本文提出了 FASTER,一种针对基于 Flow Matching 的视觉-语言-动作模型 (VLA) 的实时加速方案。通过引入“地平线感知调度”(Horizon-Aware Schedule, HAS) 和流式客户端-服务器架构,该方法实现了首个动作的单步采样生成,在保持长轨迹质量的同时将反应延迟降低了至多 10 倍。
TL;DR
在自动驾驶或机器人协作中,反应延迟(Reaction Latency)往往决定了部署的成败。香港大学的研究团队提出 FASTER (Fast Action Sampling for ImmediaTE Reaction),通过一个简单的“时间步调度策略”和“流式传输管道”,让基于 Flow Matching 的 VLA 模型能够以 10 倍于以往的速度 响应环境变化。该方法无需重新设计架构,在 RTX 4060 等平民卡上也能让机器人玩起乒乓球。
1. 痛点:平滑但不敏捷的“反应盲区”
目前的 VLA 模型(如 或 X-VLA)普遍采用 Action Chunking(动作分块)。虽然异步推理解决了动作间的停顿问题,使动作看起来“平滑”,但却带来了一个隐形的“盲区”:模型必须跑完完整的 步迭代(通常 )才能生成第一个动作。
作者指出:反应时间 (Reaction Time) 应该是一个受推理频率和延迟共同决定的随机变量。在物理世界动态变化时,这种“必须等所有采样跑完”的机制成为了 reactivity 的死穴。
2. 核心直觉:近处的动作其实更简单
研究团队通过对 Flow Matching 轨迹的 Straightness (直线性) 实验发现(如下图所示):动作块中靠前的帧(第 1-10 帧)其预测路径更直,偏离目标动作的方差更小。
这意味着:近期动作只需要更少的去噪步数就能达到足够的精度。
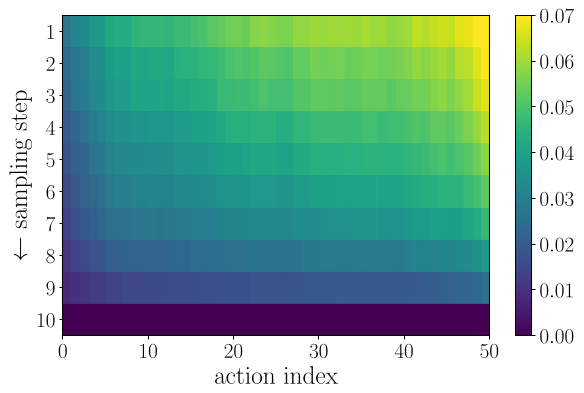 上图展示了动作索引越靠近当前时刻,其预测路径越接近线性。
上图展示了动作索引越靠近当前时刻,其预测路径越接近线性。
3. 技术解法:Horizon-Aware Schedule (HAS)
FASTER 抛弃了传统的恒定时间步采样,引入了基于地平线的调度器。
- 非对称采样:对于 的即时动作,强制其在第 1 步采样时即达到“收敛状态”(Timestep 趋于 0);对于远期动作,则允许其在后续步骤中缓慢优化。
- 流式接口:服务器不再等整个 Chunk 生成完再发包,而是“产出一个发一个”,让机器人控制器第一时间执行即时动作。
- 早停 (Early Stopping):如果机器人只需要执行前 4 步动作,那么后 6 步采样直接跳过,极大地提高了控制循环频率。
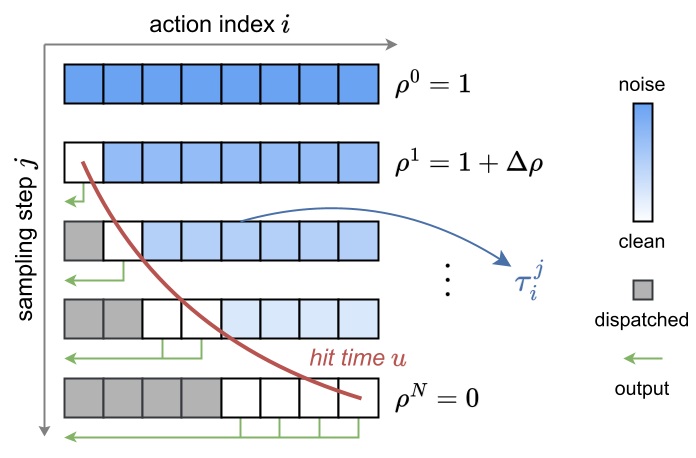 HAS 调度(下)对比恒定调度(上):近期动作更早完成去噪。
HAS 调度(下)对比恒定调度(上):近期动作更早完成去噪。
4. 实验战绩:低算力平台的逆袭
在 RTX 4060 GPU 上,FASTER 取得了惊人的表现:
- TTFA (首个动作时间):相比原始 X-VLA 缩短了 3.09 倍。
- 乒乓球任务:在极高动态的对攻中,FASTER 能够让机器人提前调整球拍角度,而 Sync 或 Naive Async 方法由于反应过慢,球拍往往还未到位球已飞走。
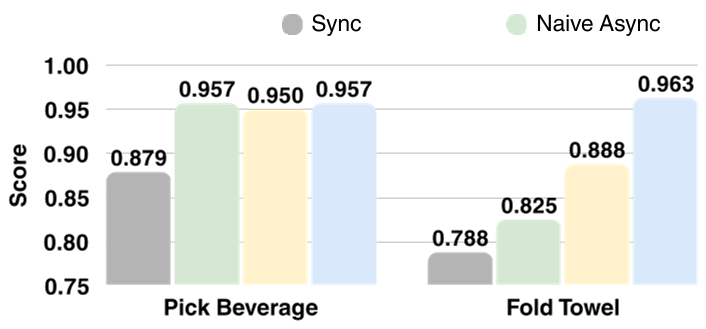 在 4090 和 4060 平台上的乒乓球成功率,FASTER 均大幅领先。
在 4090 和 4060 平台上的乒乓球成功率,FASTER 均大幅领先。
5. 总结与深度洞察
FASTER 的价值在于它识别并利用了 VLA 推理中的时间冗余。
- 即插即用:它不改动 VLM Backbone,只需要在 Fine-tuning 阶段加入 HAS 调度逻辑(算法 1),就能赋予旧模型新能力。
- 权衡之美:虽然极其激进的采样(如 1 步法)在仿真长任务中会有轻微的精度损失,但在现实世界的闭环控制中,反应速度提升带来的增益远超精度损失。
这篇论文向我们启示:Real-time AI 的核心不在于无限制地压榨算力,而在于将算力精准地分配给最迫切的需求(即时反击)。
注:文中各组件如 HAS 需配合 Mixed Schedule 训练以提升鲁棒性。相关代码已在 HKU ACE Robotics 开源。