本文提出了 Geo2,这是一个统一的交叉视角地理空间学习框架,旨在同时解决跨视角地理定位 (CVGL) 和双向图像合成 (CVIS) 任务。通过引入几何基础模型 (GFM) 如 VGGT 作为 3D 几何先验,Geo2 在 CVACT 测试集上实现了 Recall@1 提升 1.40%,在 VIGOR 跨区域设置下提升 5.01%,并同步刷新了图像合成的 SOTA 战绩。
TL;DR
交叉视角地理空间学习(Cross-view Geo-spatial Learning)长期以来面临定位(CVGL)与合成(CVIS)“各玩各的”尴尬局面。Geo2 通过引入几何基础模型(GFM)提取 3D 先验,构建了一个共享的“几何感知潜空间”。这不仅让模型在地理定位任务上打破了 SOTA 记录(VIGOR 跨区域 Recall@1 提升 5%),还实现了不需要重新训练即可进行双向(地面↔卫星)高质量图像合成。
1. 痛点:视点鸿沟与畸变难题
在地理空间学习中,最大的挑战在于“视角极其不对称”。地面图(Ground View)通常是宽视野的 Panorama,带有严重的球形畸变;而卫星图(Satellite View)则是俯瞰的正射影像。
- Prior Work 的局限:以往方法(如 SAFA, GeoDTR)依赖简单的极坐标转换或端到端特征匹配,缺乏对现实世界 3D 结构的理解。
- GFM 的引入:作者发现,利用 VGGT 等几何基础模型提取 3D 特征,可以提供稳健的几何约束,但难点在于如何处理全景图畸变以及如何让定位特征服务于生成。
2. Methodology:GeoMap 与 GeoFlow 的协作
Geo2 的架构设计遵循“理解促进生成,生成强化理解”的直觉。
2.1 GeoMap:消除畸变的 3D 嵌入
为了提取纯净的几何特征,GeoMap 引入了 E2P(Equirectangular-to-Perspective)转换。它将全景图切割成四个无畸变的透视裁剪图(Perspective Crops),分别喂入 VGGT 提取几何特征。
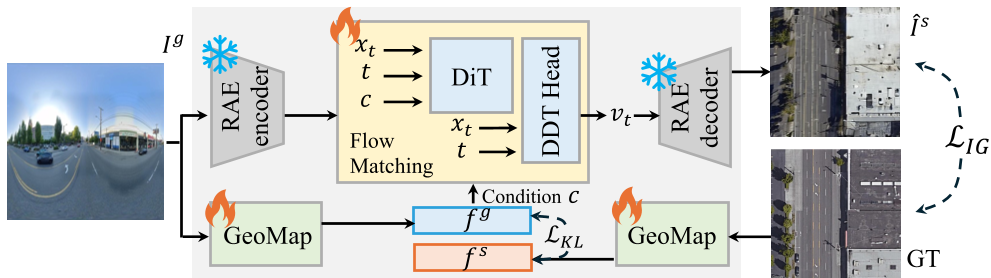 上图展示了 GeoMap 的双分支设计:通过 Cross-Attention 将语义 Token 与几何 Token 融合,最终输出对齐的潜嵌入 和 。
