Fus3D is a feed-forward 3D reconstruction framework that regresses dense Signed Distance Fields (SDF) directly from the latent features of multi-view geometry transformers (FFGT) in under three seconds. By bypassing typical per-view depth prediction and post-hoc fusion, it achieves state-of-the-art completeness and scalability, outperforming baselines like VolRecon and UFORecon in both sparse and dense view scenarios.
TL;DR
Fus3D shifts the 3D reconstruction paradigm from "predict-then-fuse" to "direct extraction." By tapping into the intermediate latent space of pretrained geometry transformers, it regresses a complete Signed Distance Field (SDF) in under 3 seconds. It solves the "incompleteness" problem in sparse views and the "noise accumulation" problem in dense views, providing a robust, pose-free solution for real-time 3D vision.
The "Predict-Then-Fuse" Bottleneck
In the current SOTA landscape, models like DUSt3R or VGGT produce impressive 2.5D outputs (depth maps or point clouds). However, to get a watertight 3D mesh, researchers typically use TSDF Fusion or Poisson Reconstruction.
This post-hoc consolidation is fundamentally flawed for two reasons:
- Prior Loss: The transformer has already "seen" the whole scene and likely inferred hidden parts (e.g., the back of an object) due to learned symmetry, but per-view depth heads discard this "global" intuition.
- Error Accumulation: Small errors in camera pose or depth estimation don't cancel out; they stack up. As you add more views, the fused surface often becomes noisier rather than cleaner.
Fus3D: Lifting 2D Latents to 3D Space
Fus3D replaces per-view heads with a Learned Volumetric Extraction module.
The Architecture
The method uses the VGGT backbone to generate multi-view features. The "bridge" to 3D is a set of learned 3D voxel-position embeddings ($z_{3D}$). These embeddings act as queries that "pull" information from the 2D image tokens through transformer blocks.
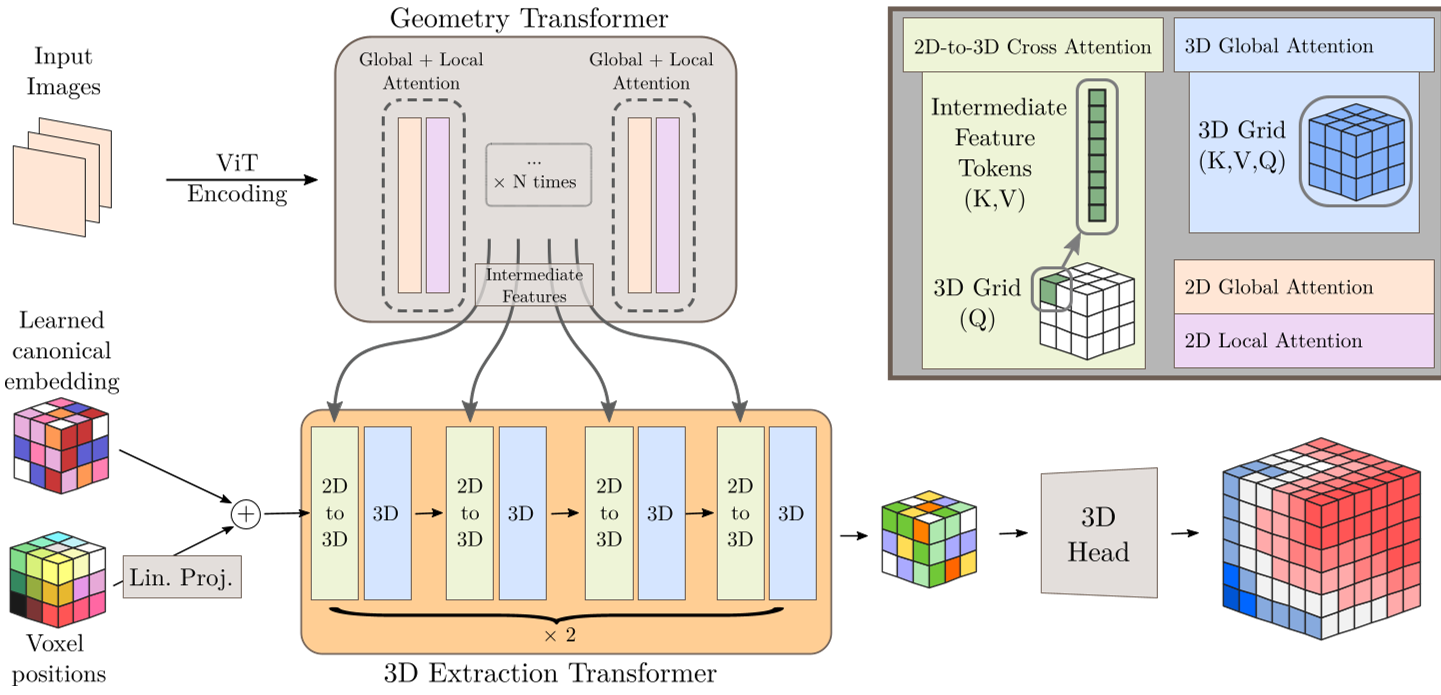 Fig 1: The Fus3D pipeline. 2D features are progressively fused into a 3D latent grid via attention, then decoded into an SDF.
Fig 1: The Fus3D pipeline. 2D features are progressively fused into a 3D latent grid via attention, then decoded into an SDF.
