本文推出了 GameWorld,一个专门针对多模态游戏智能体(Multimodal Game Agents)的标准化、可验证评测基准。该框架涵盖了从动作游戏到模拟经营的 34 款浏览器游戏和 170 个任务,通过引入分态验证机制(State-verifiable evaluation)和解耦推理延迟的沙盒环境,实现了对 MLLM 智能体性能的客观量化。
1. 核心速览 (Executive Summary)
TL;DR:来自新加坡国立大学和牛津大学的研究团队推出了 GameWorld,一个旨在实现标准化、可验证评测的多模态游戏智能体基准。它通过 34 款浏览器游戏和 170 个任务,首次系统地揭示了顶级 MLLM(如 GPT-5.2, Claude-Sonnet-4.6)在面对复杂交互环境时的真实战力。
背景定位:在 AI 智能体(Agents)向“通用具身智能”迈进的过程中,游戏一直是最理想的试炼场。GameWorld 的出现,填补了以往评测工具在“动作接口不统一”和“验证逻辑不严谨”上的空白,是该领域从“玄学打分”转向“精确度量”的重要里程碑。
2. 动机分析 (Motivation):当推理延迟遇上实时游戏
以往的游戏 AI 评测面临两个致命伤:
- 信噪比低:很多评测靠视觉模型去“看”屏幕给分,这就像是用一个不靠谱的裁判去评判一个新手球员。
- 时延耦合:在《神庙逃亡》这类游戏中,如果模型推理需要 5 秒,那么等它决定“跳跃”时,角色已经掉进深渊了。这导致我们无法判断模型究竟是“脑子笨”还是“反应慢”。
GameWorld 的 Insight:作者开发了一个基于浏览器的沙盒,支持推理时暂停(Pause-during-inference)。这能够将“决策质量”从“响应速度”中解耦出来,给所有 AI 同样的思考机会。
