本文提出了 FineCog-Nav,一个受人类认知启发的零样本(Zero-shot)无人机视觉语言导航(VLN)框架。该框架将导航任务分解为语言处理、感知、注意力、记忆、想象、推理和决策等细粒度模块,并在 AerialVLN-Fine 评测集上显著超越了现有 SOTA 方法。
TL;DR
传统的无人机视觉语言导航(UAV VLN)往往受困于长距离规划和模糊指令。本文提出的 FineCog-Nav 另辟蹊径,它不依赖于海量数据训练,而是通过模仿人类的认知地图(Cognitive Maps)创建过程,将导航拆解为感知、注意力、想象、层级记忆等多个细粒度模块,利用大模型组成了功能互补的“数字大脑”。在挑战性的 AerialVLN-Fine 任务中,它大幅提升了执行效率和指令遵循精度。
核心痛点:为什么无人机导航比扫地机器人难得多?
- 维度爆炸:与地面机器人 2D 移动不同,无人机在 3D 连续空间运动,具有更高的自由度。
- 视点多变:第一人称视角(EGOCENTRIC)下的地标(Landmark)特征在不同高度和角度下极不稳固。
- 指令模糊:人类指令(如“飞过那辆黄色卡车后左转”)要求模型具备极强的逻辑推理和状态记忆能力。
- 模型泛化性差:现有的零样本方法对 GPT-4 等超大规模模型高度依赖,但在边缘计算设备常用的中小模型上,性能往往会产生断崖式下跌。
架构解析:模拟人类的“认知闭环”
FineCog-Nav 最核心的贡献在于它将导航任务看作是一个相互依存的认知流动过程。
