本文提出了 Geo3DPruner,一种针对 3D 场景理解任务中视频语言模型(VideoLMs)设计的几何引导视觉 Token 裁减框架。通过两阶段的几何感知策略,该方法在裁减 90% 的 Visual Tokens 的情况下,仍能保持原模型 90% 以上的性能表现,在多个 3D 场景理解基准测试上达到 SOTA。
TL;DR
针对 Multimodal LLMs 在处理 3D 空间视频时面临的“Token 爆炸”难题,北京航空航天大学等团队提出了 Geo3DPruner。它利用几何先验建模全局跨帧关联,通过体素内一致性裁减和体素间多样性选择,在极端裁减 90% Token 的情况下,依然能完美保留 3D 场景的结构特征。
背景定位
目前大模型理解 3D 世界的主流方案是“空间视频(Spatial Video)”,即将一系列带深度和位姿的 2D 图像喂给视频模型。然而,增加帧数提高精度的同时,Visual Token 数量呈指数级增长。现有的裁减策略(如 FastV)大多基于文本相关性或视觉显著性,但在 3D 任务中,这会导致系统“盯着同一个物体看”而丢失了背后的墙壁或周围的布局。
痛点深挖:视角一致性与空间多样性
在 3D 场景视频中,同一个桌子可能会出现在 10 帧图像中,这构成了巨大的视角冗余。传统的 Pruning 方法通常是帧内操作,无法识别这种跨越长时序的重复。此外,3D 任务(如 3D Grounding)要求模型必须看到场景的全貌,如果裁减算法只保留了视觉上最突出的物体(Intra-object bias),模型就会对整个空间的理解产生偏差。
方法论详解:几何引导的两阶段裁减
Geo3DPruner 的核心在于它不只是看像素,而是通过一个 3D 几何编码器(如 VGGT)来理解像素在 3D 空间中的真实位置。
1. 架构解析
模型并行运行 2D 视觉分支(SigLIP)和 3D 几何分支。通过几何分支预测的位姿和深度,将 2D 像素投影到 3D 空间中的**体素(Voxel)**上。
