本文提出了 GeoSR 框架,旨在增强多模态大语言模型(VLMs)在静态和动态场景下的空间推理能力。通过引入几何释放掩码(Geometry-Unleashing Masking)和几何引导融合(Geometry-Guided Fusion)机制,该方法显著提升了模型对 3D 几何特征的利用率,并在 VSI-Bench 和 DSR-Bench 两个主流空间推理榜单上刷新了 SOTA 纪录。
TL;DR
尽管当前的 Vision-Language Models (VLMs) 在图像语义识别上已近乎巅峰,但在回答“物体在 3D 空间中如何运动”、“两个物体的相对距离如何演变”等空间推理问题时却常常力不从心。新加坡国立大学提出的 GeoSR 框架,通过“强迫”模型放弃 2D 外观捷径并采用“自适应门控”融合 3D 几何 Token,在多个空间推理 Benchmark 上显著超越了 GPT-4o 和 Qwen2.5-VL 等强力基线。
背景定位:几何 Token 的“边缘化”危机
目前的 SOTA 方法通常从预训练 3D 基础模型(如 VGGT 或 π3)中提取隐含的几何 Token(Geometry Tokens),并将其与 2D 视觉 Token 拼接。然而,作者发现了一个反直觉的现象:这种简单的特征堆叠往往无效,甚至在动态场景下会起反作用。其本质原因是:VLM 太“赖”了。由于 2D 视觉特征包含了丰富的语义捷径,模型在微调过程中会自动忽略难以理解的几何 Token,导致这些珍贵的 3D 结构信息变成了冗余信号。
 图 1:在动态场景下,简单的几何注入(w/ Geo.)甚至不如完全不加几何特征的基线,显示了几何信息被低效利用的问题。
图 1:在动态场景下,简单的几何注入(w/ Geo.)甚至不如完全不加几何特征的基线,显示了几何信息被低效利用的问题。
