本文提出了一种名为 Gaze-Regularized VLA 的训练框架,通过 KL 散度将机器人视觉语言动作模型(VLA)的内部注意力机制与人类注视点(Gaze)分布进行对齐。该方法在不改变模型架构且不增加推理开销的情况下,显著提升了机器人在操纵任务中的感知效率。
TL;DR
传统的视觉-语言-动作(VLA)模型在执行任务时往往“眉毛胡子一把抓”,缺乏对关键目标的聚焦能力。香港大学的研究团队提出了一种注视点正则化训练框架,通过将人类的视觉注意力先验注入 Transformer 的注意力层,使模型在不改变架构的情况下,操纵成功率提升了 12%,并具备了更强的稳健性和解释性。
动机:为什么机器人总是“心不在焉”?
在复杂的操纵任务中,如“从杂乱的柜子里拿出一瓶药”,人类会精准地锁定瓶盖、障碍物边缘和目标位置。而目前的 VLA 模型(如 Pi-0, OpenVLA)通常是被动感知:它们将整张图像作为输入,通过大量的试错来摸索哪些像素是重要的。
这种方式带来了两个致命痛点:
- 训练低效:在百万级的演示数据中寻找微小的视觉线索无异于大海捞针。
- 解释性差:当机器人失败时,开发者无法得知它是因为“没看到”还是“没抓稳”。
作者的直觉非常明确:注视点(Gaze)包含了人类的意图、规划和执行逻辑。 如果模型能学会在操作前先“看”该看的地方,问题就迎刃而解了。
核心方法:将人类注视转化为归纳偏置 (Weighting the Vision)
由于大多数机器人数据集不包含昂贵的眼动追踪数据,作者设计了一套精妙的流程将视觉先验“无痛”注入模型:
1. 从热图到补丁 (Heatmap to Patch)
