FreeArtGS is a novel framework for reconstructing articulated objects from monocular RGB-D videos under "free-moving" scenarios where both the camera and the object parts move unconstrainedly. It integrates motion-based part segmentation, joint parameter estimation, and 3D Gaussian Splatting (3DGS) to achieve high-fidelity geometry and kinematic recovery, reaching SOTA performance with an average axis error of ~1 degree.
TL;DR
Reconstituting interactable digital twins from casual video has long been hindered by the "static base" requirement. FreeArtGS introduces a breakthrough 3D Gaussian Splatting (3DGS) framework that reconstructs articulated objects—like scissors, drawers, or laptops—even when the entire object is moving freely in front of a monocular RGB-D camera. By combining motion-based segmentation with joint optimization, it achieves sub-centimeter geometric accuracy and near-perfect kinematic estimation.
Context & Positioning: The "Free-Moving" Frontier
Existing SOTA methods usually fall into two traps: they either require the object's base to remain perfectly still (unrealistic for handheld objects) or rely on "black-box" foundation models that lack geometric consistency. FreeArtGS positions itself as a practical optimization-based system that utilizes modern priors (like AllTracker and DINOv3) to bridge the gap between casual monocular capture and simulation-ready assets.
Problem & Motivation: Why is Free-Moving Hard?
When both the camera and the object parts move simultaneously, the fundamental problem of inductive bias arises: How do you distinguish between the global motion of the object and the local motion of its articulated joints?
- Prior Limitations: Methods like Video2Articulation collapse when the "static base" assumption is violated.
- The Coverage Gap: If you can't move the whole object to show its back/bottom, the resulting 3D model is incomplete.
- The Free-Moving Insight: By capturing the object from all angles while it articulates, we can achieve full coverage, provided we can decouple the complex transformations.
Methodology: The Three-Pillar Architecture
FreeArtGS solves the reconstruction puzzle through a logically sequenced pipeline:
1. Motion-Based Part Segmentation
Instead of semantic labeling, the system looks for temporal rigidity. It assumes that over short windows, a part's motion is a rigid transform. It uses a "Part Solver" that optimizes part weights $w_{t,p}$ by minimizing the distance between tracked points and their rigidly transformed counterparts.
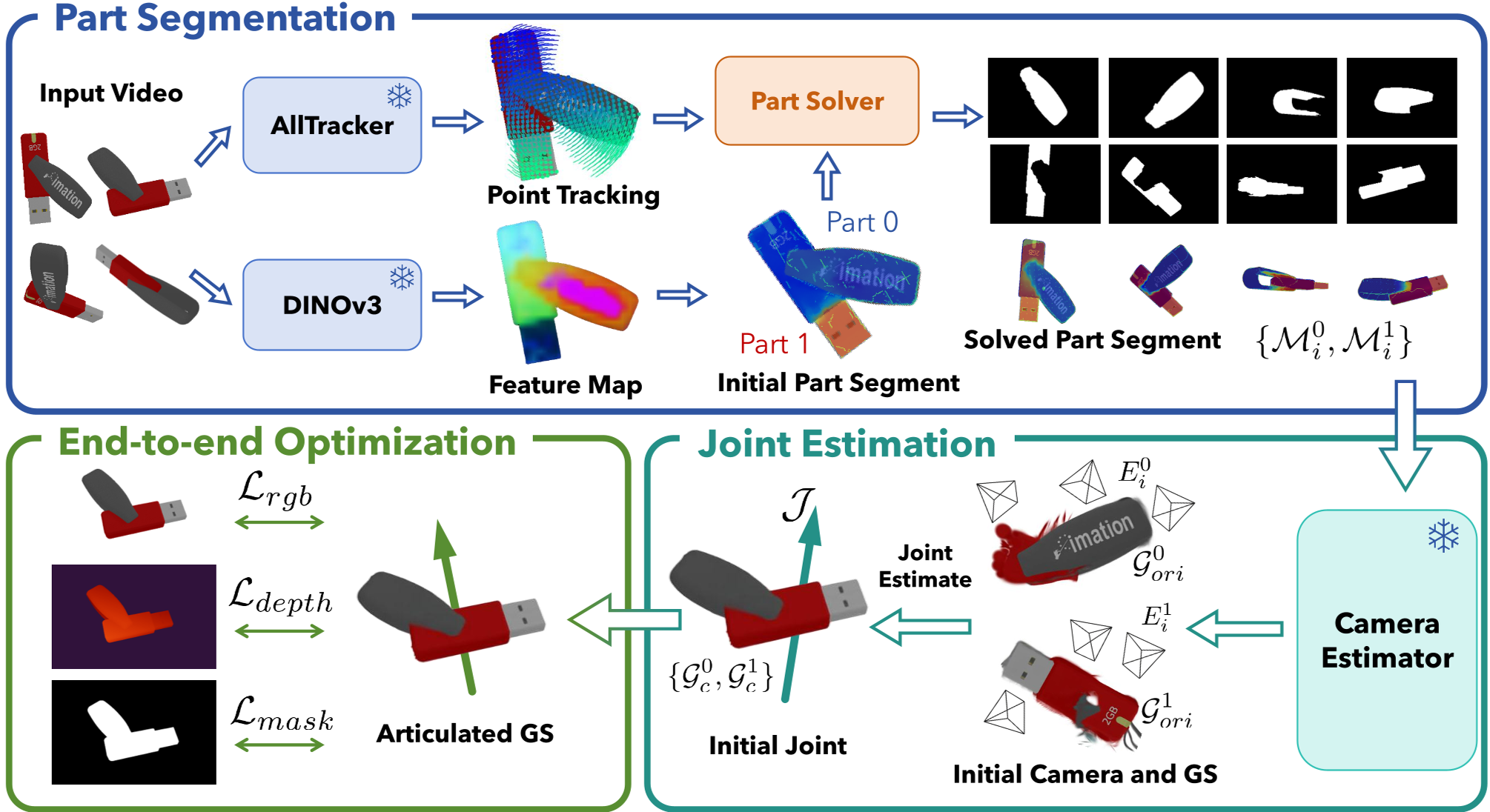 Figure 1: The FreeArtGS pipeline—from raw video to articulated Gaussians.
