GameWorld is a comprehensive benchmark for evaluating Multimodal Large Language Model (MLLM) agents across 34 diverse browser-based games and 170 tasks. It introduces a standardized sandbox that decouples inference latency from gameplay and achieves state-of-the-art evaluation reliability through outcome-based, state-verifiable metrics.
TL;DR
Researchers from the National University of Singapore and Oxford have released GameWorld, a massive benchmark designed to stop the "Wild West" of MLLM game evaluation. By providing 34 games, 170 tasks, and a novel paused-inference sandbox, it forces AI agents to compete on pure logic and perception rather than raw hardware speed. The verdict? Even our best AI "gamers" are still getting crushed by human beginners.
The Problem: Why Evaluating Game Agents is Broken
Until now, testing if an AI could play a video game was a messy process. Most researchers relied on "VLM-as-judge" (asking one AI if another AI played well) or brittle OCR that breaks if a pixel changes.
More importantly, there was the Latency Trap: If Model A is smarter but takes 5 seconds to "think," it might lose a game of Flappy Bird to Model B, which is "dumber" but responds in 100ms. This prevents us from knowing if the model actually understood the game or just had a faster API connection.
Methodology: The Verifiable Sandbox
GameWorld solves this with a four-pillar architecture designed for rigorous academic standards.
1. The Decoupled Runtime
The core innovation is a browser-based sandbox that pauses the game the moment a screenshot is taken and only resumes once the model submits its action. This isolates "Decision Quality" from "Inference Speed."
2. Dual-Interface Standardization
The authors realized that different models "talk" differently. They standardized these into:
- Computer-Use Agents (CUA): They "see" pixels and "press" keys (e.g.,
press_key("Space")). - Generalist Agents: They use Semantic Action Parsing to map high-level thoughts (e.g.,
jump()) into low-level commands.
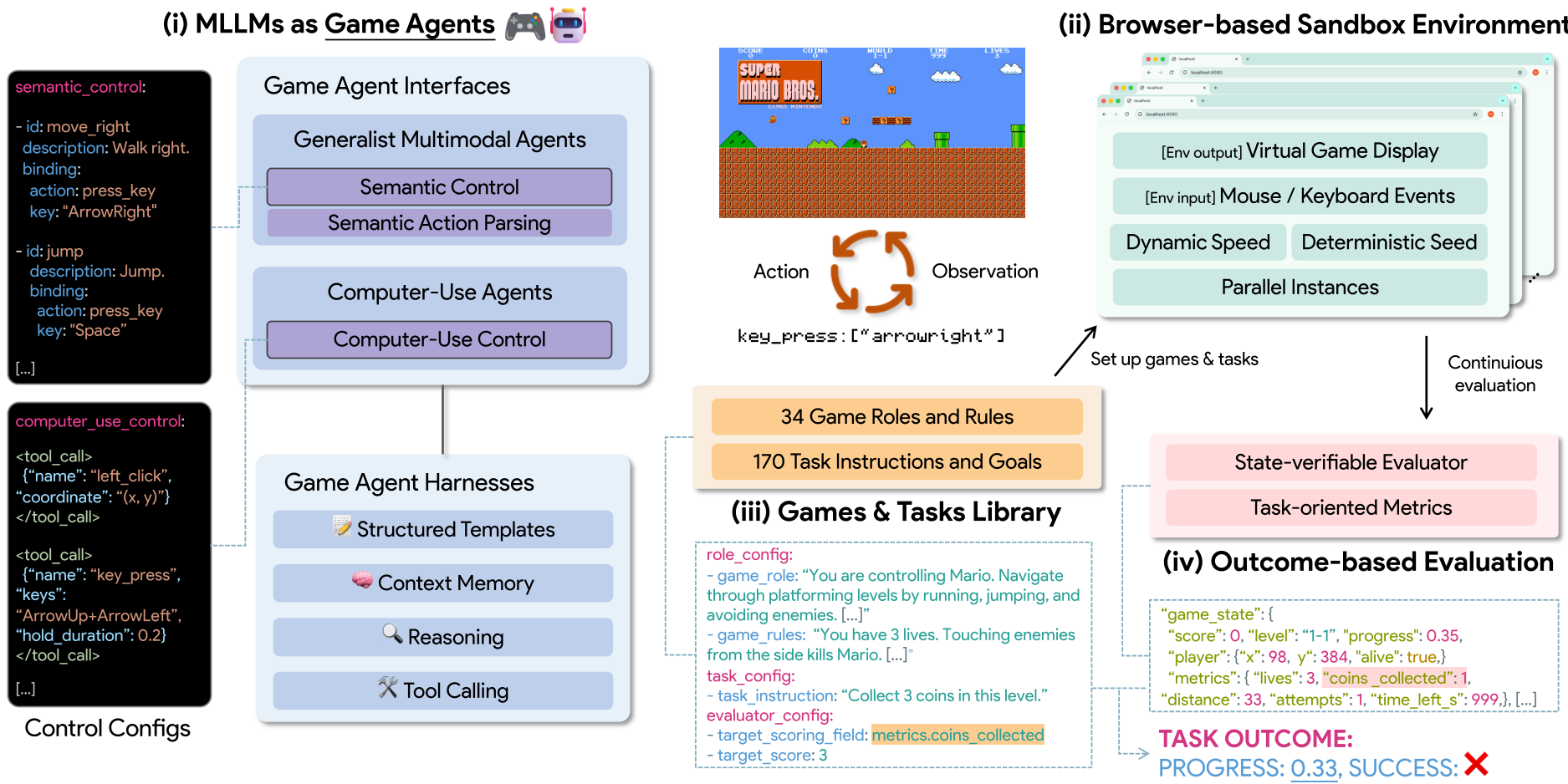 Figure 1: The GameWorld loop showing the transition from visual observation to verifiable state changes.
Figure 1: The GameWorld loop showing the transition from visual observation to verifiable state changes.
3. State-Verifiable Evaluation