利用预训练的 GLC(Global-Local Correlation)网络生成合成注视热图。为了与 Transformer 的 Token 结构匹配,作者将连续的热图强度映射到离散的图像补丁(Patch)上,形成一个补丁级的概率分布 。
2. 时间聚合 (Temporal Aggregation)
人类的注视具有预期性。例如,手还没动,眼睛已经看向了目标。作者通过对一个时间窗口内的热图进行加权平均,捕捉到了这种超前的规划信号。
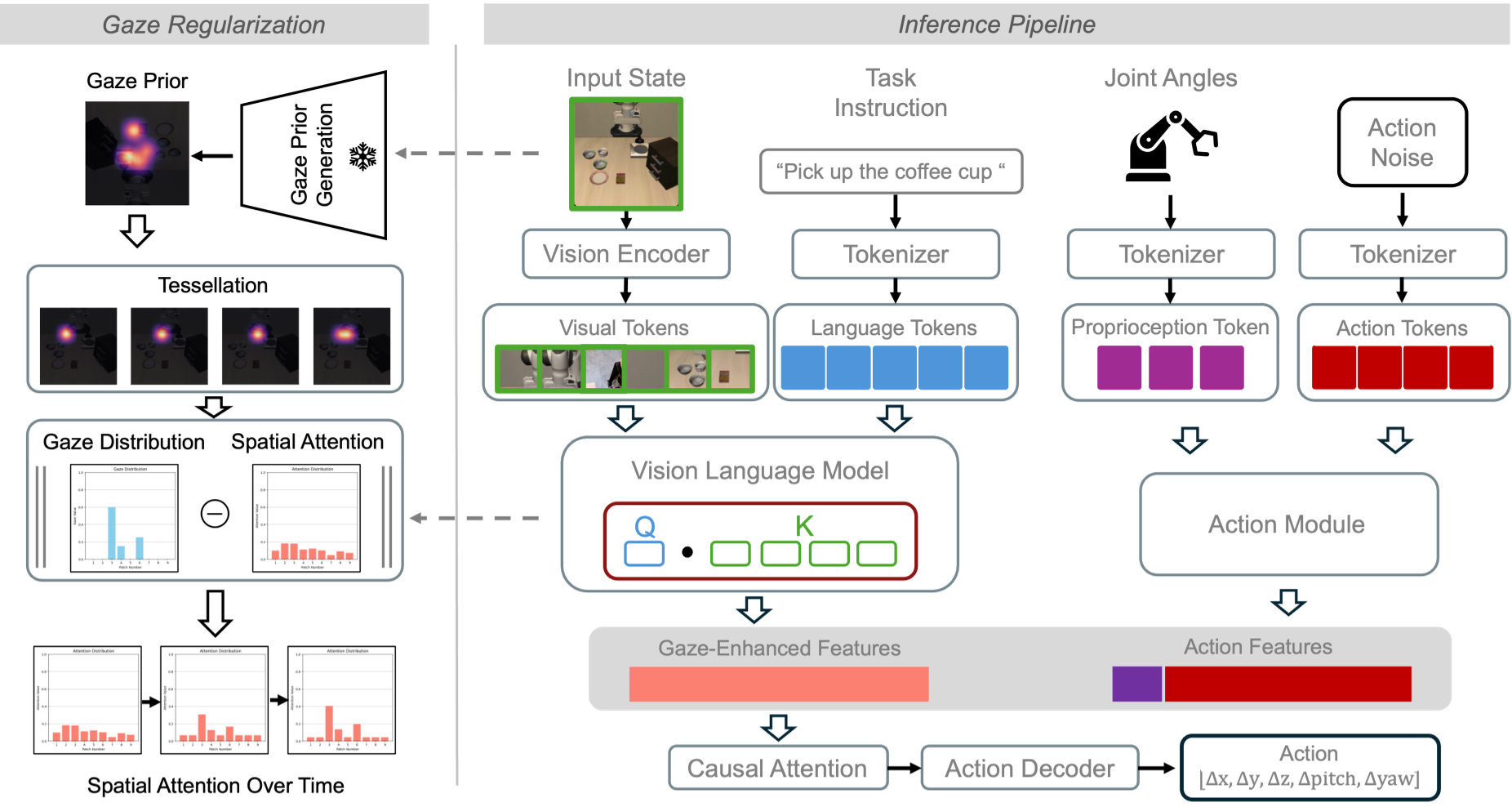 图 1:注视点正则化框架总览。左侧展示训练时的 KL 散度对齐,右侧展示推理时的注视无关操作。
图 1:注视点正则化框架总览。左侧展示训练时的 KL 散度对齐,右侧展示推理时的注视无关操作。
3. 注意力对齐 (Attention Minimization)
在模型训练期间,引入一个辅助损失函数 : 其中 是 Transformer 最后一层的内部注意力分布。这个 被设置为一个较小的值(0.001),作为一种软约束(Soft Constraint),引导模型关注人类关注的区域,同时保留模型探索任务特定模式的自由度。
实验战绩:更快、更准、更稳
1. 成功率的跨越式提升
在 LIBERO-Spatial 任务中,注视点正则化模型达到了 95.5% 的成功率,远超基线的 85.9%。最令人振奋的是,在训练初期(10k 步),该方法就已经展现出明显的性能优势,验证了其极高的样本效率。
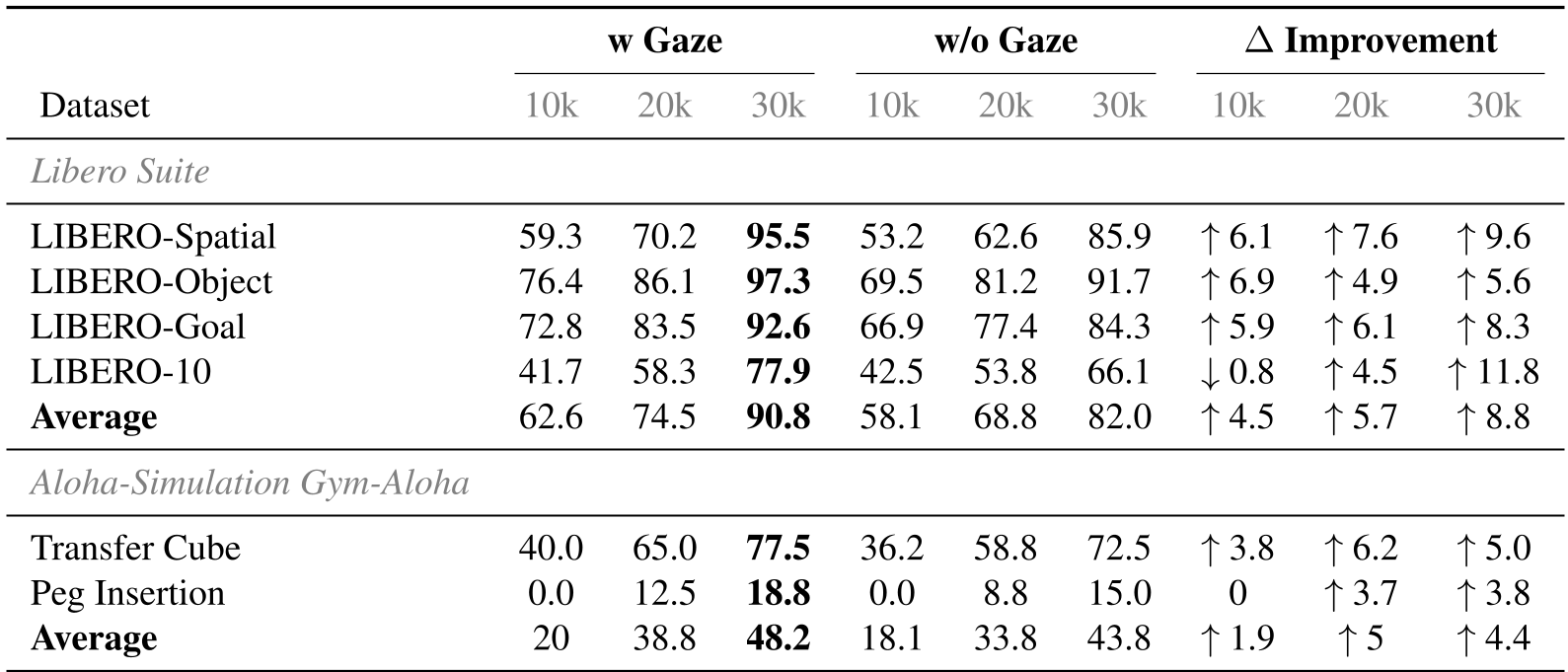 表 1:在不同 LIBERO 子集上的表现,注视点引导带来了全方位的领先。
