The paper introduces FASTER (Fast Action Sampling for ImmediaTE Reaction), a plug-and-play acceleration framework for flow-based Vision-Language-Action (VLA) models. It achieves a 10x reduction in the denoising latency for immediate actions by using a Horizon-Aware Schedule, enabling real-time responsiveness in dynamic tasks like table tennis without architectural changes or extra training.
TL;DR
Deploying Vision-Language-Action (VLA) models in the physical world often hits a wall: latency. While many methods focus on making robot motions "smooth," they ignore how fast the robot starts moving once an event occurs. FASTER introduces a Horizon-Aware Schedule that allows flow-based VLAs (like ) to generate the immediate next action in just one sampling step instead of ten, achieving a 10x acceleration for the first action and enabling high-speed tasks like table tennis on consumer GPUs.
The Perception-Execution Gap: Why Smoothness Isn't Readiness
Current VLA deployment typically uses "Action Chunking"—the model predicts a sequence of future actions (a "chunk") at once. Even with asynchronous inference (where the robot calculates the next chunk while moving), there is a fundamental bottleneck: the Constant Timestep Schedule.
Standard models require the entire multi-step denoising process (e.g., 10 iterations of an Euler solver) to finish before any action is sent to the robot. This creates a high Time to First Action (TTFA). In dynamic environments, if a ball is flying toward a robot, waiting 300ms for a "perfect chunk" means the robot has already missed its window to react.
The Core Insight: Near-Term Actions are "Straight"
The authors conducted a pilot study on the "straightness" of flow paths in VLA models. They discovered a crucial physical intuition: near-term actions are more certain. Because the immediate future is tightly constrained by the current observation, the mathematical "flow" from noise to the action is nearly a straight line.
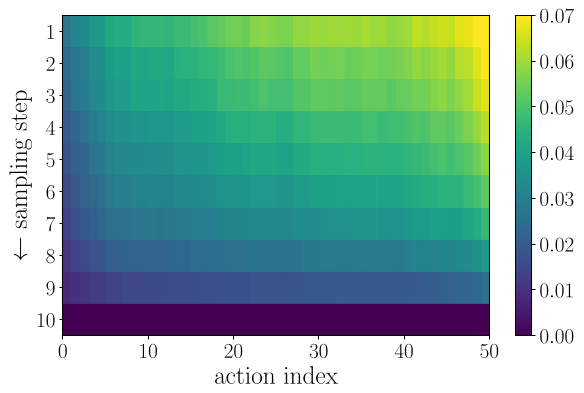 Fig 1: Quantitative evidence that early actions follow straighter paths and can be estimated accurately with fewer steps.
Fig 1: Quantitative evidence that early actions follow straighter paths and can be estimated accurately with fewer steps.
Methodology: Horizon-Aware Scheduling (HAS)
Instead of giving every action in the 50-frame chunk the same 10 steps, FASTER uses a Horizon-Aware Schedule (HAS).
- Index-Dependent Timesteps: The denoising timestep is now a vector. The first action reaches "completion" (clean state) much earlier in the sampling process than the 50th action.
- Streaming & Early Stopping: Actions are dispatched to the robot via a streaming interface the moment they are ready. If the robot only needs the next 4 actions to maintain continuity, the server can early-stop the AE (Action Expert) iterations once those 4 are finalized, skipping the computation for the distant future.
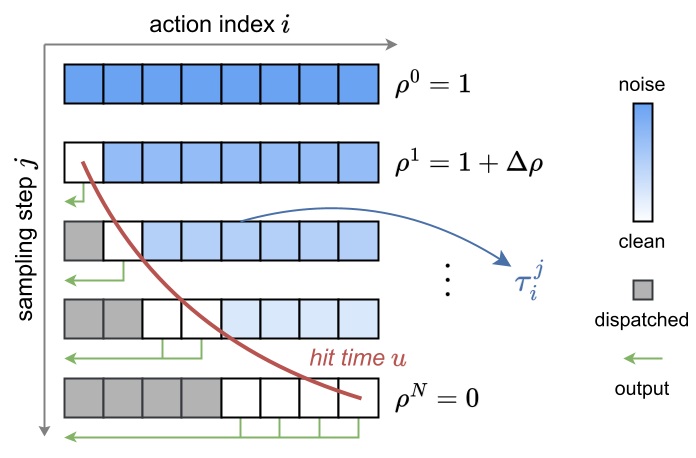 Fig 2: Baseline (top) requires N steps for all actions. FASTER (bottom) completes early actions in minimal steps while continuing to refine the future.
Fig 2: Baseline (top) requires N steps for all actions. FASTER (bottom) completes early actions in minimal steps while continuing to refine the future.
Real-World Performance: Dynamic Table Tennis
The true test of FASTER was a table tennis task where the robot must hit a fast-moving ball.
- Synchronous Inference: Completly failed (too slow).
- Naive Asynchronous: Often missed because the racket didn't start moving early enough to build velocity.
- FASTER: On both RTX 4090 and the budget RTX 4060, FASTER allowed the robot to initiate its swing early, resulting in powerful and accurate hits.
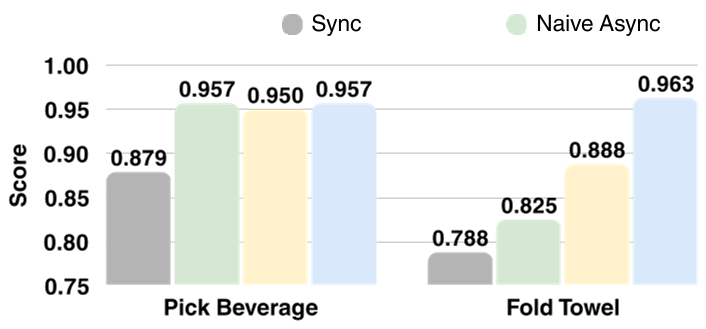 Fig 3: FASTER consistently achieves higher completion scores across various tasks and hardware, particularly on resource-constrained edge devices.
Fig 3: FASTER consistently achieves higher completion scores across various tasks and hardware, particularly on resource-constrained edge devices.
Conclusion & Critical Analysis
FASTER is a "plug-and-play" solution that addresses the often-ignored metric of Response Time in VLAs.
- Pros: No extra training parameters, no architecture change, and significant gains on consumer hardware.
- Cons: While near-term actions are stable, very aggressive one-step sampling can marginally reduce the quality of long-horizon trajectories in highly complex, non-linear sequences.
Ultimately, this work suggests that for embodied AI, a fast, "good enough" reaction is often better than a slow, "perfect" prediction. It paves the way for generalist robot models to operate on the edge without needing server farms to hit a ping-pong ball.