The paper introduces PIXAR, a large-scale Vision-Language Model (VLM) image tampering benchmark that shifts the detection paradigm from coarse object masks to precise pixel-level difference maps. It employs a new taxonomy of 8 manipulation types and establishes a unified protocol for localization, semantic classification, and natural language description.
TL;DR
The "Ground Truth" for image tampering detection has been broken. For years, researchers used coarse object masks to label edits, but these masks capture unedited pixels and miss subtle artifacts outside the boundaries. PIXAR fixes this by introducing a pixel-grounded, meaning-aware benchmark. By using per-pixel difference maps and a multi-task VLM framework, PIXAR achieves a 2x improvement in localization accuracy (IoU) and provides natural language explanations for why an image is fake.
Problem & Motivation: The Mask Misalignment Trap
Current forensics benchmarks (like SID-Set or TrainFors) suffer from a fundamental flaw: Mask-based misalignment.
In a typical generative edit (e.g., replacing a dog with a cat), a mask is used to define the region. However:
- Over-labeling: Many pixels inside the mask are never actually touched by the generative model.
- Under-labeling: Critical "telltale" signs like shadow changes, relighting halos, and seam artifacts often occur outside the mask.
When models are trained on these noisy masks, they learn to detect "objects" rather than "generative artifacts." PIXAR argues that to catch modern AI fakes, we must look at the Pixels, Meanings, and Language simultaneously.
Methodology: Precision Through Difference Maps
The core innovation of PIXAR is the Thresholded Difference Map (). Instead of a binary "inside/outside" mask, the ground truth is derived from the absolute pixel difference between the source and the tampered image:
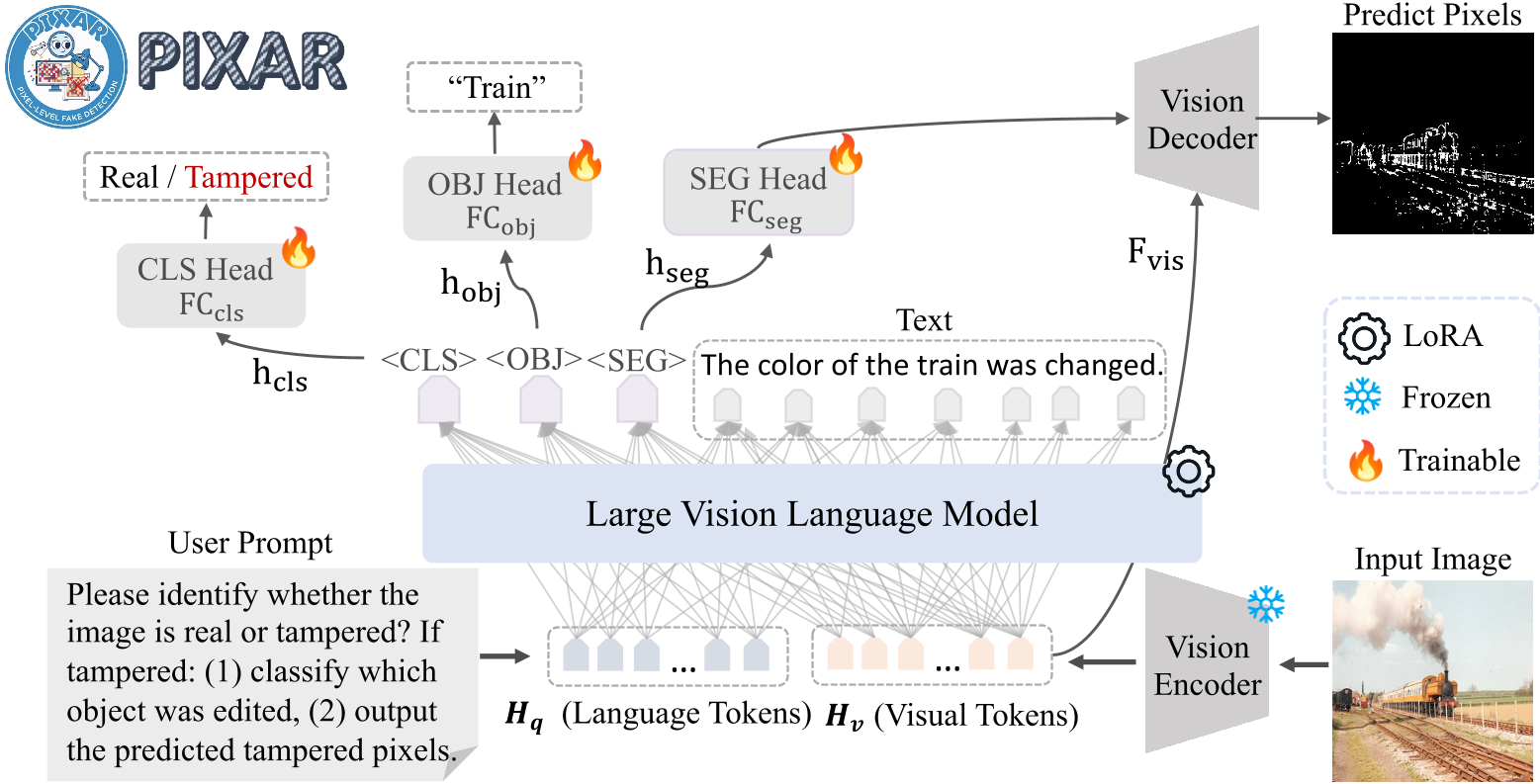 Figure: The PIXAR Training Framework integrates Localization, Classification, and Description.
Figure: The PIXAR Training Framework integrates Localization, Classification, and Description.
The Unified Multi-task Framework
The PIXAR detector doesn't just output a heatmap. It employs five joint losses:
- Pixel-wise BCE & Dice: For sharp, accurate boundaries.
