GaussFusion is a geometry-informed video-to-video diffusion framework designed to refine 3D Gaussian Splatting (3DGS) reconstructions. By conditioning a video generator on a multi-modal "GP-Buffer," it achieves state-of-the-art novel view synthesis and enables real-time refinement at 16 FPS.
TL;DR
3D Gaussian Splatting (3DGS) has revolutionized real-time 3D rendering, but "in-the-wild" captures often result in messy reconstructions filled with "floaters" and blurry artifacts. GaussFusion fixes this by treating 3D refinement as a video-to-video translation task. By feeding a video generator not just color, but also depth, normals, and geometric uncertainty (the GP-Buffer), it transforms noisy 3DGS renders into photorealistic videos at a staggering 16 FPS.
The Problem: Why 3D Splats Still Look "Noisy"
Whether using traditional optimization or modern "feed-forward" models that predict Gaussians in one pass, 3D reconstruction often fails when data is sparse. We see:
- Floaters: High-frequency noise floating in mid-air.
- Needles: Elongated Gaussians caused by poor camera coverage.
- Blur: Low-frequency oversmoothing in feed-forward models.
Previous attempts to use AI to "clean up" these renders mostly used RGB images. But color alone is ambiguous—is that blur a texture or a reconstruction error? Without geometric context, these models struggle to maintain 3D consistency.
Methodology: The Power of the GP-Buffer
The core innovation of GaussFusion is the Gaussian Primitives Buffer (GP-Buffer). Instead of just looking at the final image, the model looks at the "bones" of the reconstruction:
- Color & Alpha: The standard appearance.
- Depth & Normals: Explicit surface structure.
- Inverse Covariance (Uncertainty): A map showing where the splats are "unstable" or over-stretched.
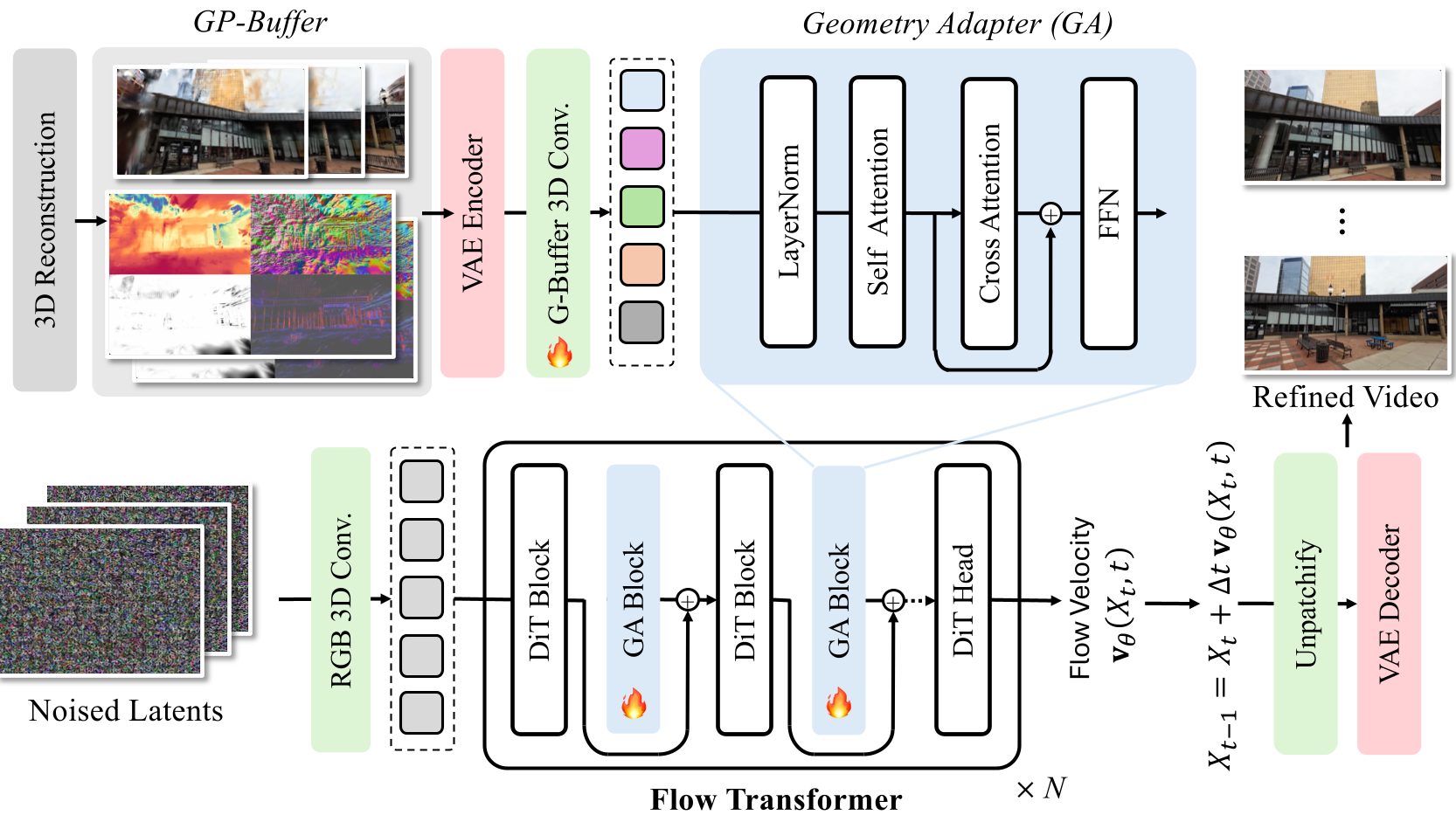 Figure 1: The GaussFusion pipeline. The GP-Buffer is encoded and injected into a Video Transformer (DiT) via a specialized Geometry Adapter.
Figure 1: The GaussFusion pipeline. The GP-Buffer is encoded and injected into a Video Transformer (DiT) via a specialized Geometry Adapter.
The Geometry Adapter (GA)