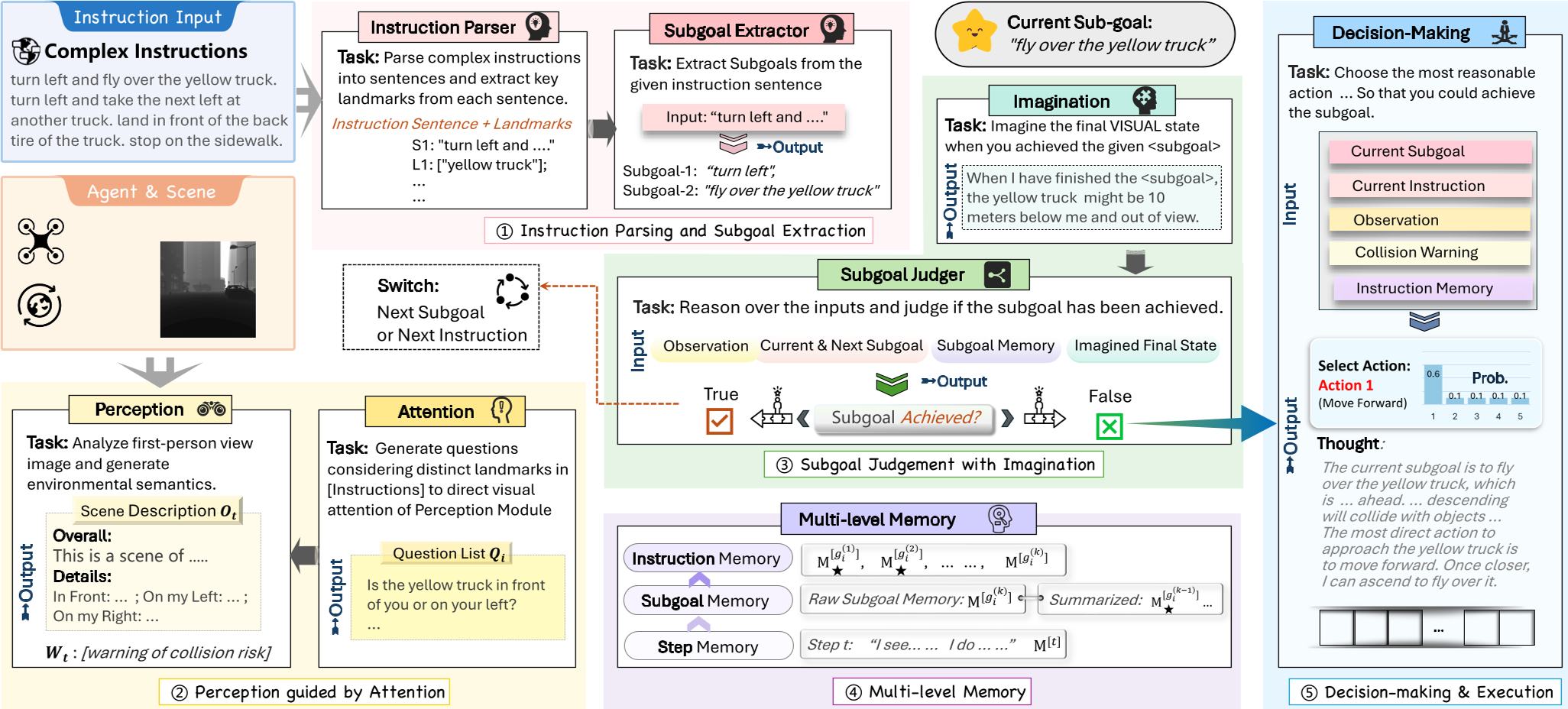
1. 动态子目标提取(Subgoal Extraction)
系统首先将复杂的长指令解析为一系列子目标。这不仅仅是文本分割,而是基于当前观测(Observation)动态调整执行优先级。
2. 注意力引导的感知(Attention-guided Perception)
普通的感知模块会生成海量的环境描述,产生信息过载。FineCog-Nav 引入了 Attention 模块,先根据当前指令预判需要关注的地标,产生针对性提问(如“左边有红色的桥吗?”),从而让感知模块提供精炼且任务相关的语义信息。
3. 层级化记忆机制(Hierarchical Memory)—— 本文的秘密武器
这是该作最精妙的设计。它不再像 BaseModel 那样存储杂乱的历史记录,而是分为三层:
- Step Memory:捕捉每一步的即时动作和视觉。
- Subgoal Memory:当子目标完成时,利用 LLM 将该阶段的 Step 记录进行“记忆巩固(Consolidation)”,转化为精简的阶段总结。
- Instruction Memory:汇总所有子目标的完成情况,为长期规划提供高内聚的上下文。
4. 想象驱动的判定(Imagination Module)
系统会“想象”完成子目标后应该看到的视觉状态(如“我预期下个阶段会看到卡车在中心位置”),并将其作为参考物(Reference)来判定子目标是否真正达成。