Validity-Aware Supervision
Training on real-world datasets is messy—meshes are often "open" (not watertight). Fus3D introduces a Validity Mask ($M_{val}$) and an Eikonal Mask ($M_{eik}$). If a region in the ground truth violates the Eikonal property (meaning the distance field is localy inconsistent), the loss automatically reverts to an unsigned distance variant. This allows the model to learn from imperfect data without being penalized by spurious sign flips.
Experimental Performance
Fus3D was tested against generalizable SDF baselines like VolRecon and UFORecon. Even without knowing camera parameters at inference (pose-free), Fus3D outperformed these models in Chamfer Distance by nearly 30%.
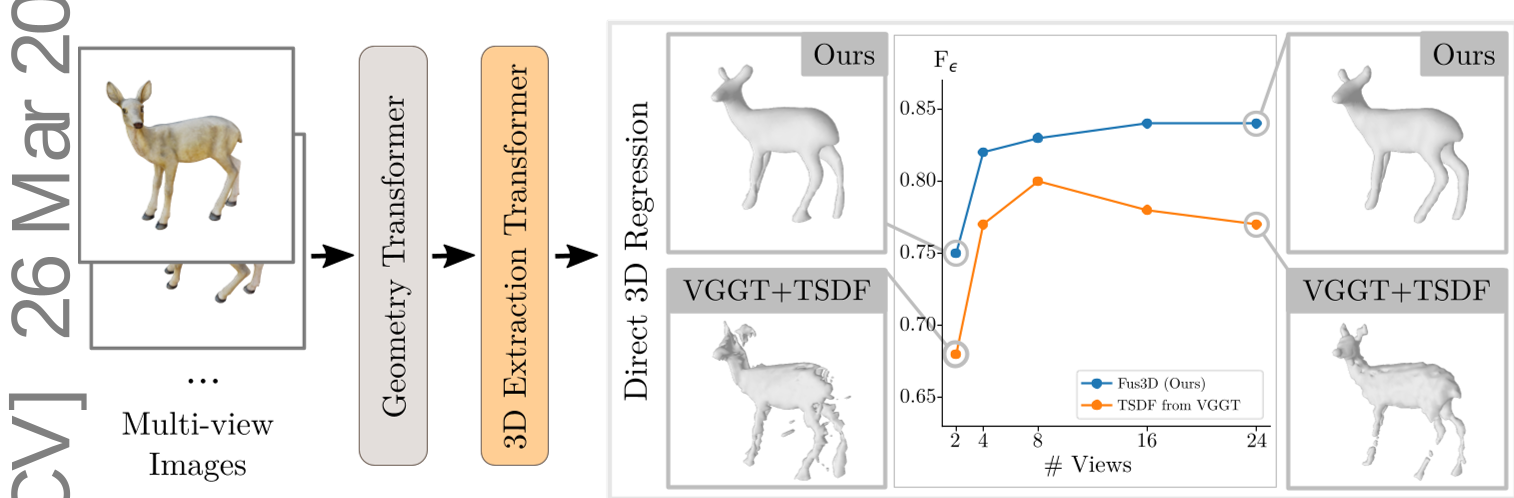 Fig 2: Comparison of surface completeness. Fus3D (bottom) maintains structure where traditional fusion (top) leaves holes in sparse-view settings (left) and accumulates noise in dense-view settings (right).
Fig 2: Comparison of surface completeness. Fus3D (bottom) maintains structure where traditional fusion (top) leaves holes in sparse-view settings (left) and accumulates noise in dense-view settings (right).
Scaling and Efficiency
One of the most impressive results is the inference speed. Because it bypasses the heavy computational overhead of post-hoc fusion, Fus3D maintains a near-constant inference time as view counts increase, whereas traditional fusion methods scale linearly (and slowly).
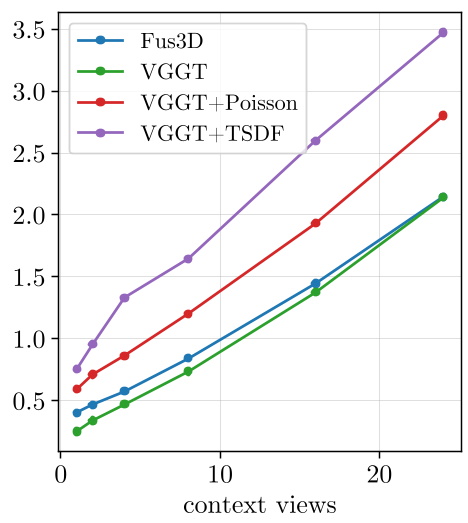 Fig 3: Inference time vs. view count. Fus3D provides a massive speedup as the scene complexity grows.
Fig 3: Inference time vs. view count. Fus3D provides a massive speedup as the scene complexity grows.
Critical Insight: Emergent Semantic Symmetries
The authors performed a PCA analysis on the learned 3D latents. The results showed that features near the surface align with shared geometric parts across different objects (e.g., legs of chairs or wings of avatars). This proves that the latent volume isn't just storing occupancy—it's building a structured geometric manifold that understands object-level statistics.
Conclusion and Future Outlook
Fus3D marks a shift toward unified 3D latent representations. By moving away from external fusion, it achieves a level of robustness and speed that makes it ideal for robotic manipulation or instant AR/VR scene capture.
Limitations: The current resolution is limited to $64^3$ due to memory constraints of dense voxels. Future work involving Sparse Voxel Octrees or multi-scale upsampling could likely push this into high-fidelity territory without losing the feed-forward speed advantage.