本文提出了 SMC-SD(Sequential Monte Carlo Speculative Decoding),一种利用串行蒙特卡洛采样加速 LLM 推理的近似方案。该方法通过重要性重采样(Importance Resampling)替代传统投机采样中的拒绝采样,在保持高精度的同时,显著提升了推理吞吐量。
TL;DR
大模型的推理速度一直受限于算力无法充分释放。传统的投机采样(Speculative Decoding)虽然能提速,但一旦草稿模型“猜错”,就会面临严重的性能回退。SMC-SD (Sequential Monte Carlo Speculative Decoding) 彻底改变了游戏规则:它不再简单地拒绝错误的 token,而是维护一组“粒子”(候选序列),通过重要性重采样来筛选最优路径。这种方法让推理速度提升了 5.2 倍,而精度损失几乎可以忽略不计。
痛点深挖:为什么投机采样还不够快?
自回归生成(Autoregressive Generation)本质上是串行的。现有的投机采样方案(如 Leviathan 等人提出的方法)试图通过“先猜后验”来打破瓶颈:
- 草稿模型生成 个 token。
- 目标模型一次性验证这 个 token。
致命伤:拒绝采样(Rejection Sampling)。只要有一个 token 没对上,后续所有努力全部白费,KV Cache 必须回滚(Rollback)。这意味着吞吐量是随机且不稳定的,对硬件利用率极低。
方法论详解:粒子滤波与重要性采样的降维打击
SMC-SD 的核心直觉在于:既然 GPU 的计算资源在加载权重时是闲置的,为什么不让草稿模型多猜几个版本,然后让目标模型通过权重筛选,而不是简单的二选一?
1. 架构解析
SMC-SD 将推理过程建模为一个粒子滤波(Particle Filtering)任务。在每一轮中:
- Extend(扩展):草稿模型并行地为 个独立粒子(粒子即序列路径)生成 个草稿 tokens。
- Reweight(重赋权):目标模型对这 个 tokens 进行打分,计算每个粒子的重要性权重(基于目标分布与草稿分布的差异)。
- Resample(重采样):根据权重对比,保留表现优异的选择(复制),淘汰概率过低的路径。
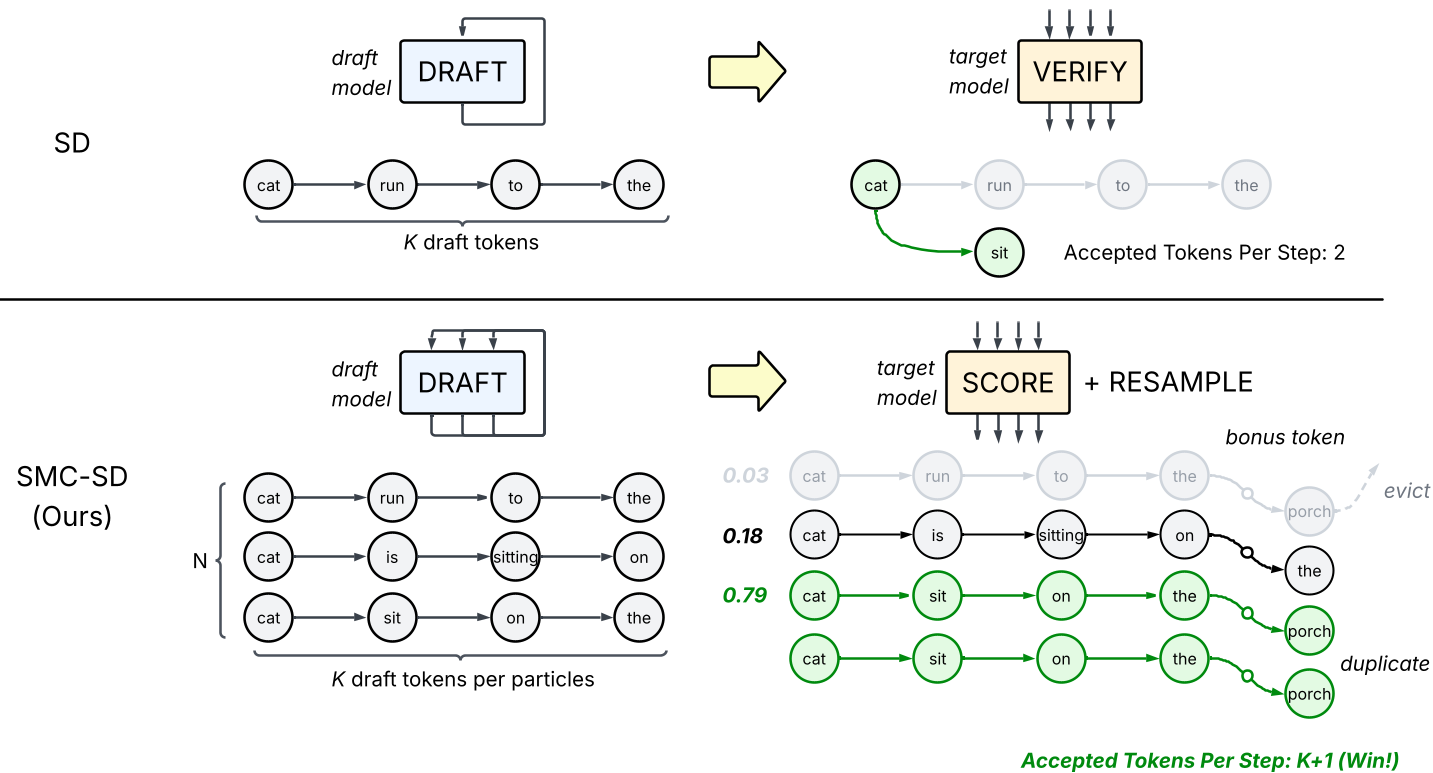 图注:上方为标准投机采样,一旦失败即截断;下方为 SMC-SD,通过粒子群体维持多路径生成。