Instead of guessing if the agent won, GameWorld injects a JavaScript bridge into the games. It reads the internal game code (coordinates, health, score) directly. This provides a deterministic success signal with zero perceptual noise.
Experiments: AI vs. Human Novice
The researchers tested 18 different model-interface combinations, including heavyweights like GPT-5.2, Claude-Sonnet-4.6, and Gemini-3-Flash.
The Capability Gap
The results were humbling. While humans reached an 82.6% progress score, the best AI (Gemini-3) managed only 41.9%.
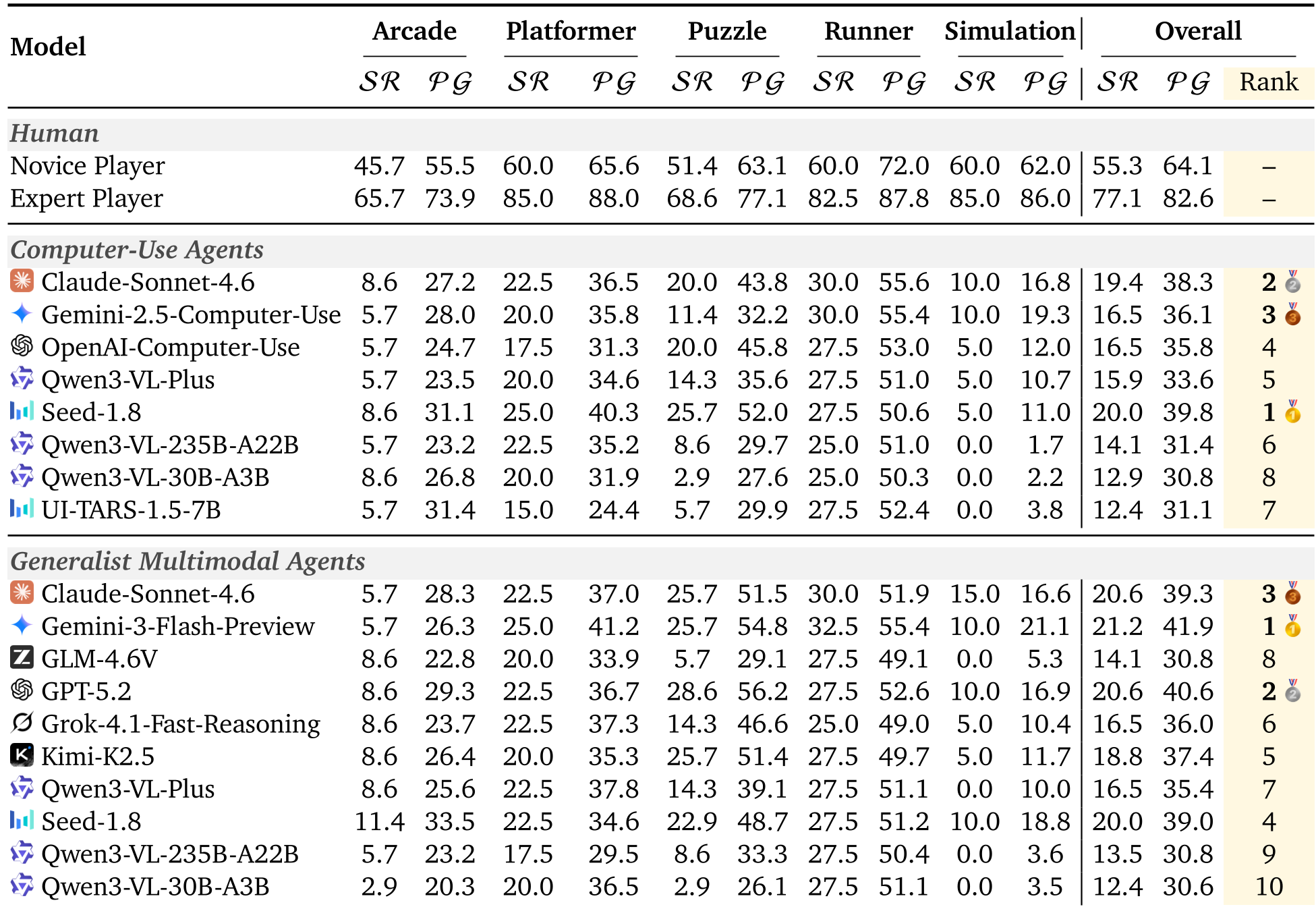 Table 1: Main Leaderboard. Note the significant gap between the 'Expert Player' and the industry's leading MLLMs.
Table 1: Main Leaderboard. Note the significant gap between the 'Expert Player' and the industry's leading MLLMs.
The Five-Level Curriculum
The study broke down performance into five "Curriculum Levels" to see where the brain of the AI actually fails:
- Level 1 (Timing): Surprisingly hard. Models struggle to click at the exact right millisecond.
- Level 4 (Symbolic Strategy): AI excels here. In games like 2048 or Wordle, the internal logic of the MLLM shines.
- Level 5 (Long-Horizon): Total collapse. In complex sims like Minecraft, models lose track of their goals over time.