表 1:在不同 LIBERO 子集上的表现,注视点引导带来了全方位的领先。
2. 极端环境下的稳健性
当面对刺眼光照或摄像头噪声时,普通模型容易“致盲”。但注视点正则化模型由于学会了锁定语义特征(如物体边界),其表现更为坚挺,在光照变化下的领先优势扩大到了 11.9%。
3. 可视化:机器人真的懂了
通过对比注意力图发现,基线模型的注意力非常分散(Diffuse),而正则化后的模型注意力精准地汇聚在操作物体和目标容器上,其视觉策略与人类高度一致。
 图 2:从左至右分别为原图、基线注意力、扰动注视注意力和本文方法的精准注意力。
图 2:从左至右分别为原图、基线注意力、扰动注视注意力和本文方法的精准注意力。
深度洞察:为什么这种简单的正则化有效?
- 信息瓶颈的优化:VLA 模型通常有数千个视觉 Token,正则化强制模型进行“有损压缩”,只保留对动作最关键的信息,从而显著减轻了动作头的解析压力。
- 解耦感知与规划:即使没有真实的眼动仪,合成注视也提供了一种“视觉显微镜”,让模型在学习动作逻辑之前,先通过预训练的视觉知识建立“空间重心”。
局限性与展望
尽管取得了显著提升,但该方法目前仍依赖于合成注视预测器。如果预测器出错(例如在极度密集的物体堆叠中),可能会产生负面偏置。未来的发展方向包括:
- 引入真实眼动数据:在大规模遥操作(Teleoperation)数据集中直接采集人类眼动。
- 多模态融合:将注视点与触觉、力反馈结合,构建全方位的具身先验。
总结
这项工作证明了:不需要更深的模型或更多的算力,仅仅通过更聪明地引导模型“看”图像,就能让机器人操纵性能产生质的飞跃。 这为未来的通用具身智能(Generalist Robot)提供了一个优雅且高效的性能增强方案。