GSMem is a zero-shot embodied exploration and reasoning framework that utilizes 3D Gaussian Splatting (3DGS) as a persistent spatial memory. By enabling "Spatial Recollection," the agent can render photorealistic novel views from optimal viewpoints to support high-fidelity Vision-Language Model (VLM) reasoning, achieving SOTA results on OpenEQA and GOAT-Bench.
TL;DR
GSMem revolutionizes how robots "remember" their environment. By replacing static photo-logs with 3D Gaussian Splatting (3DGS), it allows agents to virtually "re-visit" any location from the best possible angle, even if they never stood there. This "Spatial Recollection" capability leads to a new SOTA in zero-shot embodied reasoning and navigation.
The "Lived-In" Memory Gap: Why Current Robots Forget
Most embodied AI systems today suffer from a "perspective lock." They remember the world as a collection of snapshots (view-based) or a simplified list of objects (graph-based).
- The Issue: If a robot glides past a "white robe" but the camera is slightly tilted or the lighting is poor, that object is lost forever in a graph-based memory. In a snapshot-based memory, the VLM is forced to reason using a blurry, low-res crop from a suboptimal angle.
- The Insight: Humans use mental imagery to reconsider past scenes. GSMem brings this to robotics by using 3DGS to create a persistent, continuous radiance field that can be re-rendered on demand.
Methodology: The Architecture of Recollection
GSMem functions through three core pillars: Mapping, Retrieval, and Hybrid Exploration.
1. Online 3DGS Mapping & Language Fields
Unlike traditional 3DGS which requires offline training, GSMem uses a sliding-window optimization to update the geometry in real-time. Crucially, it "lifts" 2D CLIP features onto the 3D Gaussians using a weight-consistent reverse aggregation—effectively creating a searchable 3D semantic map without heavy computational overhead.
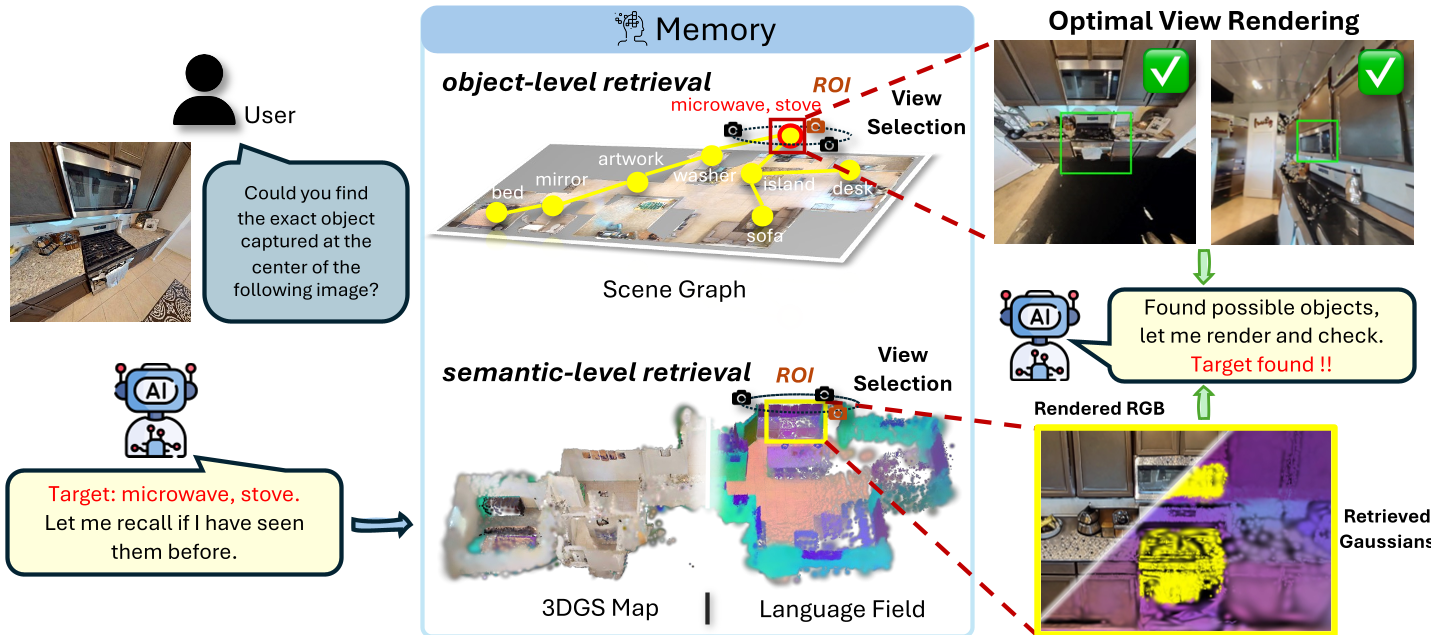
2. Multi-Level Retrieval & Optimal View Synthesis
When asked "Where is the ficus tree?", GSMem doesn't just look at its object list. It performs:
- Object-level retrieval: Scouting the 3D scene graph.
- Semantic-level retrieval: Querying the continuous CLIP language field.
Once a region is localized, the agent samples 108 candidate viewpoints and ranks them based on visibility (TSDF check), projected area, and rendering opacity. The winner is rendered to provide the VLM with a "perfect" view for reasoning.
3. Hybrid Exploration: Balancing Logic and Geometry
The agent chooses its next move based on two factors:
- Semantic Score: Does this direction look like it leads to the goal?
- Geometric Coverage: Is this area poorly mapped? GSMem uses the trace of the Fisher Information Matrix (FIM) to quantify "uncertainty" in the 3DGS parameters, pushing the agent to fill in visual gaps.
Experiments: Setting a New Standard
GSMem was tested on OpenEQA (Active Embodied QA) and GOAT-Bench (Lifelong Navigation).
Performance Highlights
- OpenEQA: GSMem achieved an LLM-Match of 55.4, outperforming the previous best (3D-Mem) by nearly 3 points.
- GOAT-Bench: In lifelong scenarios where memory retention is key, GSMem reached a 67.2% Success Rate, a significant leap over the 62.9% of its closest competitor.

Case Study: Overcoming Perception Failures
The paper highlights instances where standard object detectors (like Grounded-SAM) failed to label a "white robe" or "white door." While other agents failed these tasks, GSMem's Language Field allowed it to find the regions via semantic similarity, and its re-rendering capability allowed the VLM to confirm the target from a generated "hallucinated" optimal viewpoint.
Deep Insight: Moving Beyond Discretization
The true value of GSMem isn't just the higher success rate—it's the shift in philosophy. By treating memory as a differentiable, continuous radiance field rather than a discrete database, we allow the "reasoning" part of the AI (the VLM) to ask for structural evidence that wasn't explicitly saved during the initial pass.
Limitations & Future Work
- Computational Cost: While optimized, 3DGS optimization and VLM querying still hover around 1.2s per step.
- Dynamic Environments: Currently, GSMem assumes a static world. Extending 3DGS to track moving objects in real-time remains a high-frontier challenge.
Final Takeaway: GSMem proves that for embodied AI, how you remember is just as important as what you see. 3D Gaussian Splatting is no longer just for pretty graphics; it is a powerful, searchable backbone for robotic "consciousness" and spatial reasoning.