本文提出了 GDDS (Generalized Discrete Diffusion from Snapshots),这是一个统一的离散扩散生成框架,支持在大规模离散空间(如语言模型)上进行任意形式的加噪。通过引入“快照” (Snapshot) 训练目标和基于均质化 (Uniformization) 的高效加噪算法,该方法在语言建模任务中首次在同等规模下超越了自回归 (Autoregressive) 模型,并显著优于现有的离散扩散 SOTA 方法。
TL;DR
长期以来,自回归(AR)模型一直是 NLP 领域的绝对霸主。尽管扩散模型在图像生成领域大放异彩,但在离散文本领域,它们往往受限于简陋的加噪方案(如[MASK]掩码)和低效的参数化方式。由来自法国的研究团队提出的 GDDS (Generalized Discrete Diffusion from Snapshots) 框架彻底改变了这一局面。它不仅支持任意复杂的加噪逻辑(例如:让“猫”更容易变成“狗”而非“汽车”),更通过一种优雅的“快照”训练目标,首次在同等规模下击败了 AR 模型。
1. 痛点:为什么离散扩散模型一直“差点意思”?
在文本生成中,目前的扩散大语言模型(dLLMs)通常只有两种套路:
- Masking(掩码):把词遮住,让模型猜。
- Uniform(均匀替换):把词随机换成词表里的任何一个词,让模型还原。
这种做法存在明显的 Inductive Bias(归纳偏置)缺失。在语言中,词与词是有语义距离的。此外,现有的模型在训练时,往往强行让神经网络同时负责“什么时候改变词”和“改变成什么词”,这给 Transformer 的学习带来了巨大的负担。
2. 核心机制:GDDS 的两大杀手锏
2.1 基于均质化(Uniformization)的高效加噪