实验战绩:全方位的卓越表现
作者不仅提出了框架,还重构了 AerialVLN-Fine 数据集,纠正了原版数据中的指令错位和碰撞异常。
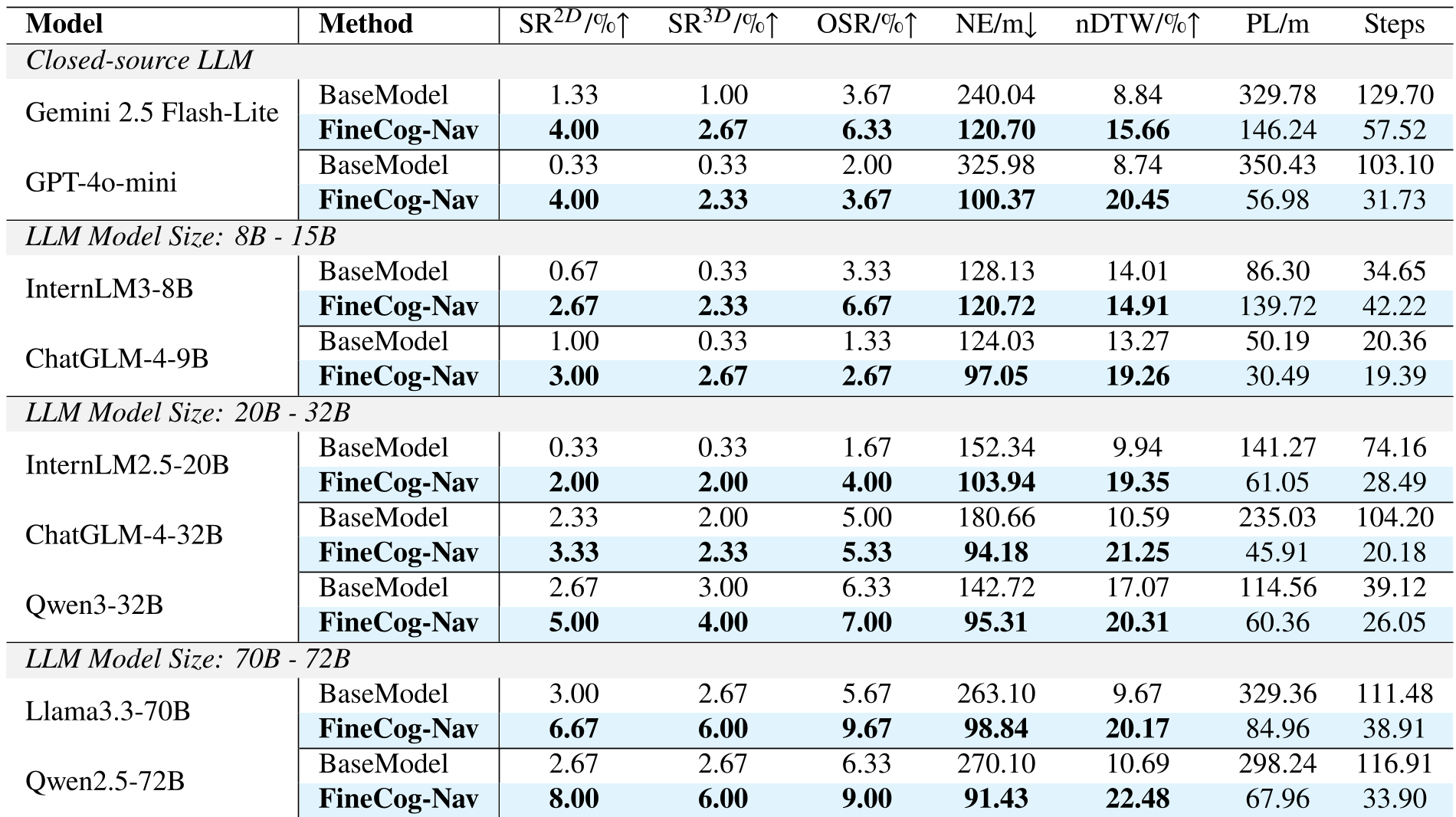
关键结论:
- 跨规模性能领先:无论使用 8B、32B 还是 72B 的基础模型,FineCog-Nav 始终优于 BaseModel。
- 极高的稳定性:在消融实验中,若移除“层级记忆”模块,模型表现下降最剧烈,证明了结构化上下文在长途导航中的决定性作用。
- 真实世界潜力:作者在 RoboMaster TT 无人机上进行了初步部署,验证了算法在现实复杂环境中的可行性。
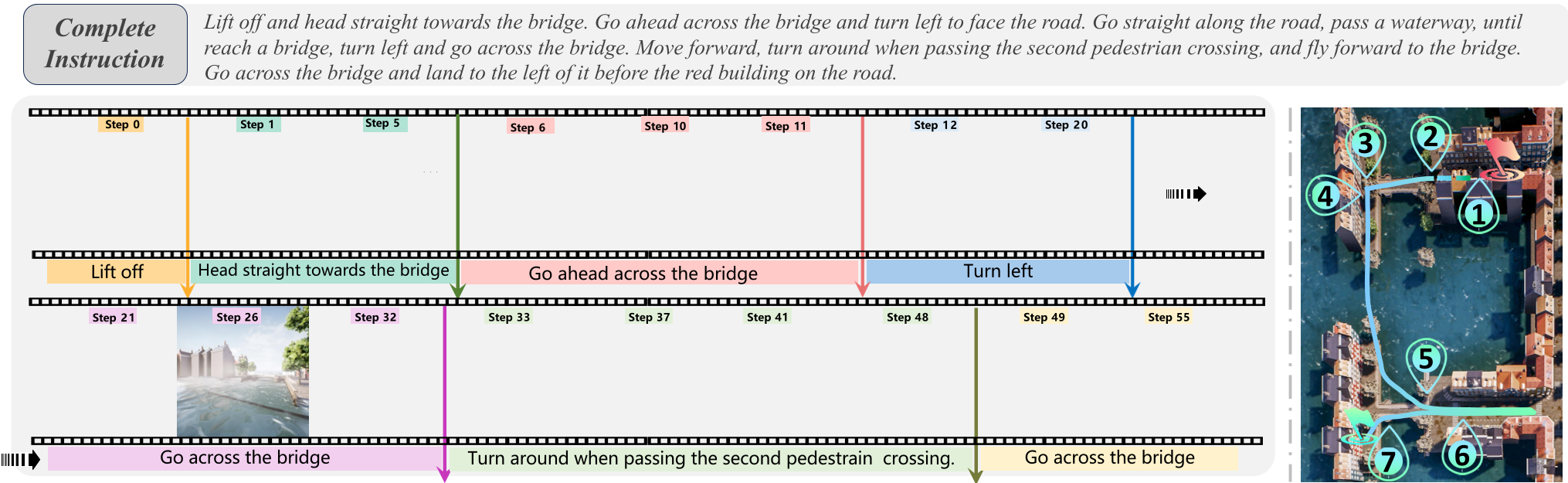
深度洞察与总结
FineCog-Nav 的成功揭示了:导航的本质是信息的过滤与层级化处理。 现有的 LLM 虽强,但直接把长指令丢进去做推理(Monolithic Architecture)是对其逻辑能力的浪费。通过“认知模块化”,我们能让模型在理解环境的同时,学会“回顾过去(Memory)”与“预演未来(Imagination)”。
局限性:尽管实验出色,但在处理动态障碍物(如移动的人群)和超低光照条件下的感知仍有提升空间。未来的研究可以将这种认知框架与更强的物理避障算法(如 NMPC)进一步结合。