Figure 1: The FreeArtGS pipeline—from raw video to articulated Gaussians.
2. Robust Joint Estimation
Once parts are identified, the system calculates the relative transformation between them.
- Joint Typing: It differentiates between Revolute (rotation) and Prismatic (sliding) joints by analyzing the rotation span and translation linearity.
- Axis Solving: It uses an SVD-based approach to find the axis direction and a least-squares pivot estimation on a 2D plane to avoid degeneracy.
3. Articulated Gaussian Splatting (3DGS)
The final "magic" happens here. The system represents the object as two sets of Gaussians. Using Blended Rendering, it applies the joint kinematics directly to the Gaussian kernels. $$\mathcal{G}_i = w(\mathcal{G}_c \circ I) \cup (1-w)(\mathcal{G}_c \circ \mathcal{J}_i)$$ The entire system—geometry, appearance, and joint angles—is refined end-to-end using RGB, Depth, and Mask losses.
Experiments: Superiority Across the Board
The authors introduced FreeArt-21, a benchmark simulated via VR teleoperation to mimic real-world handheld movement.
Quantitative Edge
FreeArtGS outperforms baselines (RSRD, Video2Articulation, Articulate-Anything) significantly. In the revolute category, it reduced the joint axis error from over 20° (Video2Articulation) to a staggering 1.04°.
 Table 1: Competitive analysis showing FreeArtGS's dominance in kinematic and geometric metrics.
Table 1: Competitive analysis showing FreeArtGS's dominance in kinematic and geometric metrics.
Visual Fidelity
Qualitative results show that FreeArtGS can handle thin, complex structures like the blades of a pair of scissors or the fine scales of a stapler, which previous methods typically turn into "visual soup."
 Figure 2: Real-world success—FreeArtGS accurately reconstructs household items like fans and trash bins even with hand occlusions.
Figure 2: Real-world success—FreeArtGS accurately reconstructs household items like fans and trash bins even with hand occlusions.
Critical Insight & Future Outlook
The success of FreeArtGS stems from its "Priors-plus-Optimization" philosophy. Rather than trusting a feed-forward network to "guess" the joint, it uses point-tracking as a guide for a rigorous mathematical optimization of the kinematic chain.
Limitations:
- Complexity: Currently supports only two-part articulation (1-DOF).
- Input Dependency: Requires RGB-D; moving to RGB-only remains a challenge due to the need for absolute depth scale in joint pivot solving.
The Takeaway: FreeArtGS is a vital step toward automated "Digital Twin" generation. It provides a blueprint for how robots might one day "look and learn" about any articulated tool they encounter in the human world.