如果你想设计一个“语义相关”的加噪过程(比如根据词向量的距离进行加噪),数学上需要计算巨大的矩阵指数,这在几万词表的 LLM 规模下是不可行的。
GDDS 巧妙地利用了均质化技术,避开了解析求解:
- 它将连续时间的加噪模拟为一系列离散的跃迁。
- 只需要访问转移速率矩阵(Rate Matrix)的列,就能实现快速加噪。
- 语义启发式内核 (SIK):作者基于 GPT-2 词嵌入计算余弦相似度,构建了 Gauss 加噪内核,实现了“语义邻域加噪”。
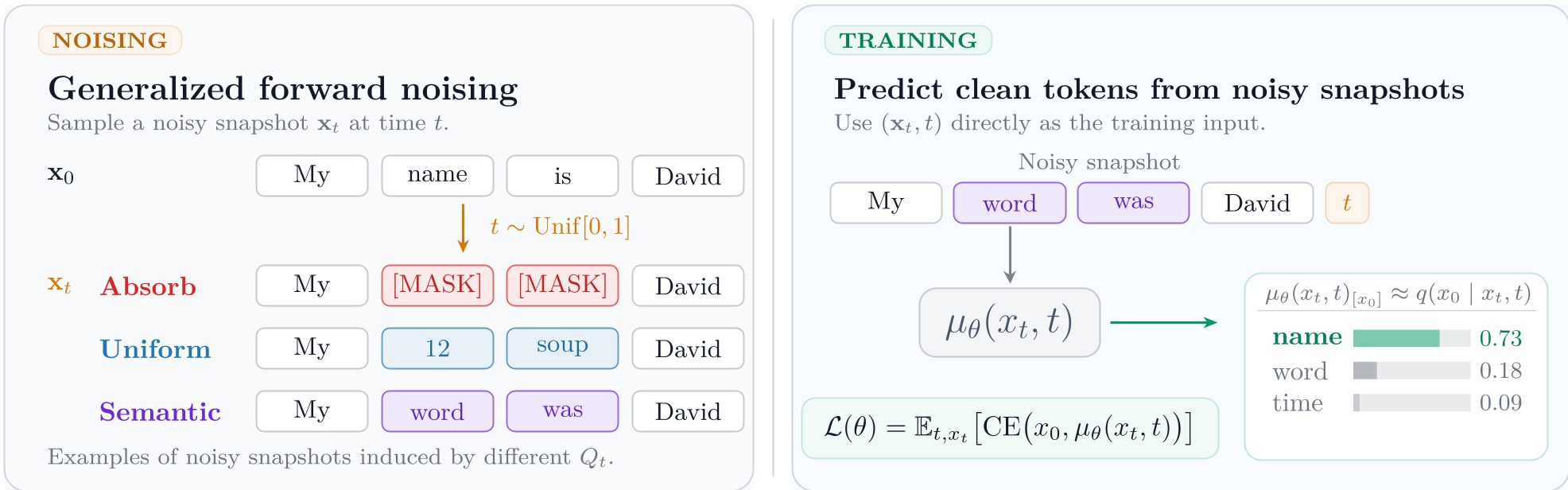 图 1:GDDS 流程。给干净序列 加噪得到快照 ,模型通过均值参数化直接预测 。
图 1:GDDS 流程。给干净序列 加噪得到快照 ,模型通过均值参数化直接预测 。
2.2 快照 ELBO (Snapshot ELBO):解耦与简化
作者提出了一个关键的洞察:不应该在整条噪声路径上训练模型。 相反,GDDS 训练模型在给定任意噪声状态 和时间 的情况下,直接预测原始序列 。这种“快照”目标在数学上被证明是一个合法的变分下界(ELBO),且极大地降低了训练方差。
3. 实验战绩:全线飘红
3.1 语言建模性能
在最核心的 OpenWebText (OWT) 实验中,GDDS Gauss 展现出了惊人的实力:
| 方法 | 模型规模 | PPL (↓) | | :--- | :--- | :--- | | Autoregressive (AR) | ~90M | 20.49 | | MDM (Masked Diffusion) | ~90M | 31.03 | | GDDS Gauss (Ours) | ~90M | 7.65 |
这意味着在相同的计算预算下,GDDS 的建模效率和准确性远超传统的 AR 模型和之前的扩散模型。
