本文针对华为昇腾(Ascend)NPU 硬件架构,深入研究了超低精度 FP4 预训练技术。核心贡献是系统评估了 HiFloat4 (HiF4) 这种新型 4 位浮点格式,在 Pangu、Llama3 及 Qwen3-MoE 等大模型上实现了高达 90% 的计算与存储 FP4 化,且 loss 偏差控制在 BF16 基线 1% 左右。
TL;DR
随着大语言模型(LLM)进入万亿参数时代,算力能耗已成为不可逾越的鸿沟。华为团队在最新的研究中证明,通过名为 HiFloat4 (HiF4) 的分层 4 位浮点格式,可以在昇腾 NPU 上实现约 90% 的训练计算全 FP4 化。相比主流的 MXFP4 格式,HiF4 在 Llama3 和 MoE 架构上展现出了极佳的数值稳定性,将精度损失控制在 1% 以内,同时大幅降低了显存压力。
核心动机:FP4 训练的“不可能三角”
在深度学习预训练中,追求极低比特(Low-bit)量化往往面临三个矛盾:数值动态范围、表示精度以及硬件计算效率。
- MXFP4 依赖 32 元素的块缩放,但在处理某些具有长尾分布的梯度(Outliers)时,容易产生严重的截断误差或精度坍塌。
- NVFP4 虽然在 NVIDIA Blackwell 架构上表现强劲,但其复杂的小块缩放逻辑在特定 ASIC 或 NPU 上可能带来额外的元数据管理开销。
- 软件补丁开销:为了让 FP4 跑通,前人通常加入随机舍入(SR)、随机 Hadamard 变换(RHT)和各种 Truncation-free 方案。这些操作往往在 FP16/FP32 下进行,如果处理不当,会产生严重的“低精度计算,高精度补丁”的性能折损。
技术深潜:HiFloat4 的分层缩放魔法
HiF4 格式的设计直觉在于:利用硬件原生的分层元数据来模拟更宽的动态范围。
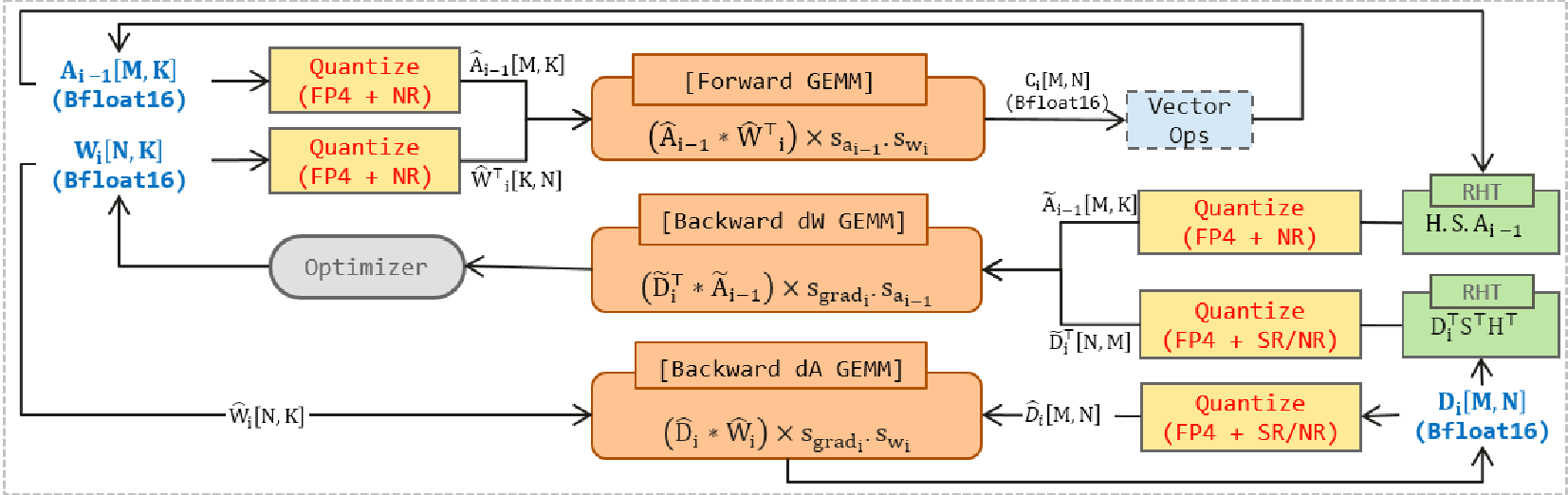
1. 三级分层缩放 (Hierarchical Scaling)
HiF4 将 64 个元素组成一个大块。与 MXFP4 简单的全局缩放不同,HiF4 采用了:
- L1 级:8-bit E6M2 指数位,提供粗粒度的全局基准。
- L2/L3 级:引入 1-bit 的微指数(Micro-exponents),针对块内的 8 路或 16 路子模块进行微调。 这种设计允许在同一个 64 元素块内,既能照顾到极大的异常值(Outliers),也能保留小值的精度,其 amortized 过载仅为 0.5 bit/value。
2. 稳定化组合拳:RHT 与 SR