核心算法:如何强制模型进行“深思熟虑”?
GeoSR 的核心改进在于两个模块的设计,旨在将几何信息从“辅助信号”提升为“核心证据”。
1. 几何释放掩码 (Geometry-Unleashing Masking)
为了打破模型对 2D 纹理和颜色的依赖,GeoSR 借鉴了 MAE(Masked Autoencoders)的思想。在训练阶段,模型会随机或基于相关性分数(Relevance Score)遮盖掉高达 80% 的 2D 视觉 Token。
- 直觉 (Intuition):当 2D 画面变得残缺不全时,模型无法再通过颜色或物体轮廓直接“猜”出答案,从而不得不转向未被遮盖的几何 Token 路径,学习如何从这些 3D 表征中提取深度、方位和运动信息。
2. 几何引导融合 (Geometry-Guided Fusion)
传统的特征融合通常是简单的加法或拼接。GeoSR 引入了一个由 LayerNorm 和 Sigmoid 激活函数 构成的轻量化门控机制 (Gate)。
- 计算公式:
- 这个门控是 Token-wise 且 Channel-wise 的。它允许模型在需要精确几何判断的像素区域(如物体重叠处或深处场景)通过门控显著放大几何流(Stream G)的权重。
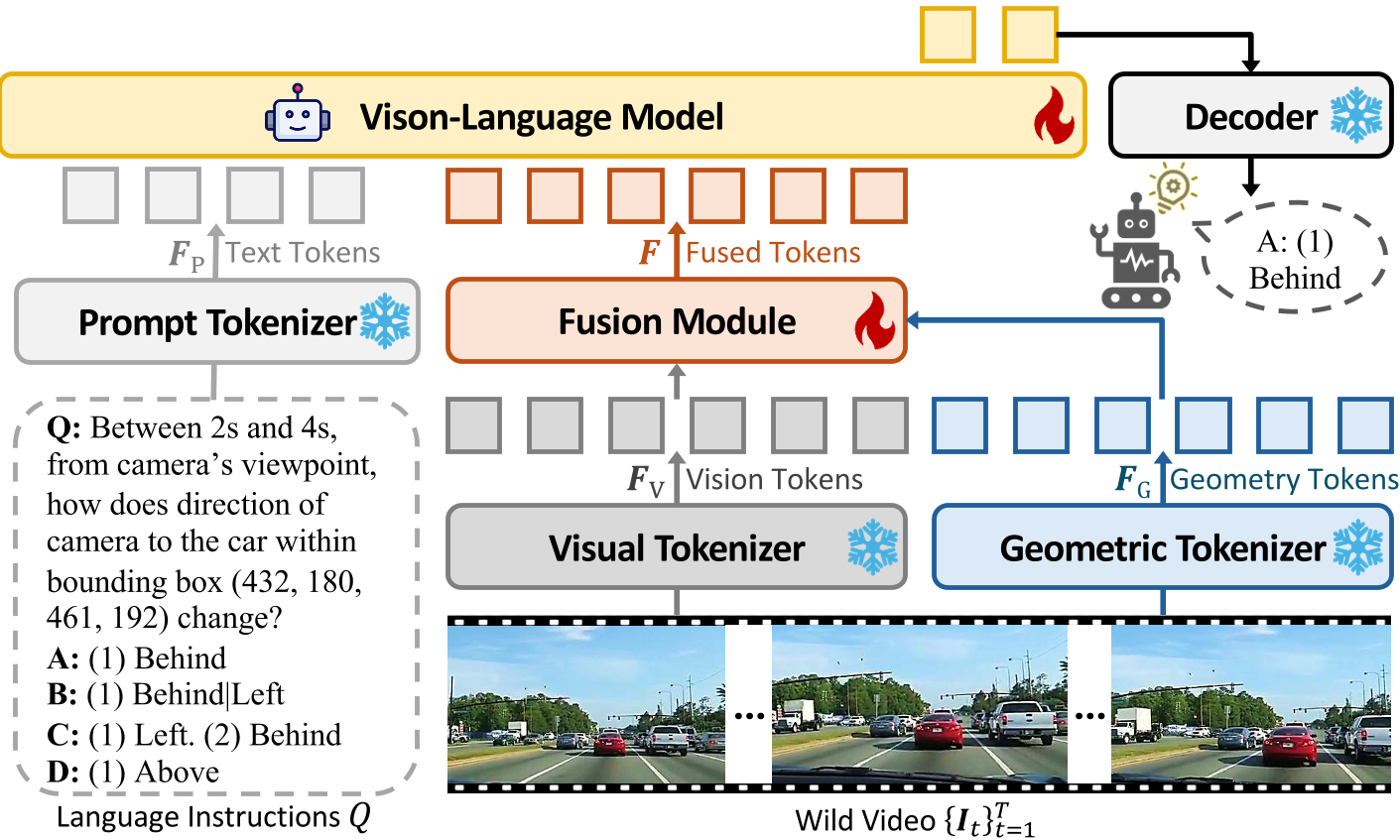 图 2:GeoSR 架构图。左侧为几何释放掩码(Masking),右侧为几何引导融合(Fusion)。
图 2:GeoSR 架构图。左侧为几何释放掩码(Masking),右侧为几何引导融合(Fusion)。
实验战绩:全线飘红
GeoSR 在静态(VSI-Bench)和动态(DSR-Bench)场景下均表现优异。