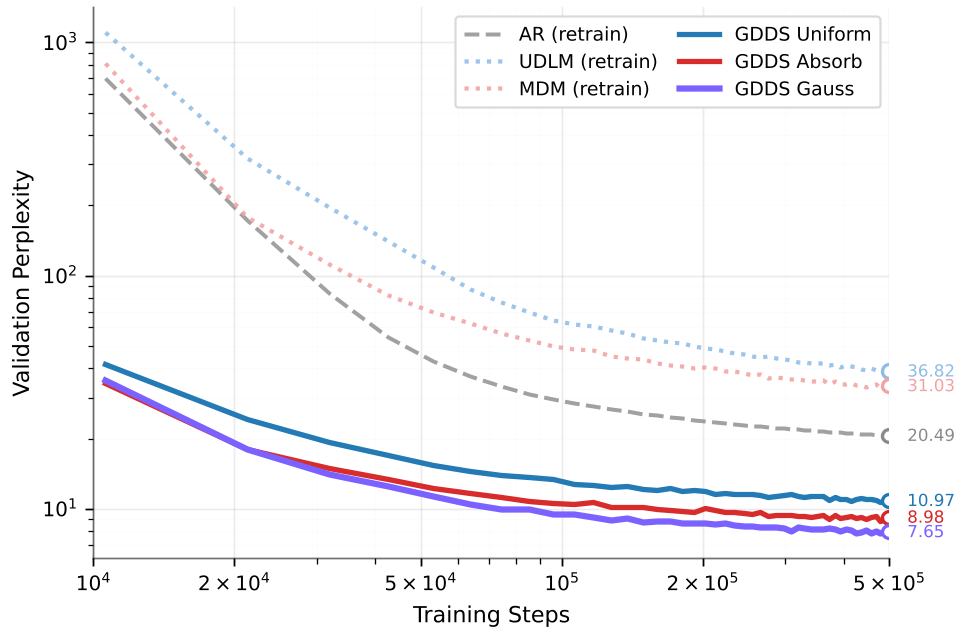 图 2:OWT 训练曲线,GDDS 系列(实线)的收敛速度和最终性能显著优于基线。
图 2:OWT 训练曲线,GDDS 系列(实线)的收敛速度和最终性能显著优于基线。
3.2 生成质量与多样性的权衡 (Quality-Diversity Tradeoff)
在图 5 的 Pareto 前沿分析中,GDDS 在保持高多样性(Entropy)的同时,实现了更低的 Generative Perplexity。尤其是 GDDS Absorb 形式,仅需 64 步采样就能达到传统 MDM 运行 1024 步的效果。
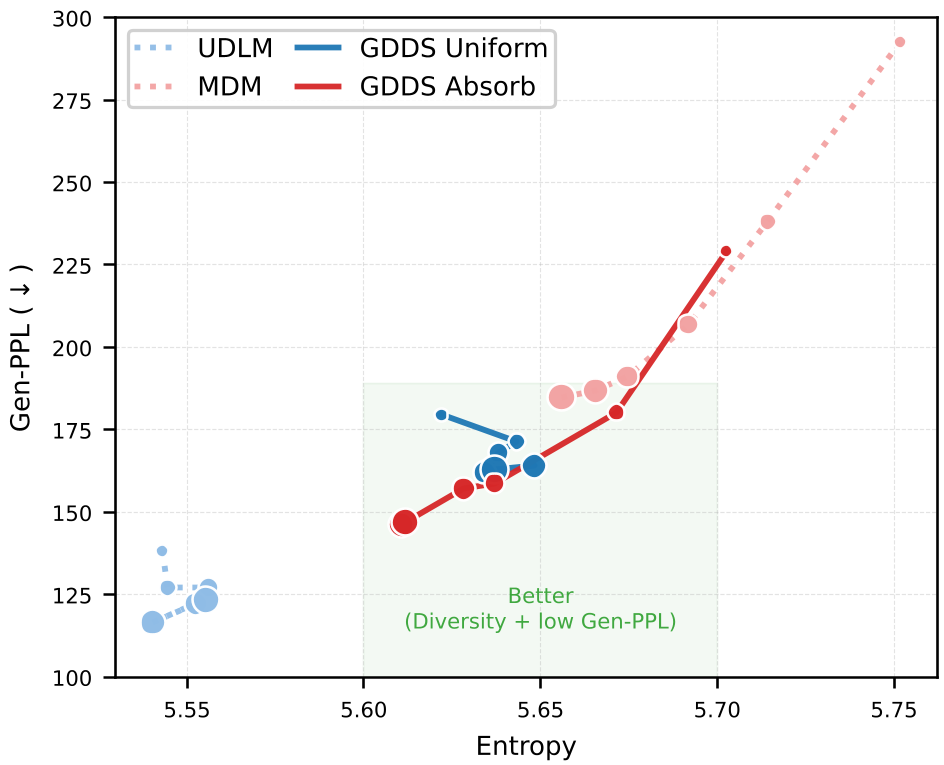 图 3:GDDS 在保持高熵(即生成不重复、多样化)的同时,拥有极佳的生成质量。
图 3:GDDS 在保持高熵(即生成不重复、多样化)的同时,拥有极佳的生成质量。
4. 深度洞察:为什么它能赢?
GDDS 的成功源于对离散扩散物理直觉的精准捕捉:
- 语义对齐:通过 SIK 内核,模型在训练时不仅在学习“去噪”,还在学习“语义流”。当模型看到一个被轻微干扰的词,它能利用语义近邻关系更快定位原词。
- 变分目标的纯净化:快照 ELBO 避免了传统扩散模型中路径积分带来的噪声。它让 Transformer 专注于最擅长的事——给定上下文预测标签。
5. 总结与未来展望
GDDS 的提出标志着离散扩散模型正式进入了可以与自回归模型正面硬刚的时代。尽管目前在 SIK 的采样效率上仍有优化空间,但其展示出的 建模上限 令人振奋。随着未来对语义启发式内核(SIK)的进一步精雕细琢,我们或许很快就能看到基于离散扩散的大规模非自回归实时对话模型。
Takeaway: 放弃死磕采样步数,先从重新设计加噪方式和简化训练目标开始,这才是离散扩散模型的正确打开方式。