在反向传播计算权重梯度 时,由于梯度波动剧烈,极易溢出。
- RHT (Random Hadamard Transform):通过正交变换将张量能量均匀化,打破离群值的垄断,使得量化误差更均匀。
- SR (Stochastic Rounding):HiF4 在 HiF4 下的表现非常有趣——实验发现 HiF4 甚至不需要 SR 即可稳定收敛,而 MXFP4 则必须依赖 SR 来抵消由于 nearest rounding 带来的系统偏差。
实验战果:MoE 模型的极致压缩
作者在 OpenPangu-1B、Llama3-8B 和 Qwen3-MoE-30B 上进行了 50B Tokens 的严苛测试。
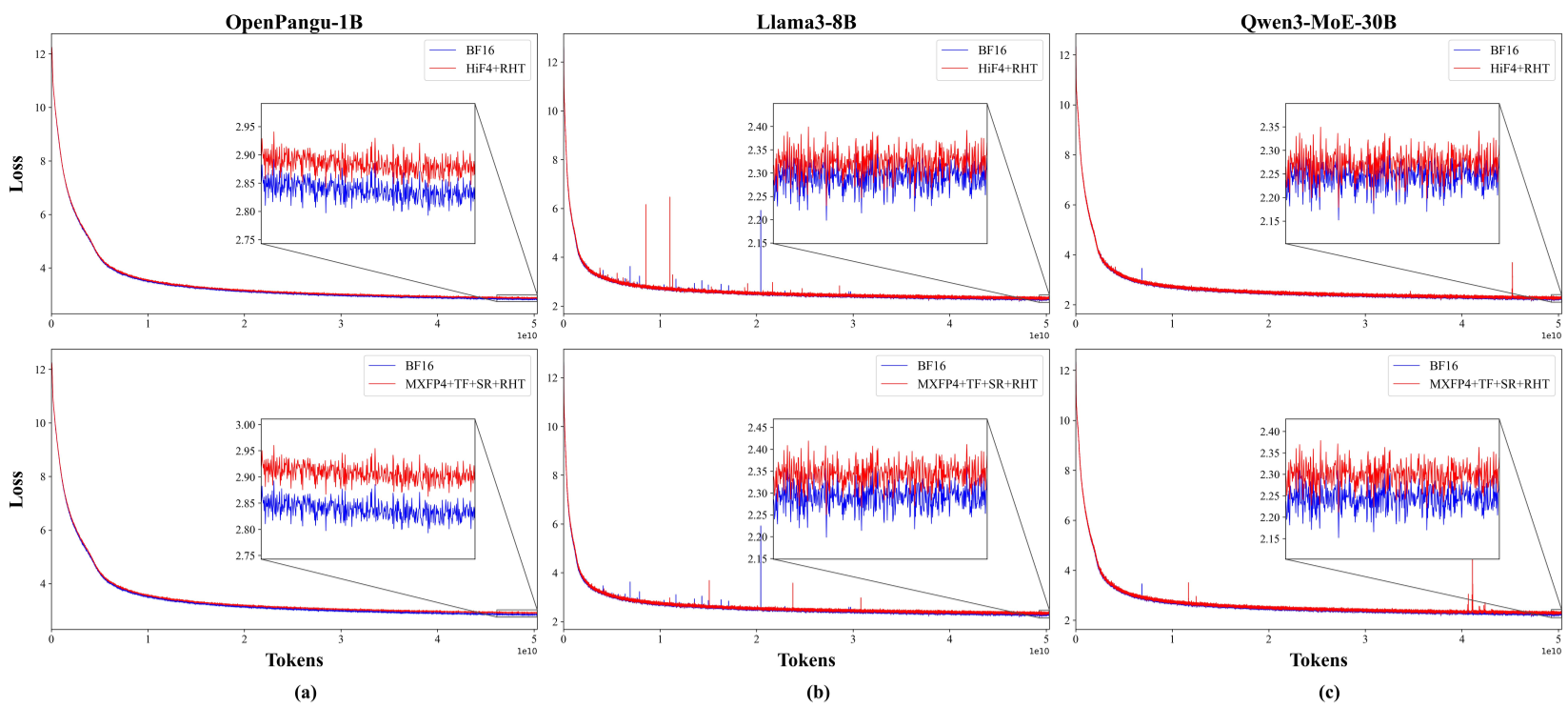
- 性能表现:在 30B 规模的 MoE 模型中,HiF4 的 Loss 曲线几乎与 BF16 基线重合,相对误差仅为 0.88%。
- 存储优势:在 MoE 架构中,由于激活的专家仅占一小部分,高达 95.9% 的线性层参数成功转为 FP4 存储,极大地缓解了集群通讯与显存带宽压力。
- 消融研究:如下表所示,HiF4 在“纯净”模式(Pure FP4)下的表现远好于 MXFP4,证明了其数值格式设计的优越性。
| 策略 (Relative Error) | HiF4 | MXFP4 | | :--- | :--- | :--- | | Pure FP4 | 1.11% | 3.85% | | + RHT | 0.97% | 2.06% | | + SR + RHT + TF | - | 1.42% |
资深主编点评
这篇论文的价值在于它不仅是一个算法的进步,更是 Hardware-Algorithm Co-design(硬软协同设计) 的典范。它告诉我们:
- 格式胜于算法:一个设计良好的数值格式(如 HiF4 的分层缩放)可以省掉大量的软件稳定化操作,从而在昇腾 NPU 这种强调 Cube Unit 吞吐、对标特定指令集的硬件上获得真正的 Speedup。
- MoE 是 FP4 的主战场:MoE 模型天然的稀疏性使得 FP4 带来的存储红利被放大,而由于计算路径的动态性,对格式的稳定性要求也更高,HiF4 恰好填补了这一空白。
局限性与展望:目前实验主要集中在 50B Pre-training,但在超长上下文(Long-context)以及对偏置(Bias)极其敏感的 RLHF 阶段,FP4 的表现仍需验证。昇腾 NPU 未来若能完全释放 HiF4 的硬件级指令潜力,将极大地改变大模型训练的成本版图。