This paper introduces Group3D, a training-free multi-view open-vocabulary 3D object detection framework. It leverages Multimodal Large Language Models (MLLMs) to perform semantic grouping of 2D fragments, achieving state-of-the-art zero-shot performance on ScanNet and ARKitScenes without requiring 3D supervision or ground-truth depth.
TL;DR
The inability to distinguish between a "table" and the "floor" using only incomplete 2D images is a classic failure mode in multi-view 3D detection. Group3D solves this by using an MLLM (like GPT-5) to act as a "semantic gatekeeper." By grouping synonymous terms and separating structurally distinct ones before merging 3D fragments, it achieves a massive +20% mAP boost over previous benchmarks like Zoo3D in zero-shot settings.
Problem & Motivation: The Geometry-Only Trap
Existing multi-view open-vocabulary detectors usually follow a "Geometry First, Semantics Later" pipeline. They lift 2D segments into 3D space and merge them based on spatial overlap.
However, in pure RGB settings (without LiDAR), depth estimation is noisy. If a chair is right next to a desk, their fragments often overlap geometrically. A purely geometric algorithm sees one big "blob" and merges them. Once merged, it’s nearly impossible for a downstream classifier to "un-stick" them. The authors recognize that semantic knowledge (knowing that a chair is not a desk) should be a prerequisite for merging, not an afterthought.
Methodology: The Architecture of Group3D
Group3D operates through a sophisticated memory-based pipeline that bridges 2D observations and 3D reasoning.
1. Scene Memory Construction
- Scene Vocabulary Memory: The model queries an MLLM (GPT-5.1) across views to build a list of objects present.
- 3D Fragment Memory: 2D masks from SAM are back-projected into 3D space using depth and pose estimation.
2. Semantic Compatibility Grouping
This is the core innovation. The MLLM doesn't just list objects; it partitions the vocabulary into Compatibility Groups.
- Compatible: {
chair,sofa,couch}. These represent the same physical object under different labels. - Incompatible: {
wall,door}. These might be close together but are physically distinct.
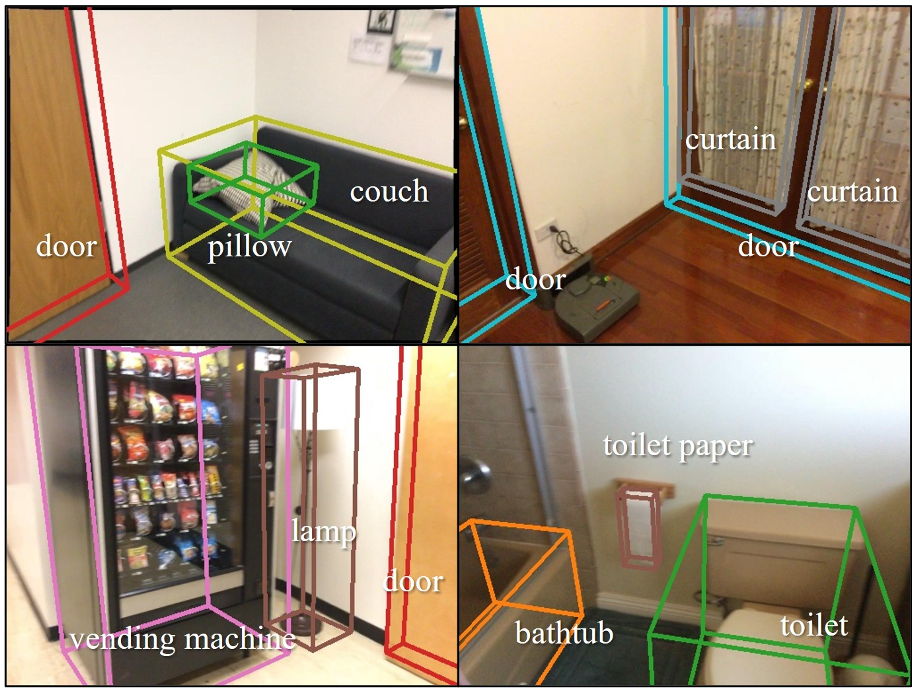 Figure 1: The Group3D framework integrates MLLM-driven semantic groups to gate the 3D fragment merging process.
Figure 1: The Group3D framework integrates MLLM-driven semantic groups to gate the 3D fragment merging process.
3. Group-Gated Merging
During the merging phase, two fragments $F_i$ and $F_j$ are merged ONLY IF:
- They satisfy the Semantic Condition: $g(\ell_i) = g(\ell_j)$ (they belong to the same group).
- They satisfy the Geometric Condition: Their voxel-level intersection-over-union (IoU) or containment ratio exceeds a threshold.
This "Semantic Gate" prevents the irreversible fusion of semantically distinct but spatially adjacent objects.
Experiments & Results
Group3D tested on ScanNet and ARKitScenes, showcasing its dominance in the multi-view RGB domain.
- ScanNet20: Achieved 51.1% mAP25, a staggering leap from the 19.8% of OpenM3D.
- Pose-Free Robustness: Even when the camera's position is unknown (relying on SfM-style reconstruction), Group3D hits 41.2% mAP25, proving that semantic gating can "fix" noisy geometry.
