FinTradeBench is a novel financial reasoning benchmark comprising 1,400 questions that integrate company fundamentals (SEC filings) with trading signals (price/volume dynamics). It evaluates LLMs across three categories—fundamental, trading, and hybrid—revealing a significant performance gap in reasoning over multi-modal financial data.
TL;DR
Financial analysis isn't just about reading a balance sheet; it's about understanding how that balance sheet survives the chaos of the market. FinTradeBench is a new benchmark that exposes a critical weakness in current LLMs: while they are becoming expert "readers" of SEC filings (Fundamentals), they remain dangerously incapable of "calculating" market momentum (Trading Signals) simultaneously. Surprisingly, providing more context via RAG often makes their reasoning worse.
Motivation: The Divergence Problem
In April 2025, Tesla missed its earnings expectations significantly. A model looking only at fundamentals would suggest a "Sell." Yet, the stock rallied 20% on a forward-looking narrative.
Current benchmarks like FinQA or FinanceBench focus on the "What" (the numbers in the table) but ignore the "Why" (the market sentiment). Authors argue that real-world intelligence requires Hybrid Reasoning—the ability to reconcile an accounting "miss" with a technical "buy signal."
Methodology: The Anatomy of FinTradeBench
The researchers constructed a 1,400-question dataset grounded in a decade of NASDAQ-100 data. They categorized questions into:
- F-type: Fundamentals (ROA, Debt-to-Equity).
- T-type: Trading Signals (RSI, MACD, Volatility).
- FT-type: Hybrid (Combined cross-signal reasoning).
The Dual-Track RAG Engine
To test these models fairly, they built a sophisticated RAG pipeline:
- Track A (Textual): Uses hierarchical indexing for SEC filings to preserve narrative coherence.
- Track B (Numerical): Uses temporal alignment for price/volume data.
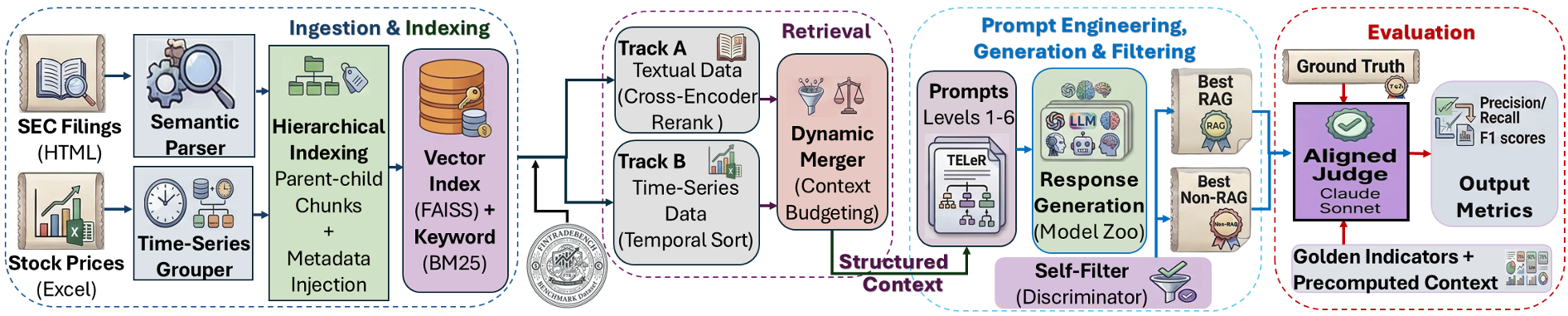 Figure: The Dual-Track Retrieval Engine separates unstructured text from structured time-series data to isolate where LLM reasoning breaks down.
Figure: The Dual-Track Retrieval Engine separates unstructured text from structured time-series data to isolate where LLM reasoning breaks down.
Key Insights: The "Distraction Effect"
The experiment evaluated 14 models, including GPT-5-mini, Gemini, and the DeepSeek-R1 family. The results revealed a startling dichotomy.
1. RAG is a Double-Edged Sword
For Fundamental questions, RAG is a superpower, boosting accuracy by over 20%. But for Trading Signals, RAG often reduced performance. Why? Because LLMs struggle to parse raw "unrolled" numerical tables. Instead of calculating a trend, the models get "distracted" by the density of the numbers and revert to surface-level summarization.
2. Reasoning Models (o1/R1 Style) Win Big
Models with internal Chain-of-Thought (like DeepSeek-R1) saw a massive +55.1% improvement on hybrid questions. This suggests that the ability to "pause and think" is mandatory for financial tasks where signals conflict.
 Table: Accuracy shifts across different model scales. Note the systematic degradation in LLaMA families when RAG is introduced.
Table: Accuracy shifts across different model scales. Note the systematic degradation in LLaMA families when RAG is introduced.
Critical Analysis: The Concept of "Ideal RAG"
The authors introduced a fascinating case study comparing "Standard RAG" to "Ideal RAG."
- Standard RAG: Feeds the model raw price data. Result: Failure.
- Ideal RAG: Feeds the model pre-computed signals (e.g., "The RSI is 60.39"). Result: Success.
This proves that the bottleneck isn't the model's intelligence, but its computational efficiency over raw data. Current LLMs cannot reliably calculate technical indicators on the fly; they need signals served on a silver platter.
Summary & Future Outlook
FinTradeBench highlights that the next frontier for Financial AI isn't finding more text—it's Numerical Fidelity.
Takeaways for Practitioners:
- Don't dump raw ticker data into a prompt. Pre-compute your technical indicators (RSI, Moving Averages) before the LLM sees them.
- Beware the "Summarization Trap." In high-stakes finance, a model that cites perfectly but calculates poorly is more dangerous than no model at all.
- Model Selection Matters: DeepSeek-R1 and Qwen architectures showed much higher resilience to RAG-induced distraction than the LLaMA-3 families.
As we move toward "Agentic RAG," the ability for a model to decide when to use a calculator versus when to read a filing will be the true mark of financial intelligence.