GroupEditing is a novel training-based framework designed for consistent and unified modifications across multiple related images using a pseudo-video reformulation. By leveraging a pre-trained video diffusion model (WAN-2.1) and integrating explicit geometric correspondences from VGGT, it achieves state-of-the-art performance in local/global editing and identity preservation.
TL;DR
Editing a single image is easy; editing a set of images—like photos of the same product from different angles—while keeping the changes perfectly consistent is incredibly hard. GroupEditing solves this by treating an image group as a "pseudo-video" and injecting explicit geometric cues into a video diffusion transformer. By using two new flavors of Rotary Positional Embeddings (Ge-RoPE and Identity-RoPE), the model ensures that an edit applied to one view propagates correctly to every other view, regardless of rotation or pose.
Problem & Motivation: The Consistency Gap
Current SOTA editing tools (like InstructPix2Pix or MasaCtrl) typically struggle with "Group-Image Editing." If you ask them to put a "robotic armor" on a fox across five different photos, the armor's design will shift slightly in every frame.
The root of the problem is twofold:
- Lack of Dense Correspondence: Standard attention mechanisms understand that a "face is a face," but they lose track of specific pixels when an object rotates or deforms.
- Data Scarcity: Most datasets focus on single-image editing or video sequences, not diverse static views of the same object.
The authors' insight? Video models already know how things move. By feeding an image group into a video model, we can exploit pre-learned "temporal coherence" to bridge the gap between static views.
Methodology: Fusing Implicit Priors with Explicit Geometry
The GroupEditing framework operates on a WAN-2.1 video diffusion backbone. To turn this video model into a group editor, the authors introduce a dual-path correspondence system.
1. Geometry-enhanced RoPE (Ge-RoPE)
While video models have "implicit" consistency, they need "explicit" help for complex geometry. The authors use VGGT (Visual Geometry Grounded Transformer) to extract dense matching features. They then warp the spatial grid based on these features and inject them into the transformer using Ge-RoPE. This aligns the latent tokens with the actual geometric structure of the scene.
2. Identity-RoPE
To keep the "identity" of an object (like a specific character's face) stable, the authors propose Identity-RoPE. It calculates a bounding rectangle for the target object and normalizes the positional encodings within that box. This forces the model to treat the object the same way, regardless of where it appears in the frame.
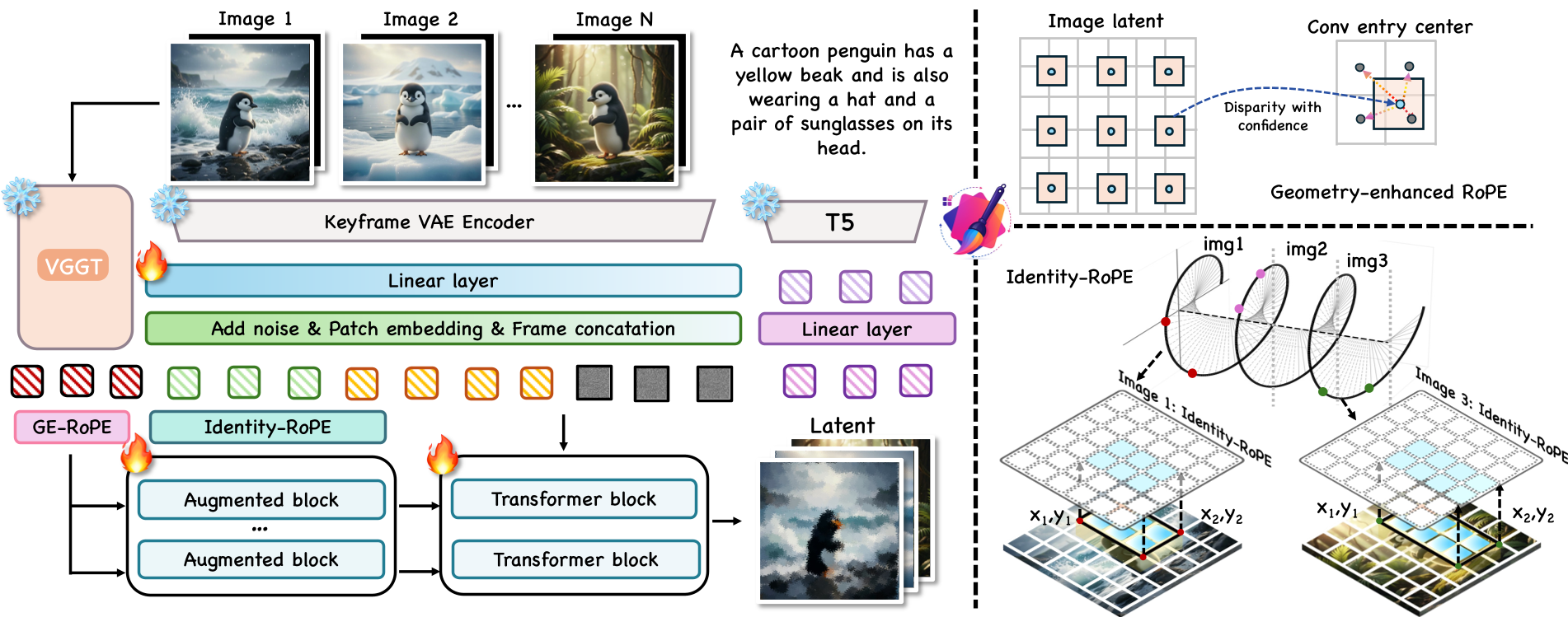 Figure: The GroupEditing pipeline showing the fusion of VGGT tokens and the two RoPE variants.
Figure: The GroupEditing pipeline showing the fusion of VGGT tokens and the two RoPE variants.
GroupEditData: Scaling Up
A significant contribution of this paper is GroupEditData, a dataset of 7,500+ high-quality image groups. The authors used Gemini 2.5 to generate related image sets and a rigorous filtering pipeline (segmentation + aesthetic scoring) to ensure the data was clean enough for training a robust group-editing model.
Experiments: Superior Quality and Consistency
GroupEditing was tested against heavyweights like Edicho, Anydoor, and OminiControl.
- Qualitative Mastery: Whether it's changing the style of a jeep across multiple landscapes or adding armor to a character, GroupEditing maintains a level of structural and textural fidelity that previous methods lack.
- Downstream Power: Because the edits are so consistent, the output can be used directly for 3D Reconstruction (using Must3R). If the edits were inconsistent, the 3D model would fail to align the points.
 Figure: Comparison of GroupEditing against SOTA methods in local and global editing tasks.
Figure: Comparison of GroupEditing against SOTA methods in local and global editing tasks.
Critical Analysis & Conclusion
Takeaway
The core value of GroupEditing lies in its representation choice. By moving from "independent images" to "pseudo-video," the authors successfully unlocked the latent geometric reasoning capabilities of modern video transformers.
Limitations & Future Work
The method heavily relies on the quality of masks and initial geometric correspondences (VGGT). In cases of extreme occlusion or completely unrelated backgrounds, the consistency might still degrade. Future research could look into iterative refinement where the model "self-corrects" its geometric understanding during the denoising process.
GroupEditing sets a new bar for digital commerce and virtual content creation, where maintaining a "single source of truth" across multiple images is paramount.