图注:上方为标准投机采样,一旦失败即截断;下方为 SMC-SD,通过粒子群体维持多路径生成。
2. 硬件加速的物理直觉
作者提出了一个非常深刻的观察:在内存带宽限制(Memory-bound)的 regime 中,多增加几个粒子()几乎是“免费”的。因为加载一次 70B 模型权重的开销远大于处理几个额外 token 的计算开销。SMC-SD 通过增加算力强度(Arithmetic Intensity),填充了内存带宽造成的闲置气泡。
实验与结果
在 Llama 1B 70B 以及 Qwen 等模型上的实验结果显示,SMC-SD 达到了惊人的性能表现:
- 极致提速:在 4 张 H100 上,相比自回归解码提速 5.2x,相比 SGLang 优化的投机采样提速 2.36x。
- 精度保真:在 GSM8K(数学推理)、AlpacaEval(指令遵循)和 DS1000(代码生成)等严苛测试中,其准确率与原始目标模型相比,偏差通常在 3% 以内。
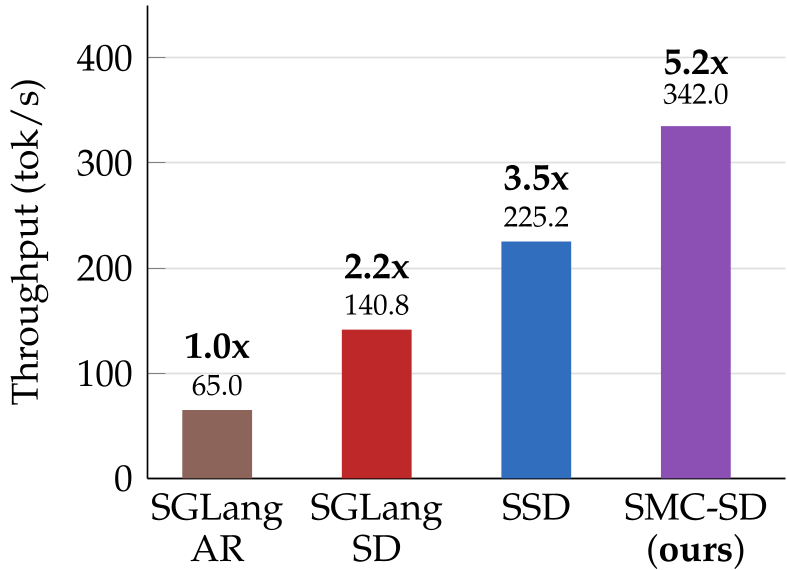 图注:SMC-SD 在不同数据集上的吞吐量表现显著优于 SOTA 方案 SGLang 和 SSD。
图注:SMC-SD 在不同数据集上的吞吐量表现显著优于 SOTA 方案 SGLang 和 SSD。
消融与优化:RadixAttention 的妙用
为了处理粒子重采样带来的 KV Cache 管理难题,作者对 SGLang 推理引擎进行了深度改造。利用 RadixAttention 和指针交换(Pointer Exchange),实现了 级别的粒子复制,减少了 72.3% 的 KV Cache 内存增长。
深度洞察与总结
Takeaway: SMC-SD 的成功标志着 LLM 推理从“单纯追求数学精确”向“统计效率最优”的范式转变。
局限性:
- 它本质上是一种近似采样,对于需要 100% 还原 Token 分布的极端场景(如极低 Temperature 采样)可能存在微小偏差。
- 和 的参数选择需要根据具体的 GPU 架构(如内存带宽/FLOPS 比率)进行微调。
未来展望: SMC-SD 提供的不仅是速度。由于其重要性采样的框架,它可以无缝对接 受限生成(Constrained Generation) 或 奖励加权采样(Reward-weighted Decoding)。这意味着未来的 LLM 不仅推理更快,而且可以在生成过程中实时地被引导至更符合人类偏好、更符合语法逻辑的方向。