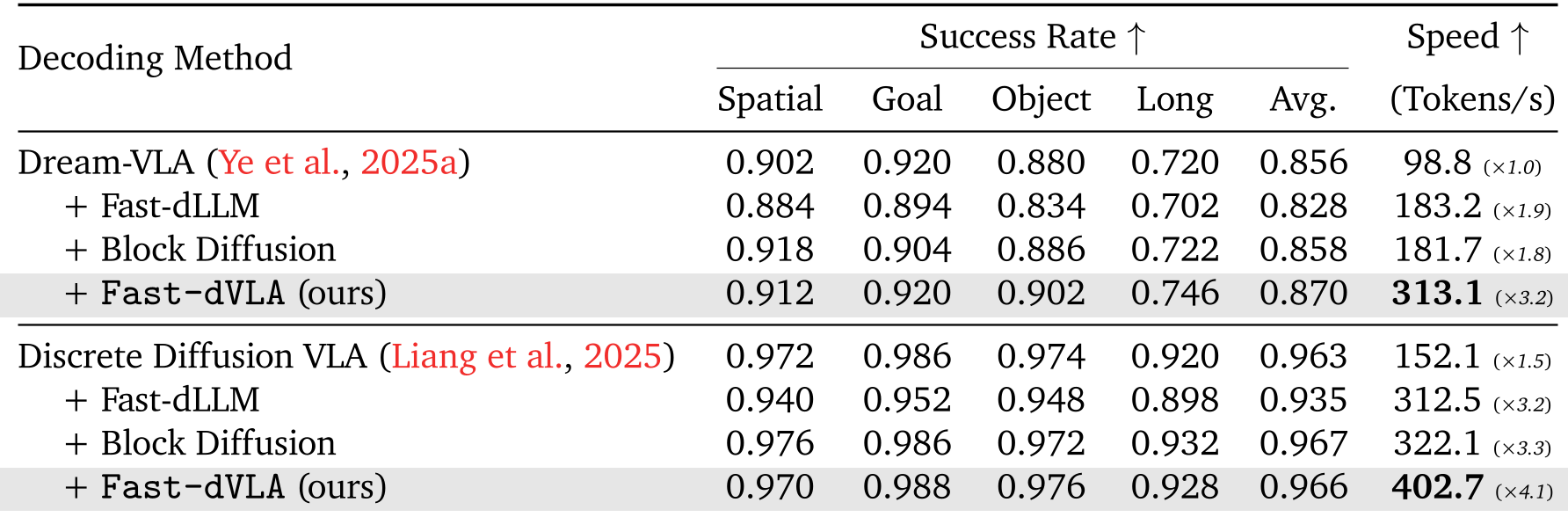
Experiments: Speed Meets Precision
The results are striking across both simulation (CALVIN, LIBERO) and real-world testing.
- Inference Throughput: On the LIBERO benchmark, Fast-dVLA achieved 402.7 tokens/s, compared to the baseline's 152.1.
- Success Rates: Remarkably, the success rate actually improved in some cases (e.g., from 96.3% to 96.6% on LIBERO Long), likely due to the improved temporal consistency enforced by the block-causal structure.
Real-World "Conveyor Picking"
In a high-stakes real-world task involving picking blocks from a moving belt, the 30Hz execution frequency of Fast-dVLA allowed it to achieve nearly double the efficiency of traditional dVLAs.
Critical Analysis & Conclusion
Takeaway
Fast-dVLA proves that we don't need to choose between the "parallel wisdom" of diffusion and the "speed efficiency" of autoregressive caching. By aligning the block size with the action dimensionality (e.g., 7 tokens for a 7-DOF arm), we can maintain physical intuition in the latent space.
Limitations
The performance is sensitive to the confidence threshold ($ au_{conf}$). If set too low to chase speed, the robot may take "radical" but inaccurate actions. Finding the optimal balance (the authors suggest 0.5) is critical for safety-critical tasks.
Future Work
This framework is ripe for extension into unified world models, where future video frames and actions are denoised in the same pipelined stream, potentially allowing a robot to "see" and "act" 4x faster than current SOTA.