Fast-WAM is a real-time World Action Model (WAM) for embodied control that introduces a "training-only" video modeling paradigm. By repurposing a pretrained video Diffusion Transformer as a single-pass latent encoder, it achieves state-of-the-art results on LIBERO and RoboTwin benchmarks without explicit test-time future imagination.
TL;DR
World Action Models (WAMs) have traditionally been synonymous with "future imagination"—generating videos of future states before acting. Fast-WAM challenges this status quo. By disentangling the training objective from the inference process, the authors prove that the "foresight" isn't what matters at test time; the "knowledge" gained during training is. Fast-WAM achieves SOTA performance on major robotics benchmarks while running 4x faster than traditional WAMs.
The "Imagination" Tax: Why Standard WAMs are Slow
In the quest for general-purpose embodied agents, WAMs emerged as a powerful alternative to standard Vision-Language-Action (VLA) models. The intuition was simple: if a robot can predict what the world should look like after an action, it understands physical dynamics.
However, this intuition forced models into an imagine-then-execute bottleneck. To act, the model had to spend precious seconds (often >800ms) denoising a future video. This is the "Imagination Tax"—a latency that makes real-world, high-frequency control nearly impossible.
The Core Insight: Representation vs. Foresight
The authors of Fast-WAM asked a profound question: Is the benefit of WAMs coming from the predicted video at test time, or from the act of learning to predict videos during training?
If the value lies in Representation Learning, we can co-train with video prediction but skip the actual video generation at test time.
Methodology: Fast-WAM Architecture
Fast-WAM utilizes a Mixture-of-Transformer (MoT) architecture based on the Wan2.2-5B video DiT.
1. Training with Decoupled Attention
The model uses a structured attention mask during training:
- Future video tokens can see the current frame.
- Action tokens can see the current frame.
- Crucially, action tokens cannot see the future video tokens. This ensures that the action expert learns to rely on the latent features of the encoder shaped by video modeling, not the explicit future frames.
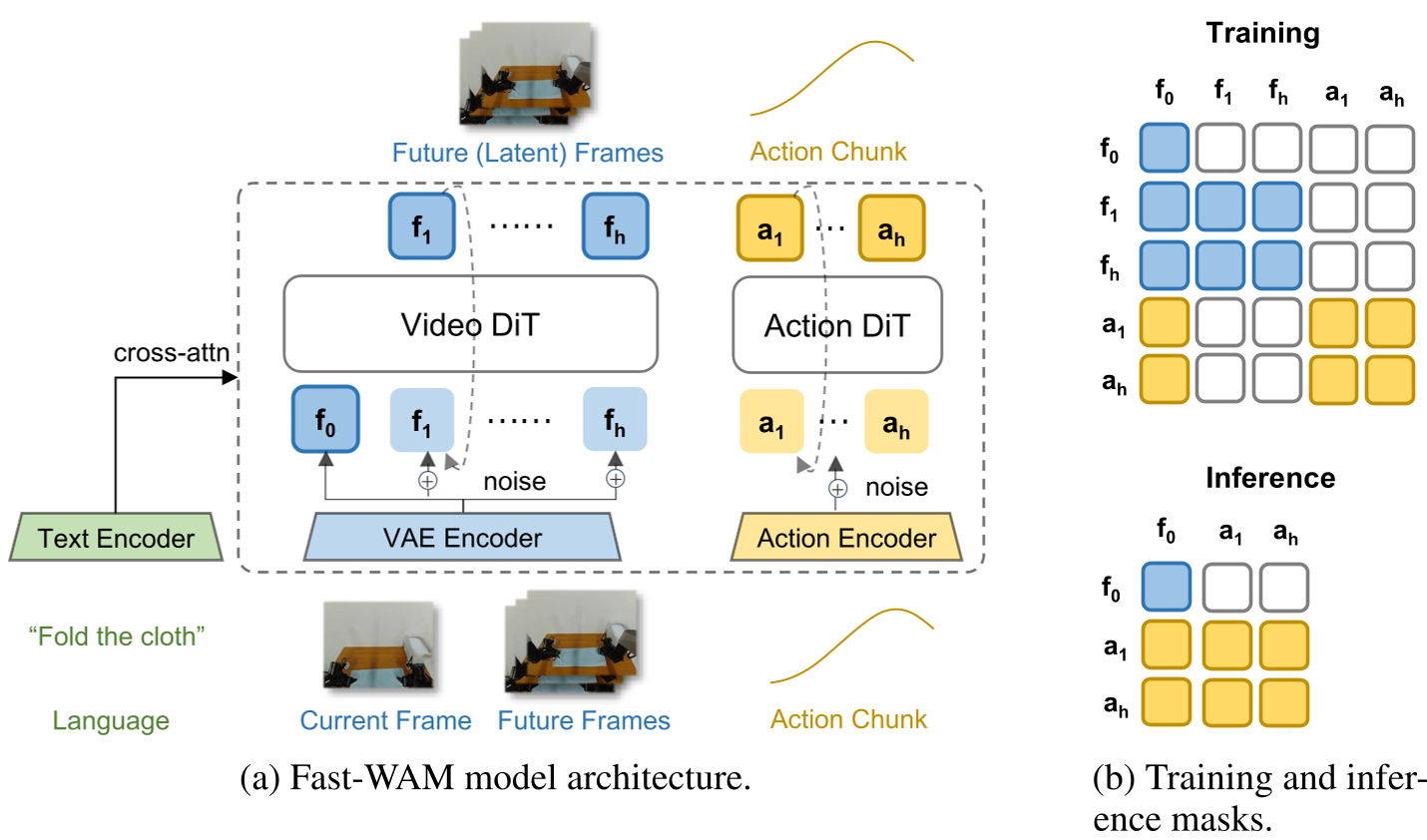 Figure: The architecture uses a shared video DiT and an action expert, coordinated by a structured mask to prevent information leakage.
