The paper introduces Generalized Discrete Diffusion from Snapshots (GDDS), a unified framework for discrete diffusion modeling that supports arbitrary noising processes (e.g., semantic-informed) over large discrete state spaces. By employing uniformization for forward noising and a snapshot-based Evidence Lower Bound (ELBO) for training, GDDS achieves state-of-the-art results in language modeling, outperforming autoregressive (AR) models for the first time at this scale.
TL;DR
Generative modeling in discrete spaces has long been dominated by the Autoregressive (AR) "Next-Token Prediction" paradigm. While continuous diffusion (e.g., Stable Diffusion) revolutionized images, Discrete Diffusion has struggled with simplistic noise (masking/uniform) and inefficient training. Generalized Discrete Diffusion from Snapshots (GDDS) breaks these limits. By enabling arbitrary semantic noise and a simplified training objective, it surpasses AR models in character-level BPC and BPE-level perplexity for the first time.
Context: The Structural Blindness of Prior Work
The "noising" process in discrete diffusion is typically a Continuous-Time Markov Chain (CTMC). Until now, this process was largely restricted to Masking (replacing a token with [MASK]) or Uniform Replacement (replacing a token with a random one).
The problem? These methods are semantically oblivious. Replacing the word "Cat" with "Dog" should represent less "noise" than replacing it with "Toaster," yet standard discrete diffusion treats all transitions equally. Furthermore, previous training objectives tried to model the entire noising path, creating a high-variance signal that was difficult for bidirectional Transformers to digest.
Methodology: The Efficiency of Snapshots
GDDS introduces two breakthrough components to solve the flexibility and efficiency problems:
1. Arbitrary Noise through Uniformization
Instead of relying on simple closed-form matrices, GDDS uses Uniformization. This allows for the use of a Semantic-Informed Kernel (SIK). By calculating the distance between tokens in an embedding space (Gaussian or Cosine distance), GDDS can noise tokens by jumping to their "neighbors" first.
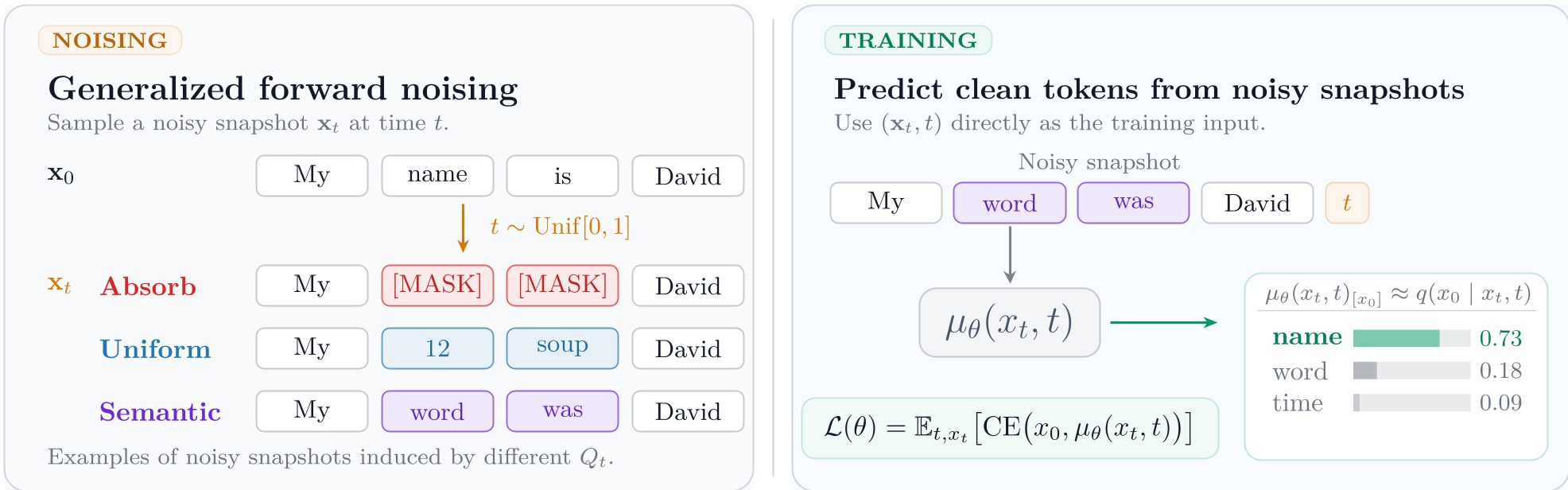
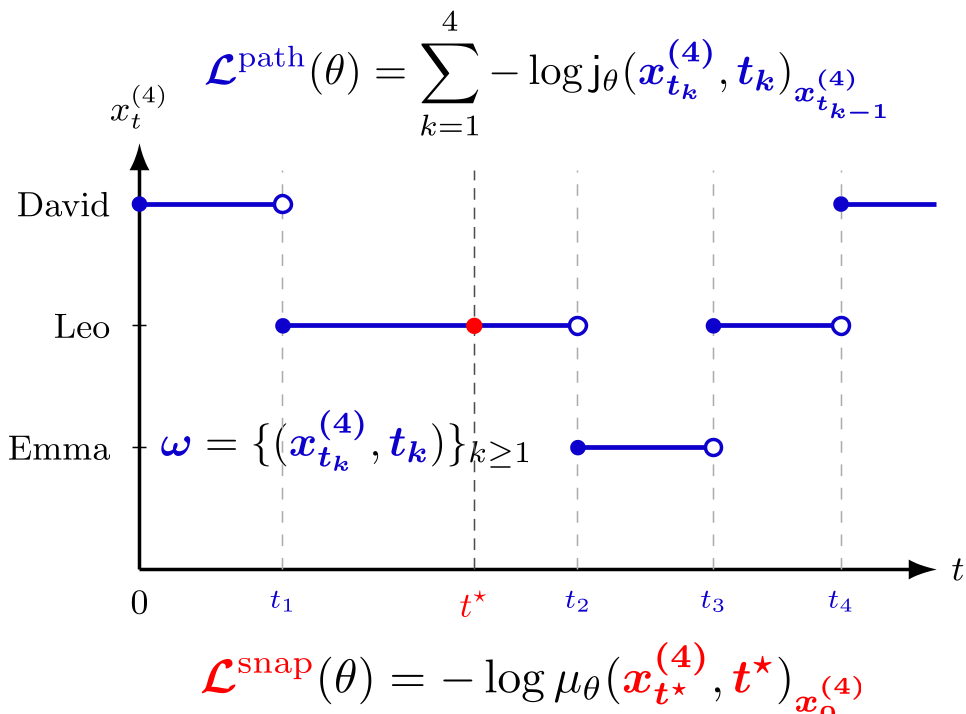
2. The Snapshot ELBO
The authors identify a "Core Mismatch" in reverse parametrization. While the real world follows a "path," deep learning architectures like Transformers prefer "snapshots" (static sequences at a specific time $t$). GDDS derives a Snapshot ELBO that proves minimizing the cross-entropy of predicting a clean token from a single noisy snapshot is a theoretically sound variational bound that is easier to optimize than the full path.