- Multi-label Semantic Loss: Identifying what object was tampered with (e.g., "cup", "car").
- Global Detection Loss: A binary "Real vs. Fake" classifier.
- Autoregressive Text Loss: Generating captions like "The chair was replaced with a sofa."
Experiments: Setting New SOTA Standards
The benchmark was tested against heavyweights like LISA and SIDA using a dataset of 40K balanced image pairs generated by Flux.2, Gemini, and GPT-4.
 Table: Comparison shows PIXAR significantly outperforming baselines in both Semantic Accuracy and Pixel IoU.
Table: Comparison shows PIXAR significantly outperforming baselines in both Semantic Accuracy and Pixel IoU.
Key Findings:
- Localization Leap: PIXAR-13B reached an IoU of 19.3%, compared to just 10.8% for SIDA-13B.
- Threshold Sensitivity: Lower values of (e.g., 0.05) capture micro-edits that are invisible to the naked eye but contains vital forensic evidence.
- Cross-Model Robustness: Although trained mostly on Qwen-Image data, the model generalizes impressively to GPT-Image-1.5, proving it learns "universal" generative footprints rather than model-specific noise.
Detailed Manipulation Taxonomy
PIXAR introduces 8 distinct types of tampering, moving beyond simple "Inpainting":
- Intra-class Replacement: Replacing an apple with a different apple (highly subtle).
- Attribute/Color Modification: Changing textures or material properties.
- Multi-Object Sequential Edits: Complex forgeries involving multiple steps.
 Figure: Examples of the 8 different tampering strategies in the PIXAR benchmark.
Figure: Examples of the 8 different tampering strategies in the PIXAR benchmark.
Critical Analysis & Conclusion
The strongest takeaway from this work is that Semantic Meaning matters for Localization. By forcing the model to describe the edit in text, the internal features become more robust against random noise.
Limitations: The model still struggles with "Pixel-Semantic Inconsistency"—cases where a semantic change occurred but the pixel difference was too small to pass the threshold . Future work will likely need to integrate frequency-domain analysis to catch these "zero-pixel-change" semantic shifts.
PIXAR sets a new, more rigorous standard for digital forensics, proving that in the age of generative AI, the truth is found in the pixels, not the masks.