Figure: The architecture uses a shared video DiT and an action expert, coordinated by a structured mask to prevent information leakage.
2. Single-Pass Inference
At inference time, the future video branch is completely discarded. The video backbone acts as a "World Encoder," processing the current observation in one single forward pass (190ms).
Experimental Proof: The "Aha!" Moment
The team conducted a controlled "battle" between different WAM paradigms across simulation (LIBERO, RoboTwin) and real-world tasks (Towel Folding).
SOTA Comparison on RoboTwin
On the RoboTwin benchmark, Fast-WAM (91.8% success) outperformed even pretrained models like Motus (87.8%). This demonstrates incredible data efficiency—achieving SOTA without expensive embodied pretraining.
 Figure: Detailed results on RoboTwin show Fast-WAM dominating across diverse tasks while maintaining high speed.
Figure: Detailed results on RoboTwin show Fast-WAM dominating across diverse tasks while maintaining high speed.
The Disentanglement Result
The most critical finding comes from the ablation studies:
- Fast-WAM (No test-time imagination): 91.8% Success.
- Fast-WAM-Joint (With test-time imagination): 90.6% Success.
- Fast-WAM (No video co-training): 83.8% Success.
The conclusion is undeniable: Removing the training objective (video co-training) hurts performance drastically, while removing the actual "imagination" at test time doesn't hurt at all.
Real-World Impact: Towel Folding
In real-world tests involving deformable objects (towels), Fast-WAM variants with video co-training significantly outperformed standard VLA models. It combined the precision of a world-aware model with the real-time responsiveness of a direct policy.
Summary & Outlook
Fast-WAM marks a shift in how we think about "World Models." It suggests that we should treat video prediction as a luxurious pretraining or auxiliary task that provides an inductive bias for physics, rather than a prerequisite for every single step of inference.
Takeaway: Future WAM research should likely focus on scaling the complexity of the world-modeling objective during training while keeping the inference path as lean and "VLA-like" as possible.
Limitations: While effective for manipulation, it remains to be seen if extremely high-level reasoning tasks (where "mental simulation" of multi-step plans is required) might still benefit from explicit imagination.