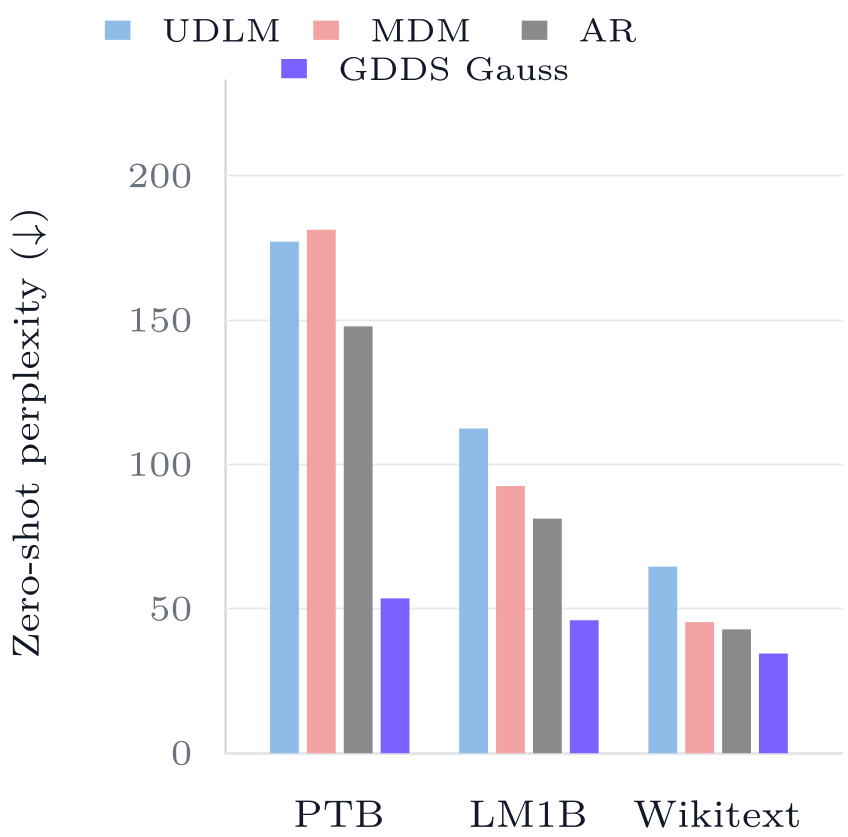
Experiments: Killing the AR Baseline
The results are striking. On the OpenWebText (OWT) dataset, GDDS with a Gaussian semantic kernel reaches a perplexity of 7.65, whereas the matched-compute Autoregressive baseline trails at 20.49.
Key Breakthroughs:
- Zero-Shot Generalization: GDDS Gauss shows significantly lower perplexity on unseen datasets (Wikitext, PTB, etc.) compared to masking models, suggesting that semantic noise induces better inductive biases.
- Generation Diversity: Unlike Uniform Diffusion (UDLM), which often suffers from mode collapse (low entropy), GDDS maintains a high-quality/diversity Pareto frontier.
Critical Insight: Why Does This Work?
The success of GDDS lies in the Information-Calibration Decomposition. The authors show that while path-wise training contains more information, it is significantly harder to calibrate. By sacrificing the complete path and focusing on snapshot calibration, GDDS allows standard Transformer backbones to "see" a clearer signal of what the original data looked like, leading to a much tighter variational bound.
Conclusion & Future Work
GDDS marks a turning point where Discrete Diffusion is no longer an "experimental alternative" but a superior competitor to AR modeling. The ability to use Semantic-Informed Kernels suggests that the next frontier will be "Next Semantic Scale Prediction," where the noising process itself is learned or tailored to the hierarchy of the data.
Limitations: Implementing Semantic-Informed Kernels currently requires $k$-Nearest Neighbor (KNN) approximations or KeOps for efficiency, which adds complexity to the sampling pipeline compared to simple masking.