- 静态场景:在包含 288 个真实视频的空间 QA 任务中,GeoSR 相比 VG-LLM 提升了 1.2% 的平均准确率,尤其在相对方向(Rel. Dir.)判断上提升明显。
- 动态场景(4D 推理):这是 GeoSR 的高光时刻。在 DSR-Bench 上,GeoSR 取得了 66.1% 的平均分,大幅领先前任 SOTA 模型 GSM(58.9%)。
- 消融实验验证:如果不加 Masking,模型性能会下降 1.2% 到 2.1%;如果不加 Gated Fusion,性能更是全面缩水。这证明了“强迫学习”与“精细融合”缺一不可。
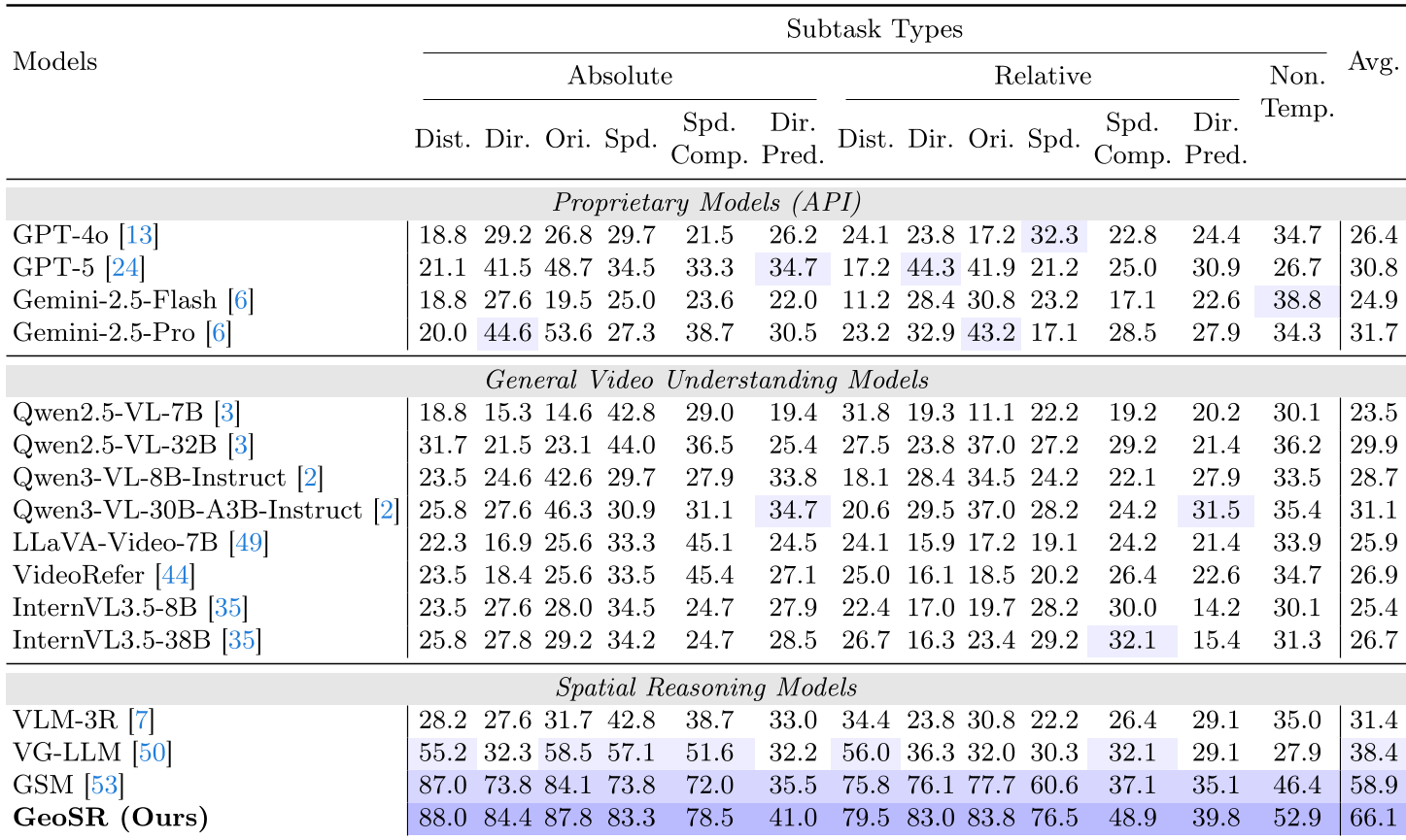 图 3:GeoSR 在动态空间推理榜单上的统治力表现,多项指标遥遥领先。
图 3:GeoSR 在动态空间推理榜单上的统治力表现,多项指标遥遥领先。
深度洞察:空间推理不仅仅是语义对齐
GeoSR 的成功给我们带来了几个关键启示:
- 数据的本质:当前的 VLM 训练大多是在学习“看图说话”,这是一种强关联的语义匹配。但真正的空间推理需要通过几何约束进行逻辑演绎。
- 掩码的威力:掩码不再仅仅是一种预训练手段,在微调阶段它同样可以作为一种有效的归纳偏置(Inductive Bias),迫使多模态模型在多个输入流之间进行非平衡的学习。
- 未来的挑战:诚如作者在局限性中所述,目前的 Benchmark(如图 6, 7 所示)仍存在标注歧义。实现真正的 4D 物理世界理解,不仅需要更强大的 GeoSR,也需要更具物理一致性的高质量数据集。
总结: GeoSR 为 VLM 的空间进化提供了一套简洁且极具效率的方案。它告诉我们,要让 AI 拥有 3D 直觉,与其不停地给它喂更多数据,不如在训练时先“遮住它的双眼”,逼它用灵魂去感受几何。