Glove2Hand is a generative framework designed to translate multi-modal sensing glove videos into photorealistic bare-hand videos of hand-object interactions (HOI). It utilizes a novel surface-grounded 3D Gaussian hand model and a diffusion-based restorer to achieve SOTA video fidelity (FVD) and realism.
Executive Summary
TL;DR: Glove2Hand is a pioneering framework that solves the "appearance gap" in Hand-Object Interaction (HOI) research. It transforms videos of bulky sensing gloves into photorealistic bare-hand interactions while keeping the underlying physical sensor data (IMU/tactile) perfectly synchronized. By combining Surface-Grounded 3D Gaussians for consistency and Diffusion Restorers for texture, it enables the creation of HandSense, the first dataset providing measured tactile signals for bare-hand vision tasks.
Positioning: This work moves beyond simple image-to-image translation. It provides a robust "data engine" that converts high-fidelity physical signals (available only via gloves) into high-fidelity visual data (required for bare-hand models), achieving SOTA results in contact estimation and occluded tracking.
Problem & Motivation: The Multi-Modal Dilemma
In the quest to understand how humans manipulate the world, we face a trade-off:
- Vision-Only: Great for appearance, but bad at "seeing" force/contact and prone to occlusion.
- Sensing Gloves: Provide perfect IMU and tactile data but look nothing like human hands, making models trained on them useless for real-world egocentric cameras.
The authors identify that existing generative models struggle with two key issues: temporal consistency (flickering in translated videos) and complex geometry (handling squishy or unknown objects). Glove2Hand was born from the insight that "while the skin looks different, the underlying skeleton is the same."
Methodology: Reconstruct, Then Refine
The Glove2Hand pipeline is a sophisticated two-stage process that leverages the strengths of both 3D reconstruction and generative modeling.
1. The Surface-Grounded 3D Gaussian Hand
Instead of using standard Gaussian Splatting which can be "floaty," the authors anchor 3D Gaussians directly onto a canonical hand mesh using barycentric coordinates.
- Why? This provides a strong geometric prior. When the hand moves, the Gaussians move with the mesh triangles, ensuring perfect temporal consistency.
- Relighting: By utilizing the mesh surface normals, the model can estimate lighting via Spherical Harmonics (SH), allowing the hand to "fit" into different lighting environments.
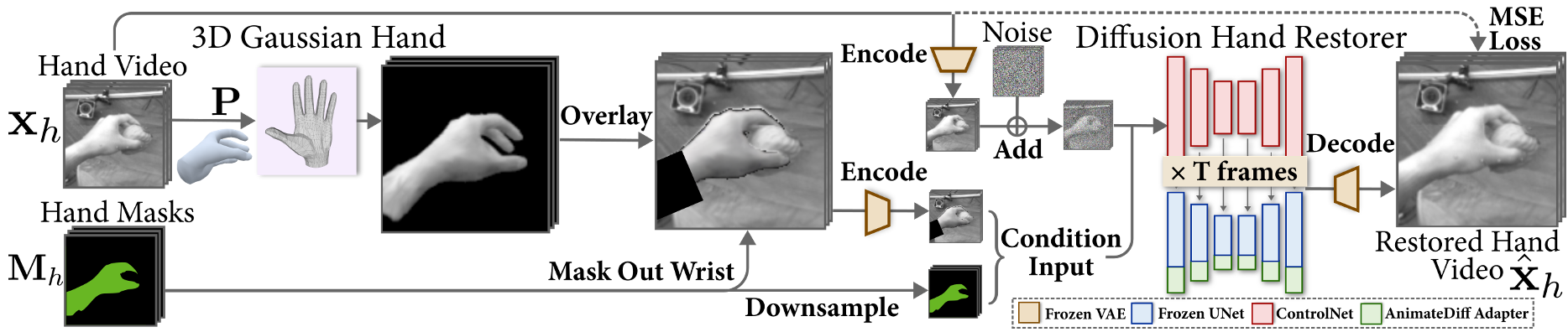
2. Diffusion Hand Restorer
The 3D render provides the "skeleton," but the Diffusion Restorer provides the "soul." Based on ControlNet and AnimateDiff, this module:
- Fuses the rendered hand into the background.
- Refines the wrist connection (often missing in hand-only models).
- Polishes contact regions where the hand meets the object, resolving penetrations or gaps.
Experimental Results: Proving the Value
Quantitative Dominance
Glove2Hand was tested against baselines like CycleGAN, Pix2Pix, and HandRefiner. It achieved a FID of 30.1 and FVD of 19.5, significantly outperforming diffusion-only or translation-only methods.
Breakthrough Applications
The true value lies in the HandSense dataset created using this tool.
- Contact Estimation: By using the glove's tactile sensors as "ground truth" and the synthesized bare-hand video for training, the vision model reached an 88.2% Contact IoU.
- Occlusion Handling: When tracking hands under heavy occlusion (where cameras fail but IMUs don't), the error (MKPE) dropped from 19.2mm to 16.6mm thanks to the synthesized training data.

Critical Analysis & Conclusion
Takeaway: This work effectively turns sensing gloves into "invisible" data collection tools. We can now collect rich physical interaction data without ruining the visual data required for training egocentric vision models.
Limitations:
- The inference speed is currently 0.5 FPS, which is too slow for real-time applications.
- The quality still depends heavily on the accuracy of the initial pose estimation and the quality of the object segmentation masks (SAM-2).
Future Outlook: Glove2Hand opens the door to "Physically-Grounded Foundation Models" for HOI. As the framework evolves to handle "in-the-wild" subjects more robustly, we could see massive synthetic datasets that teach AI not just what a hand looks like, but how it feels the objects it touches.