GVC (Generative Video Codec) is a novel zero-shot video compression framework that repurposes pretrained video foundation models (like Wan 2.1) directly as codecs. By converting deterministic rectified-flow ODEs into stochastic SDEs, it enables codebook-driven trajectory replay, achieving high-quality reconstruction at ultra-low bitrates below 0.002 bpp.
TL;DR
Researchers have unveiled Generative Video Codec (GVC), a zero-shot framework that eliminates the need for training dedicated video compression models. By mathematically "hacking" pretrained video foundation models (like Wan 2.1), GVC transforms them into codecs where the bitstream directly dictates the generative trajectory. The result? Superior perceptual video quality at unprecedented bitrates—as low as 0.002 bpp.
Background: Beyond the Post-Hoc Patch
In the quest for ultra-low bitrate video, traditional codecs (HEVC/VVC) and even modern neural codecs eventually hit a "blur wall," where motion becomes muddy and textures vanish. To fix this, previous works used generative models as a refinement step—essentially a "post-processing" filter.
GVC rejects this hybrid paradigm. Instead of using a generative model to fix a broken reconstruction, it treats the generative model as the engine of the codec itself. The compressed data isn't a representation of pixels; it's a set of "steering instructions" for the model's stochastic sampling process.
Methodology: Turning ODEs into SDEs
Most modern video foundation models use Rectified Flow (RF), which solves a deterministic Ordinary Differential Equation (ODE). Determinism is great for generation but bad for compression—there’s no "gap" to insert compressed information into the trajectory.
1. The ODE-to-SDE Hack
The core insight of GVC is using Score-SDE theory to convert the deterministic path into a Stochastic Differential Equation (SDE). By adding controlled noise (stochasticity) back into the process at inference time, the authors create "injection points." These points are then filled with atoms from a reproducible codebook.
2. Three Strategies for the Rate-Distortion Frontier
GVC is not just one codec but a spectrum of three conditioning strategies:
- T2V (Text-to-Video): The "Zero-Anchor" mode. Only codebook indices are sent. It relies entirely on the model's internal prior.
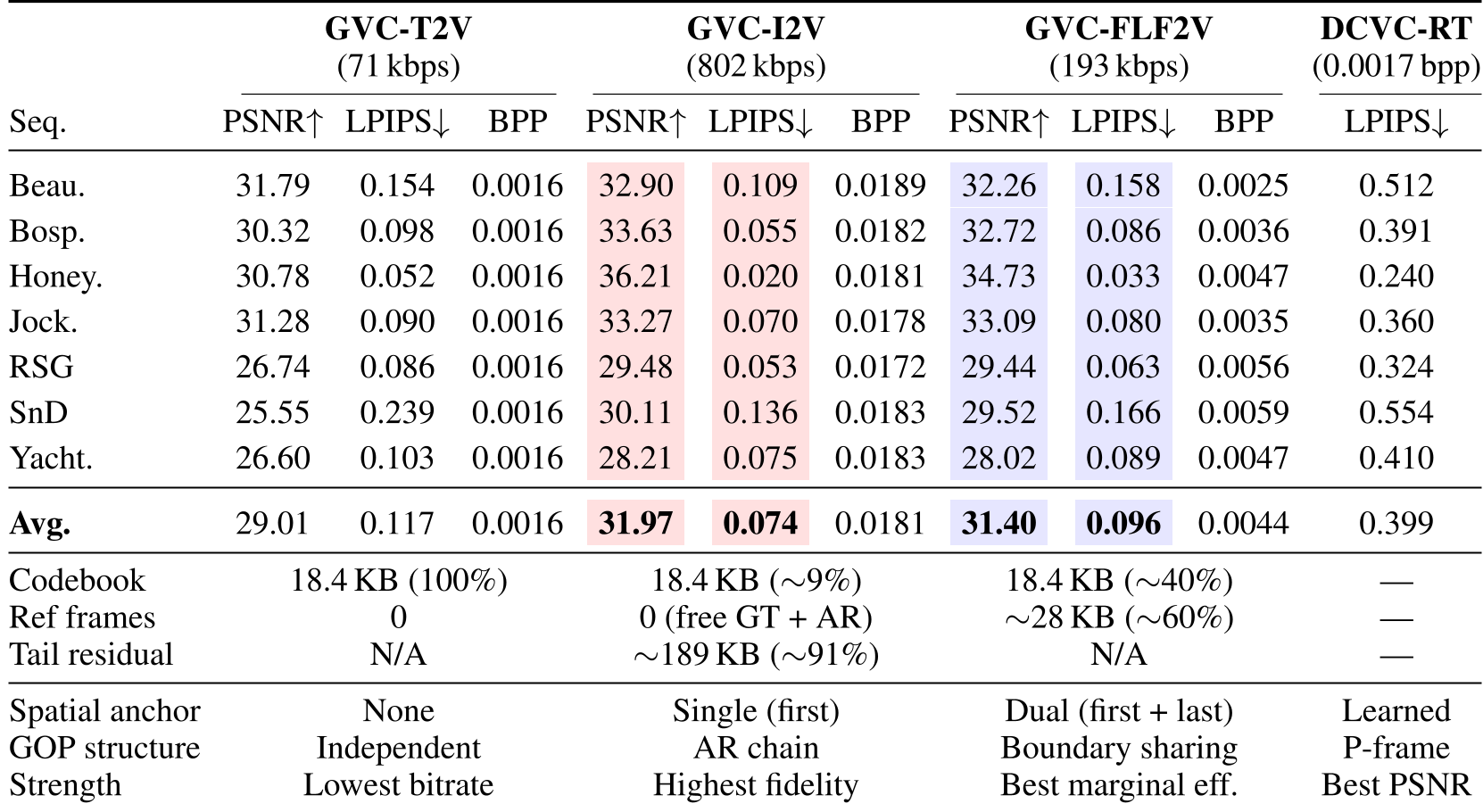
- I2V (Image-to-Video): Uses the first frame as a reference and employs Adaptive Tail-Frame Atom Allocation to prevent the "drift" that usually happens at the end of a video sequence.
- FLF2V (First-Last-Frame-to-Video): The "Dual-Anchor" mode. By compressing both the start and end of a Group of Pictures (GOP), it forces the model to interpolate, leading to much higher temporal stability.
Experimental Mastery
The authors conducted extensive ablation studies on the UVG dataset (1080p). The findings highlight a unique "sweet spot" for stochasticity: too little noise leaves no room for correction, while too much (high g_scale) overwhelms the codebook's ability to steer the trajectory.
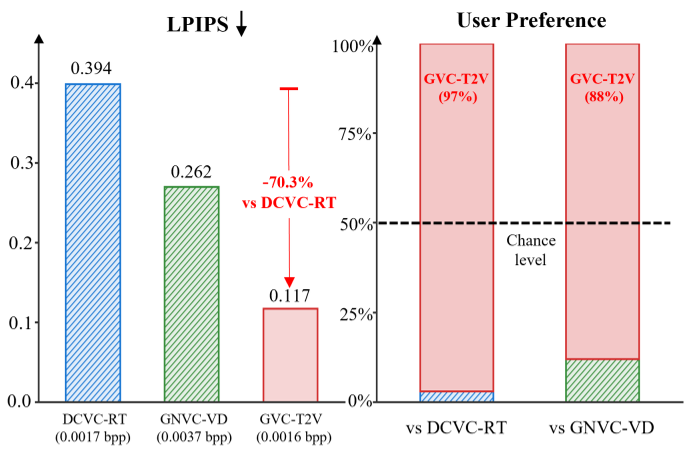
Key Metrics:
- Ultra-Low Bitrate: GVC-T2V operates at a staggering 71 kbps for 720p video.
- Perceptual Superiority: Even at lower bitrates, GVC variants maintain significantly lower LPIPS (perceptual loss) scores compared to DCVC-RT and traditional VVC, which suffer from severe artifacts in the same regime.
- Efficiency: The proposed Boundary-Sharing GOP chaining reduces reference frame overhead by 50%, making FLF2V a highly efficient middle ground.
Critical Insight: The Future of "Replay-Based" Coding
GVC represents a shift toward Semantic Communication. Instead of trying to precisely reconstruct every pixel (which is impossible at 0.002 bpp), we transmit the "spirit" of the motion.
Limitations:
- Complexity: Running a 14B parameter video model as a decoder requires high-end hardware (e.g., RTX 6000 Ada).
- Inference Time: Codebook-based sampling is slower than deterministic decoding.
Takeaway: As edge AI hardware matures, the "Generation Is Compression" philosophy will likely become the standard for satellite, deep-space, and low-bandwidth mobile communications, where the generative prior of a foundation model acts as the ultimate redundancy-remover.
Conclusion
By bridging the gap between Rectified Flow and Stochastic Sampling, GVC proves that we don't need to retrain models to achieve SOTA compression. We simply need to learn how to speak the model's language through the bitstream.