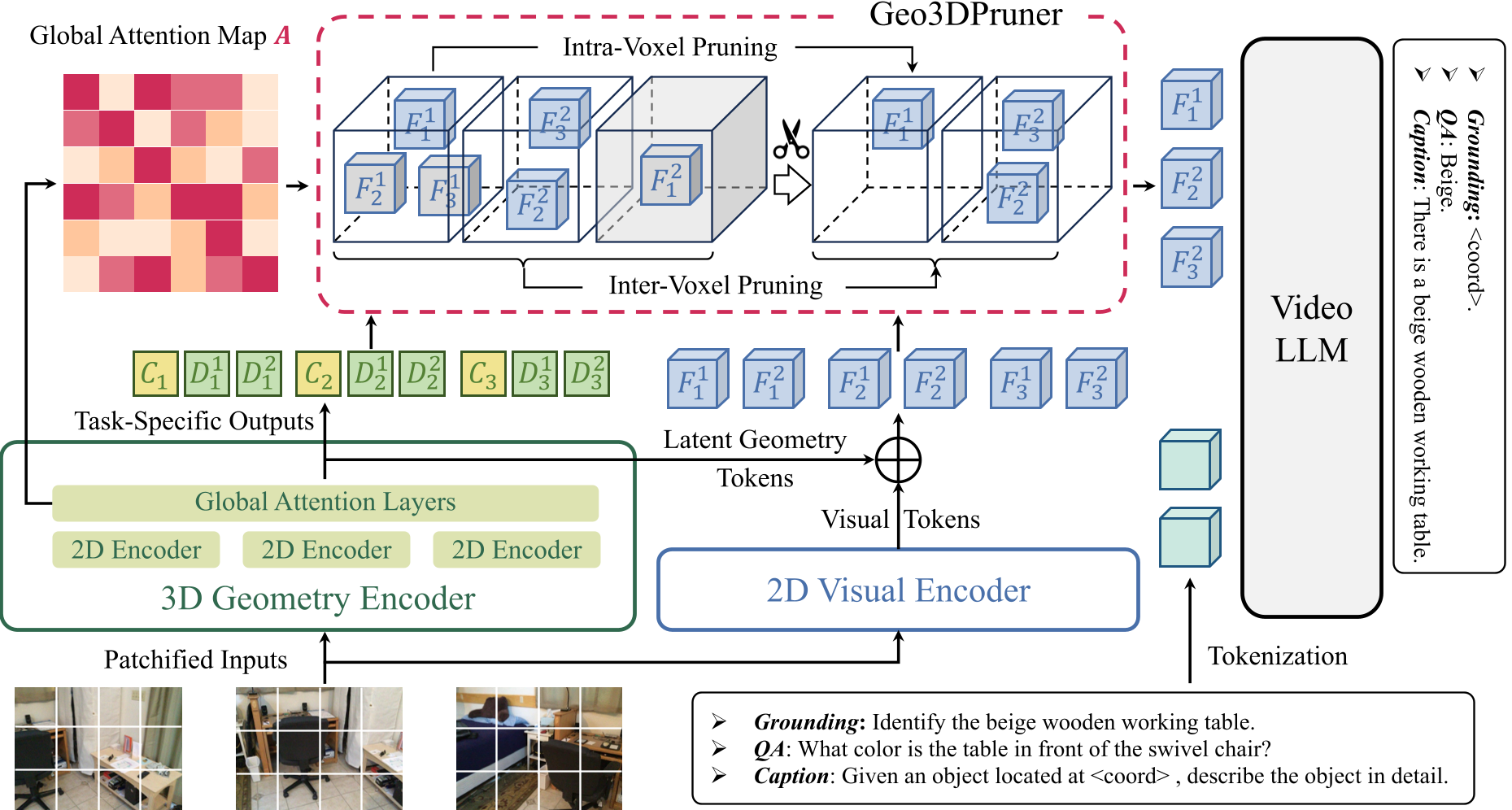
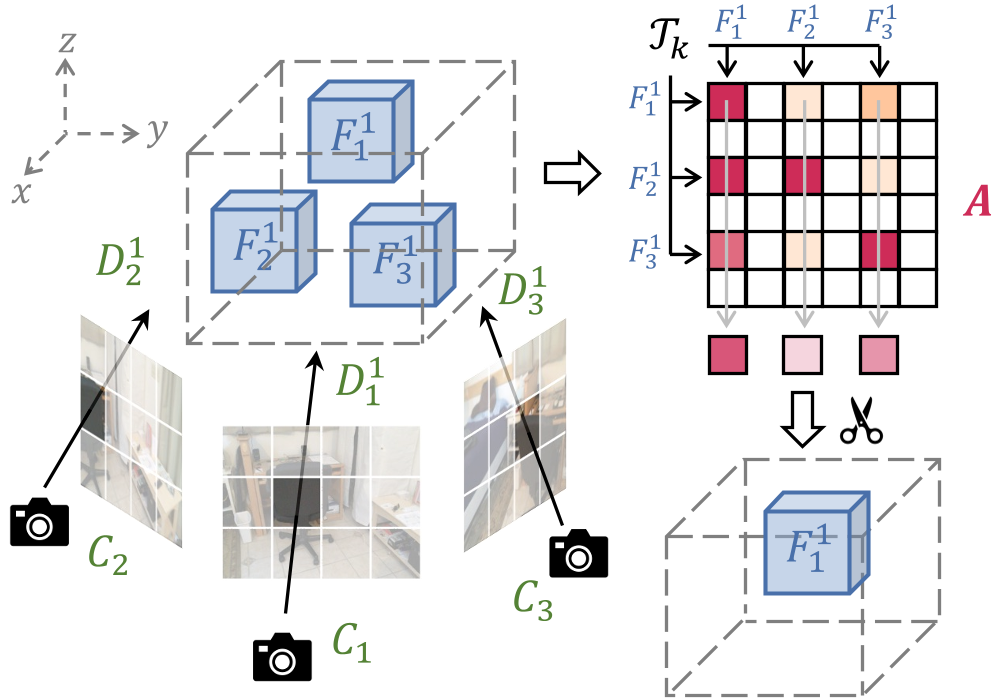
2. 两阶段裁减流程
- Intra-Voxel 阶段(视角一致性):对于投影到同一个体素的多个视角的 Token,计算它们的注意力得分。只保留最能代表该体素特征的 Top-α 比例的 Token。这有效消除了同一物体的多余观察。
- Inter-Voxel 阶段(空间多样性):这是一个“子集选择”问题。算法通过迭代搜索,评估体素间的全局重要性,采用一种启发式算法抑制重复关注同一物体,强制 Token 分布到场景的各个角落。
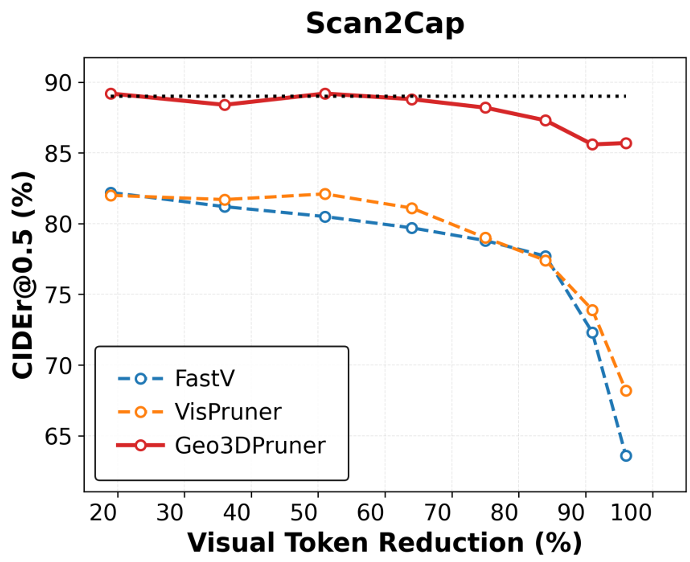
实验与结果
在 3D Dense Captioning(Scan2Cap)和 3D QA(ScanQA)等任务上,Geo3DPruner 展现了极强的性能韧性。
- 极高压缩比:在裁减 90% Token 时,平均性能保留率仍超过 90%,远超传统基于视觉或文本引导的方法。
- 打破“性能-效率”魔咒:通过在固定 Token 预算下使用更多帧物理信息配合裁减,Geo3DPruner 的精度甚至超过了不裁减但帧数少的 Base 模型(109% 性能提升)。
深度洞察与总结
Geo3DPruner 的成功表明,3D 场景理解不应被视为纯粹的视频序列问题,而应被视为空间采样问题。
Takeaway:
- 几何感知是关键:仅靠视觉特征(RGB)很难判断 Token 的冗余,只有映射回 3D 物理空间,才能真正看清数据的重复性。
- 多样性设计优于显著性设计:在空间推理任务中,覆盖“全”比关注“点”更重要,这是 Geo3DPruner 优于通用 Pruning 方法的本质原因。
局限性与展望:目前该架构依赖于预训练的几何编码器(VGGT),其计算开销在裁减过程中仍不可忽视。未来是否能将其简化为更轻量级的在线位姿估计,将是其走向实时端侧应用的关键。