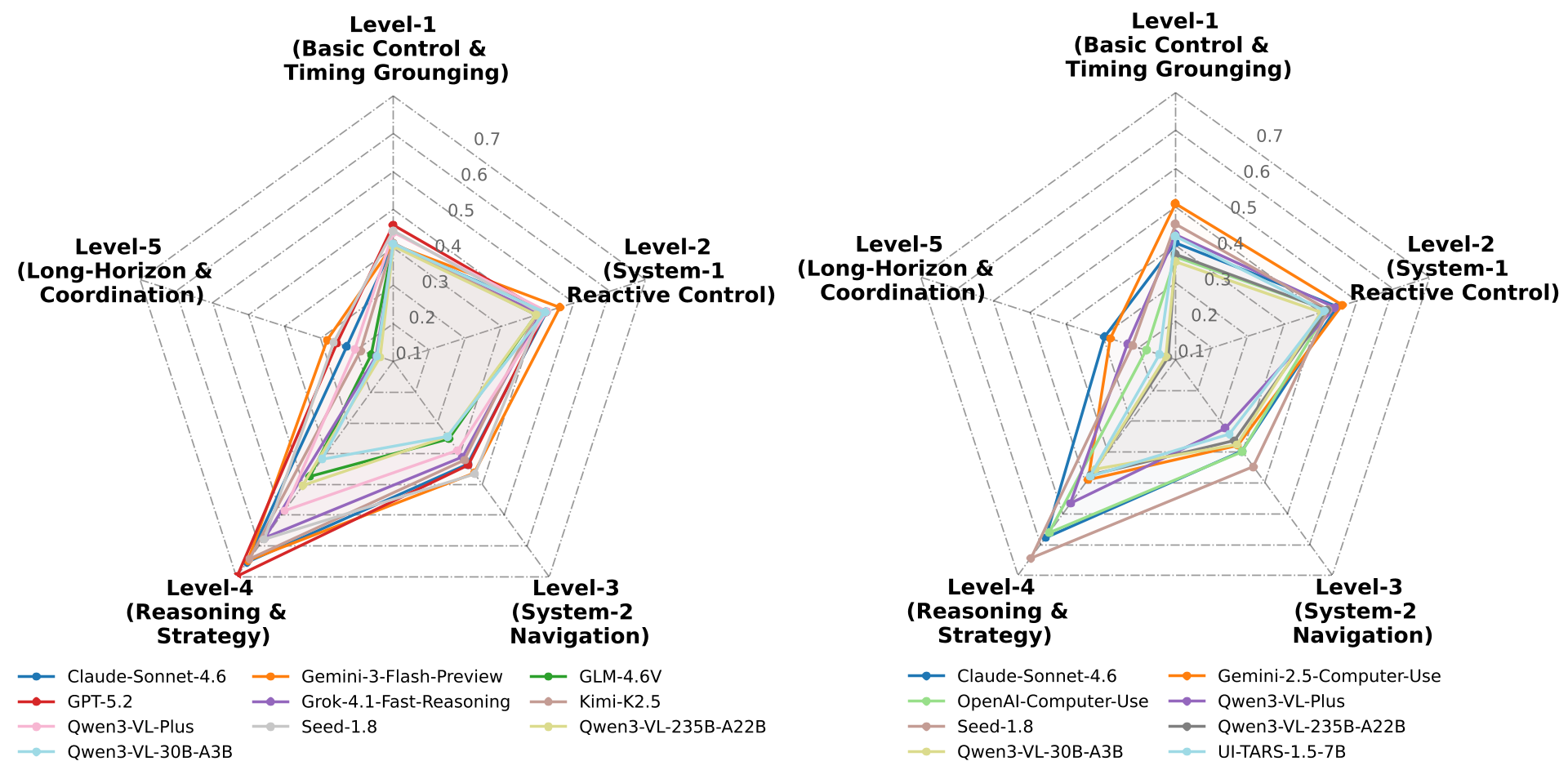 Figure 2: Radar charts showing that both CUA and Generalist interfaces share the same bottleneck: Level 1 (Timing) and Level 5 (Complexity).
Figure 2: Radar charts showing that both CUA and Generalist interfaces share the same bottleneck: Level 1 (Timing) and Level 5 (Complexity).
Deep Insight: Memory is a Double-Edged Sword
A fascinating find in the paper concerns Context-Memory Sensitivity. For "Generalist" agents, more memory helped. But for "Computer-Use" agents, giving them a long history of past raw keyboard/mouse actions actually decreased performance. The models got "distracted" by the low-level noise of their own past movements, proving that semantic abstraction is vital for long-term planning.
Conclusion & Perspective
GameWorld marks a shift from "can it play?" to "how precisely can it play?". It exposes the fact that while modern LLMs can "reason" about a strategy, they are effectively "clumsy" when it comes to the physical-digital grounding of actions.
For developers, the takeaway is clear: Better reasoning isn't enough. We need models with better "Action Grounding"—the ability to understand exactly how their digital motor outputs correspond to the changing pixels on a screen.
Future Work: The authors point toward automating the "Semantic Action Parsing" so the MLLMs can "learn" how to use a game's controls just by exploring, rather than needing human-written code to bridge the gap.