上图展示了 GeoMap 的双分支设计:通过 Cross-Attention 将语义 Token 与几何 Token 融合,最终输出对齐的潜嵌入 和 。
2.2 GeoFlow:双向生成的流匹配
不同于传统的 GAN 或扩散模型,Geo2 使用了 Flow Matching。这种方法直接建模两种分布之间的向量场。
- 可逆性:训练时只需要学习 G2S(地面到卫星),推理时通过反向求解常微分方程(ODE),就能直接实现 S2G(卫星到地面),极大地提升了效率和通用性。
3. 实验结果:全能选手的统治力
Geo2 在三大主流数据集(CVUSA, CVACT, VIGOR)上均展示了统治级别的表现。
3.1 性能飞跃
特别是在代表泛化能力的 Cross-Area(跨城市)设置下,Geo2 在 VIGOR 数据集上的提升最令人震撼:
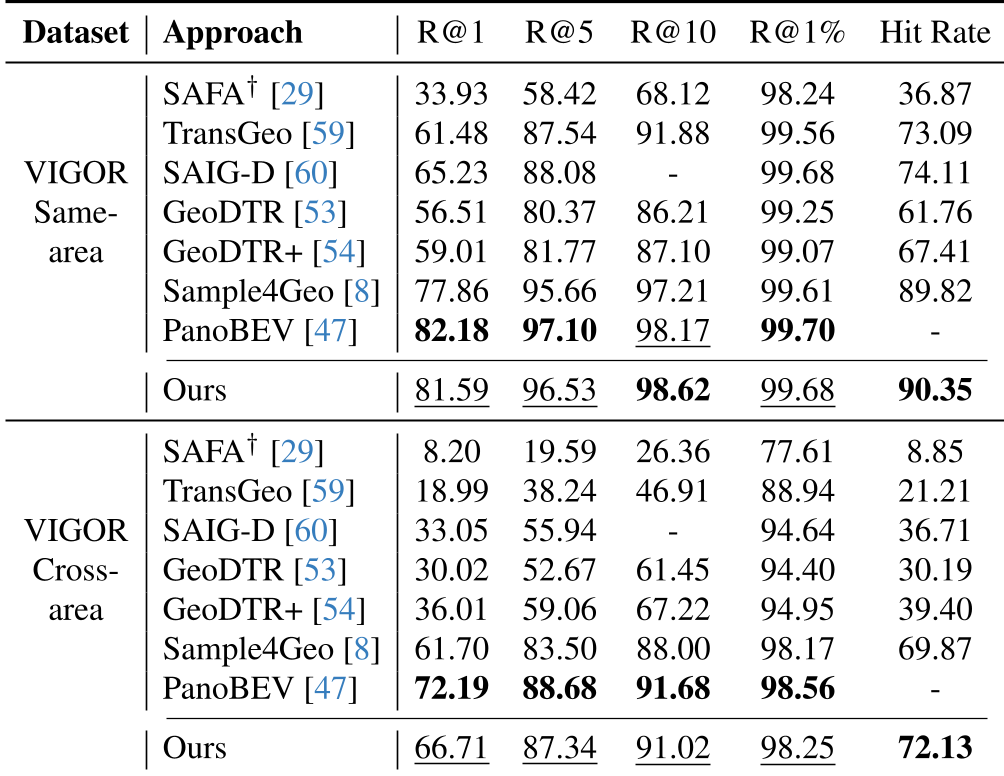 实验数据显示,Geo2 的 Recall@1 达到 66.71%,远超之前的强 baseline Sample4Geo。
实验数据显示,Geo2 的 Recall@1 达到 66.71%,远超之前的强 baseline Sample4Geo。
3.2 图像合成的“形神兼备”
生成的卫星图不仅纹理真实,更重要的是**几何布局(Road Orientation)**与原图高度一致。

4. 深度洞察:为什么联合训练有效?
Geo2 的成功核心在于 Consistency Loss(一致性损失)。 作者在训练后期联手 fine-tune GeoMap 和 GeoFlow,强迫定位用的潜嵌入必须包含足够的生成细节,同时也强迫生成逻辑遵循对齐的几何结构。这种“互锁”机制确保了潜空间既有区分性(定位),又有表达力(合成)。
5. 总结与未来展望
Takeaway:Geo2 证明了 3D 几何先验是跨视角任务的“通用语言”。
- 局限性:目前的合成任务虽然几何正确,但在处理极端动态目标(如行驶车辆)和精细纹理上仍有提升空间。
- 启发:这种将 Pre-trained GFM 作为 Feature Extractor 的范式,可能会很快推广到自动驾驶中的 BEV 感知和其他多视角融合任务中。
本文由资深学术技术主编解读,深入剖析论文核心逻辑。