3. 架构与方法论 (Methodology)
3.1 两种控制范式的博弈
GameWorld 巧妙地设计了两种接入方式,涵盖了目前主流的两类 Agent 路径:
- Computer-Use Agents (CUA):直接操控键鼠。模型需要自己计算屏幕坐标、按键组合。这最接近人类的真实交互。
- Generalist Agents:通过语义指令(如
move_left)进行操作。系统会自动将这些指令解析为底层动作。
3.2 绝对公正的“上帝视角”
摒弃了不靠谱的视觉打分,GameWorld 注入了一个结构化的 JavaScript 桥接器。它直接读取游戏内存中的变量(如得分、坐标、剩余生命值),从而产出**确定性(Deterministic)**的成功率(Success Rate)和进度值(Progress)。
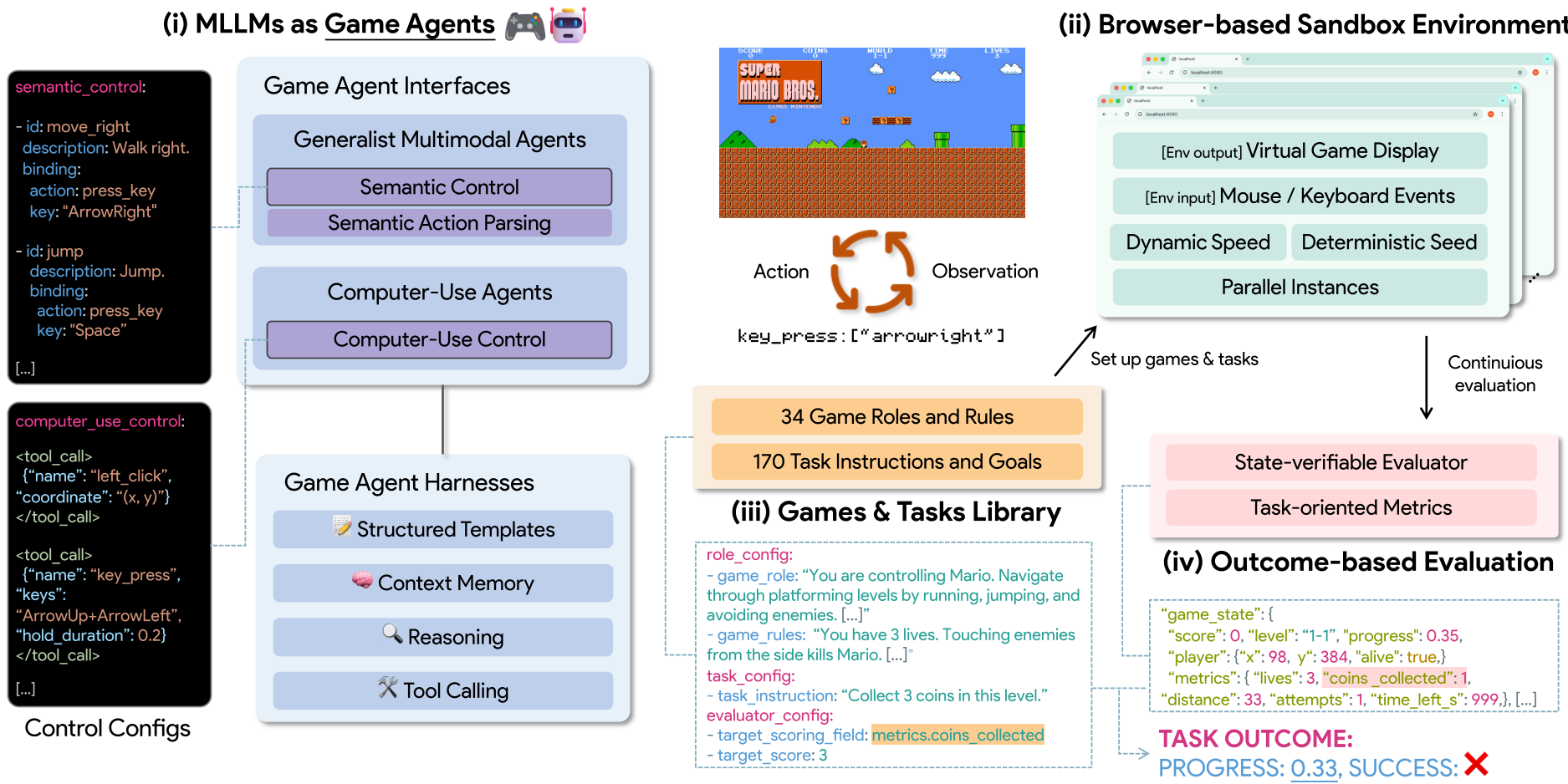 图 1:GameWorld 观察-动作-验证的闭环框架
图 1:GameWorld 观察-动作-验证的闭环框架
4. 实验结果与诊断 (Results & Analysis)
4.1 惨淡的“众神之战”数据
实验评估了包括 GPT-5.2、Claude 4.6、Gemini 3 Flash 在内的 18 种顶尖模型。结果令人惊讶:
- SOTA 的天花板:即使是表现最好的 Gemini-3-Flash,其综合进度得分也仅在 41.9% 左右。
- 人类碾压:人类专家在同样的操作步数限制下,能轻松达到 82.6% 的进度。
- 分项瓶颈:AI 在“战略推理(Level-4)”上表现尚可,但在“精细化时序控制(Level-1/2)”和“长程协作(Level-5)”上表现极其拉胯。