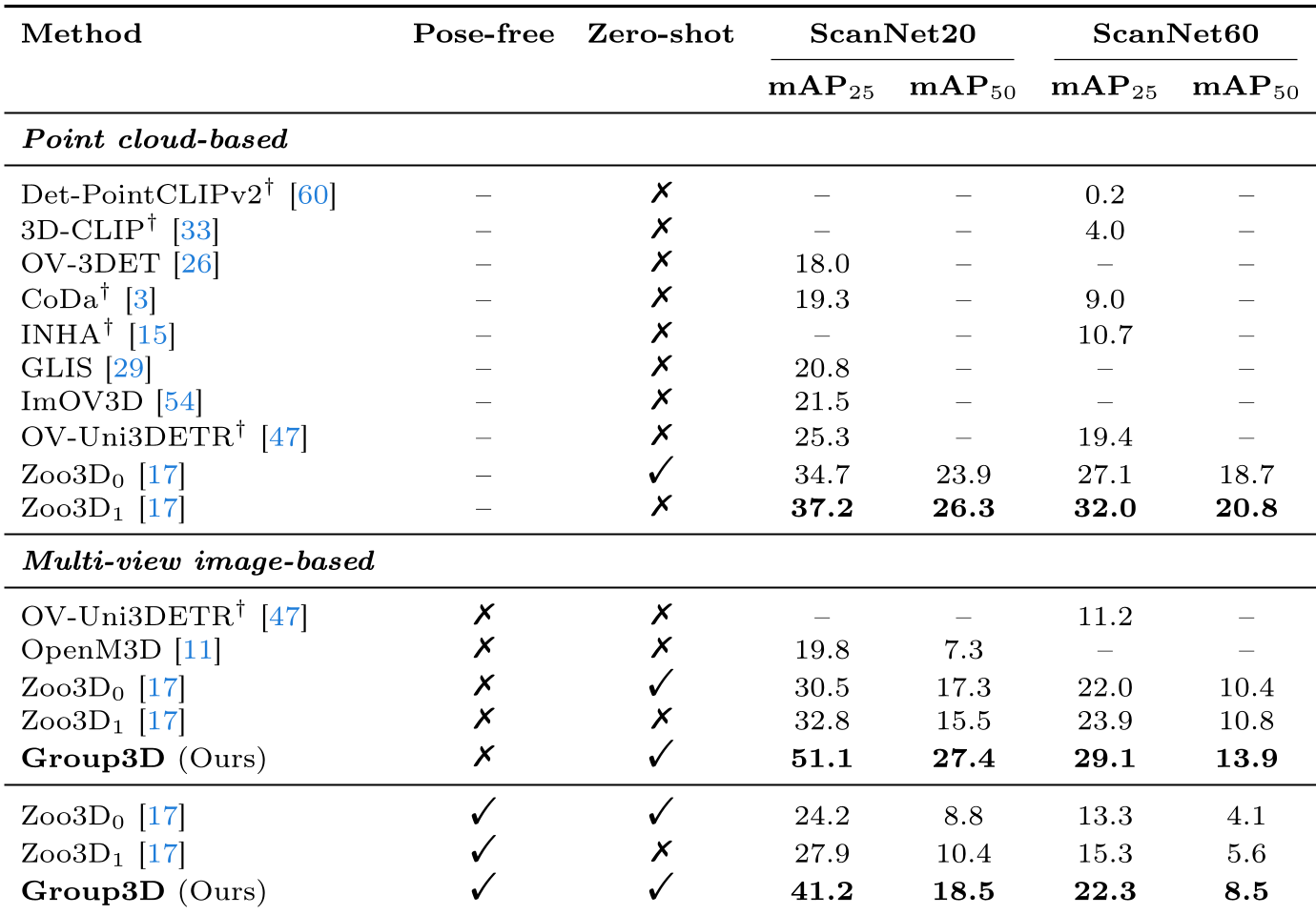 Table 1: Quantitative comparison showing Group3D's significant lead in both pose-known and pose-free settings.
Table 1: Quantitative comparison showing Group3D's significant lead in both pose-known and pose-free settings.
Ablation Insight: Why Grouping Matters?
The ablation study (Table 5) reveals that merging by "Same Category" is too strict (missing matches due to label noise), whereas "No Category" (Geometry Only) is too loose. Semantic Compatibility Grouping strikes the perfect balance by allowing lexical variation (e.g., merging "trash bin" with "waste basket") while maintaining physical boundaries.
Critical Analysis & Conclusion
Takeaways
Group3D proves that MLLMs are no longer just for "labeling" results—they can be used as structural logic inside the perception pipeline. By using language to resolve geometric ambiguity, the model handles long-tail categories and noisy depth maps much better than traditional algorithms.
Limitations
- Computational Overhead: Relying on per-frame MLLM queries can be slow for real-time applications.
- Dependency on Foundation Models: The performance is bounded by the quality of the 2D segmentor (SAM) and the reconstruction model.
Future Work
The next frontier is likely moving from static semantic grouping to dynamic scene reasoning, where the MLLM understands the relationships between objects (e.g., "the cup on the table") to further refine 3D instance boundaries.
For more details, visit the project page: https://ubin108.github.io/Group3D/