Rather than simply concatenating pixels, GaussFusion uses a Geometry Adapter. This module acts as a "side-car" to a pretrained video model (Wan-2.1), injecting geometric features into the transformer blocks. This ensures the output images are strictly aligned with the underlying 3D math of the scene.
Experiments: Real-World Performance
The authors didn't just train on clean data; they built an Artifact Simulation Pipeline that mimics restricted views and pose errors.
SOTA Comparison
On benchmarks like DL3DV and RE10K, GaussFusion delivers a massive jump in quality. It doesn't just "filter" the image; it contextually inpaints missing regions and sharpens textures.
 Figure 2: Qualitative comparison. Notice how GaussFusion removes spiky artifacts and "floaters" that other methods (like MVSplat360 or ExploreGS) miss.
Figure 2: Qualitative comparison. Notice how GaussFusion removes spiky artifacts and "floaters" that other methods (like MVSplat360 or ExploreGS) miss.
Efficiency: Real-Time Refinement
One of the biggest hurdles for diffusion models is speed. By using Distribution Matching Distillation (DMD), the team compressed the model from 30-50 steps down to just 4 steps. This allows GaussFusion to run at 16 FPS, making it viable for interactive applications where a user could see a "cleaned" version of their 3D scan almost instantly.
Critical Insight: Paradigm Agnosticism
What makes GaussFusion stand out is that it is paradigm-agnostic. It doesn't care if your 3DGS came from a 10-hour optimization or a 10-millisecond feed-forward prediction. By exposing the model to "Cross-Paradigm" artifacts during training, it becomes a universal "3D Post-Processor."
Conclusion & Future Look
GaussFusion proves that the secret to better 3D isn't just better radiance fields, but smarter generative priors that understand geometry.
- Takeaway: The GP-Buffer is a superior conditioning signal for 3D tasks.
- Limitation: Very rapid motion or severe blur still poses a challenge for the underlying VAE.
- Future: We might soon see video models that don't just refine 3DGS, but directly generate and update the 3D parameters in real-time.
Paper: GaussFusion: Improving 3D Reconstruction in the Wild with A Geometry-Informed Video Generator (CVPR 2026)