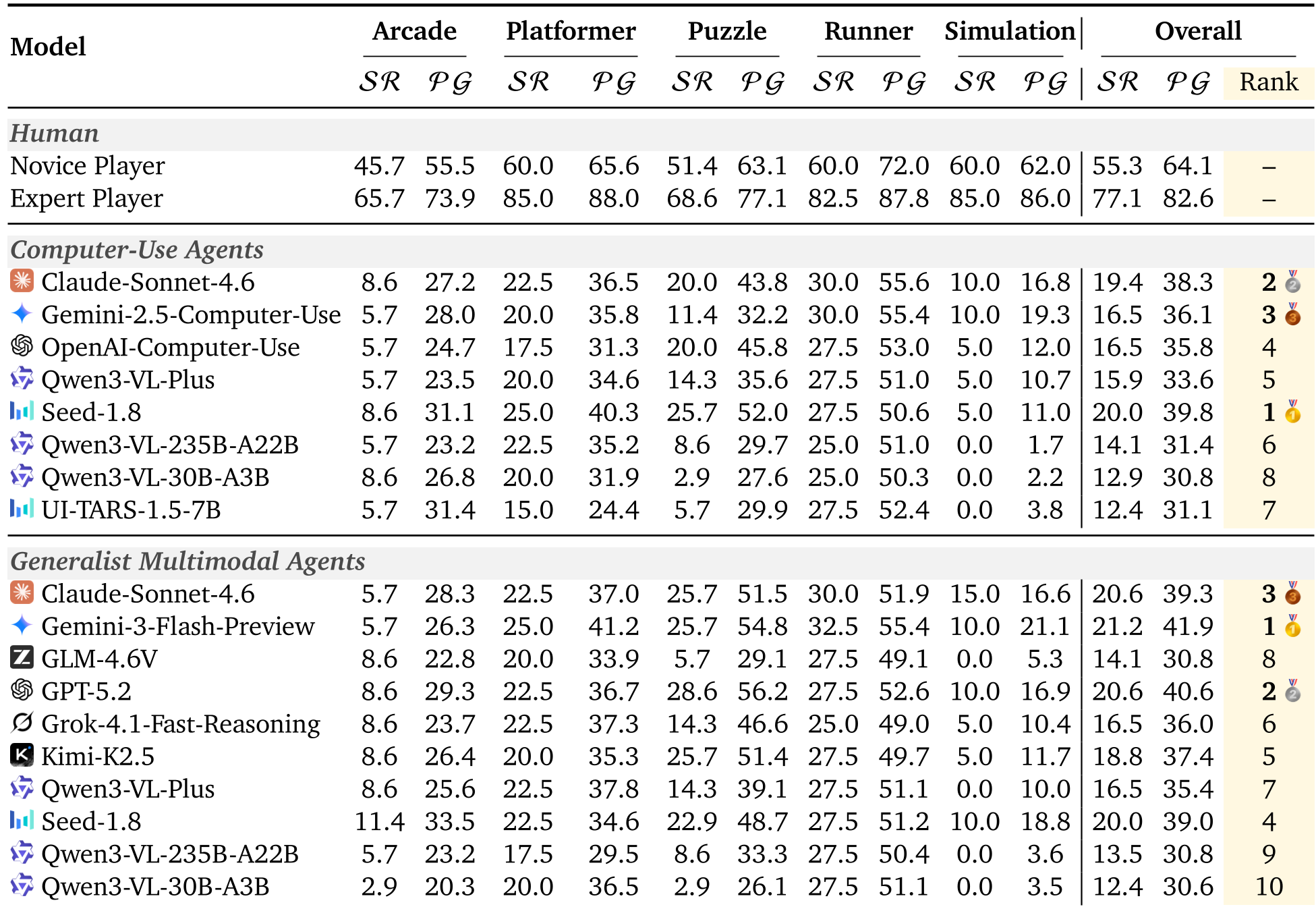 表 1:全机型主流游戏性能对比(可见 AI 距离人类仍有巨大鸿沟)
表 1:全机型主流游戏性能对比(可见 AI 距离人类仍有巨大鸿沟)
4.2 失败模式的深度剖析
论文总结了 AI 智能体的四大典型死法:
- 感知失败:在密集的横版过关游戏中,AI 常误判障碍物的精确位置。
- 动作偏误:知道该跳,但按键时间不对。
- 指令漂移:在长序列任务中忘记了最初的目的。
- 死循环:反复执行无效动作,缺乏自省(Self-correction)。
5. 结论与未来展望 (Critical Analysis & Conclusion)
GameWorld 证明了:目前的 MLLM 还没有准备好接管复杂动态系统。
核心启示(Takeaway): 提升 Agent 的表现不能光靠堆算力或增加输入 Token 长度。实验发现,增加上下文记忆窗口并不总是有利,反而可能显著增加延迟并引入干扰信息(尤其是对 CUA 接口)。未来的研究应当更关注:
- 低延迟推理:如何让“慢思考”转变为“条件反射式的快思考”?
- 时轴对齐:让模型理解视觉流中的每一帧对于物理动作触发的精确意义。
- 分层策略:将高层的语义规划与底层的精细动作解耦。
对于开发者而言,GameWorld 提供了一套现成的、高性能的浏览器游戏环境,是训练和调优多模态 Agent 的绝佳工具。
参考文献: Ouyang, M., et al. (2026). GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents. GitHub Site