本文由多位国际顶尖统计学家合作,系统综述了高维统计学(High-Dimensional Statistics)过去二十年的进展及未来挑战。报告重点探讨了计算与统计折衷、数据整合、高维渐近分析,以及高维统计在现代 AI(如大模型微调、上下文学习、机器去学习)中的核心地位,标志着该领域从单纯的稀疏性建模转向更复杂的结构化推断。
TL;DR
高维统计学已不再仅仅是关于 的数学游戏,它正演变为理解复杂系统的底层框架。这篇跨时代的论文《High-Dimensional Statistics: Reflections on Progress and Open Problems》由 Arian Maleki 等顶尖统计学家共同撰写,深度剖析了计算界限、数据整合以及 AI 模型背后的统计机理,指出“比例渐近”和“计算折衷”是通往现代数据科学真理的必经之路。
核心速览
过去二十年,高维统计经历了从“稀疏性”概念到“复杂结构化推断”的飞跃。文章的核心观点在于:维度不应被视为敌人,多样化的结构属性(如 Low-rank, Sparsity, Smoothness)才是实现有效推断的关键。
1. 计算-统计鸿沟(The Computational-Statistical Gap)
作者提出了一个引人深思的概念:有些问题在数学上是“可解”的,但在计算上是“死路一条”。
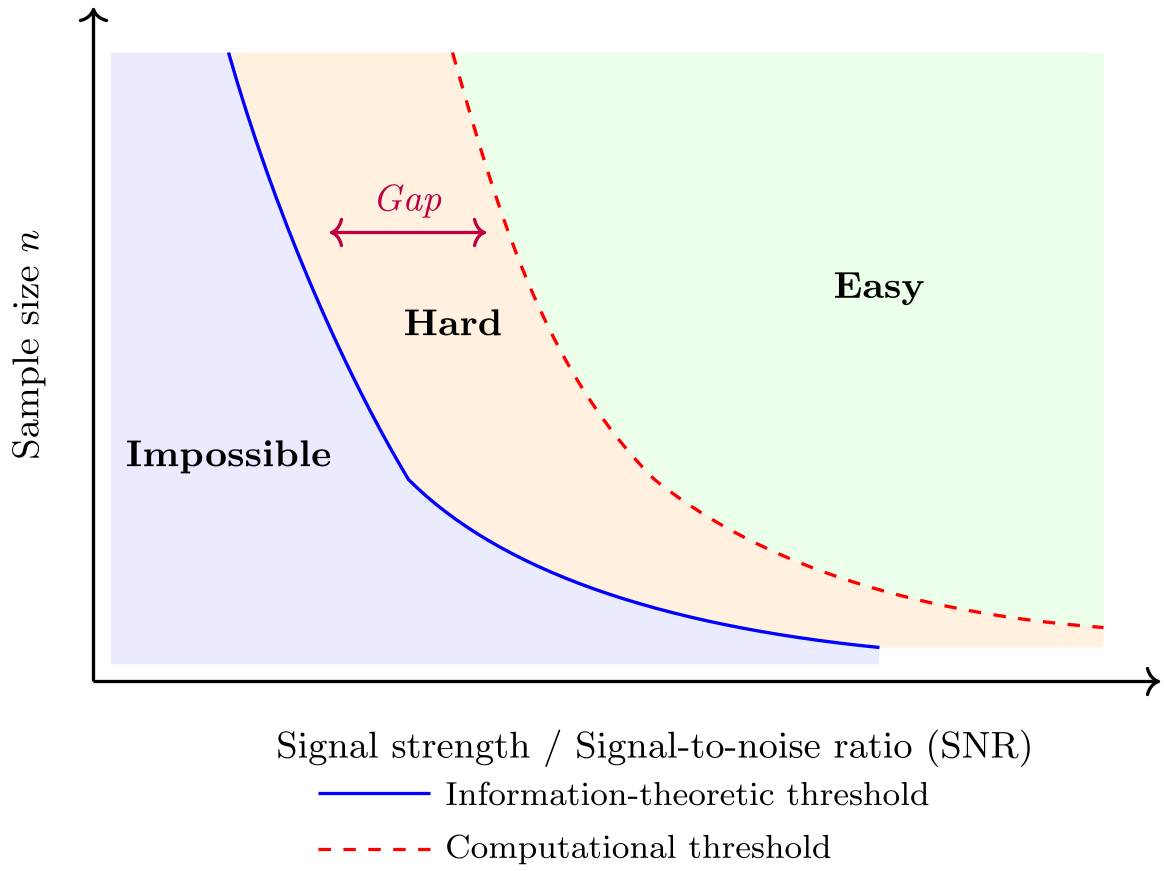
- Hard Regime(硬区域):在信息论阈值与计算阈值之间。例如在 Sparse PCA 中,当信号强度不足以驱动多项式时间算法时,模型便陷入该区域。
- 主要框架:作者梳理了统计查询(SQ)、SoS(平方和层次)和低度多项式框架,解释了为什么某些算法(如谱方法)会在特定 SNR 阈值下失效。
2. 比例渐近:比经典理论更“接地气”
传统的统计一致性要求 而 固定,这在现代 AI 前景下几乎没有指导意义。作者推崇 比例渐近(Proportional Asymptotics),即设置 。
例如,在 LASSO 回归中,通过这种框架可以导出著名的 自适应消息传递(AMP) 状态演化方程:
这个公式背后的逻辑是:高维估计的残差表现得就像叠加了独立高斯噪声,这为构造去偏估计量(Debiased Estimator)和置信区间提供了坚实的物理直觉。
3. 高维统计与 AI 的“深度绑定”
这是该综述最具有前瞻性的部分,探讨了统计学如何解决 AI 的黑盒问题:
- LoRA 的统计本质:低秩适配(LoRA)被看作是在权重的更新空间进行隐式 PCA。作者认为 LoRA 的成功不仅是计算 trick,更是因为微调任务通常存在低内禀维度的流形(Intrinsic Manifold)。
- In-context Learning (ICL):上下文学习被建模为模型在 Prompt 序列中执行隐式的“贝叶斯推断”或梯度下降步骤。
- 神经标度律(Scaling Laws):训练损失与参数量、数据量之间的幂律关系 ,实际上可以从随机特征模型(Random Feature Models)的高维渐近解中找到对应的数学支撑。
4. 数据整合与分布式学习
面对数据“孤岛”和隐私需求,文章讨论了两种集成模式:
- 横向集成(Horizontal):相同变量,不同样本。通过一轮平均(One-shot Averaging)或多轮迭代优化(Iterative Optimization)实现。
- 众生相(Heteroskedasticity):数据来源异质。作者指出经验贝叶斯(Empirical Bayes)在高维异质性补偿中的潜力。

深度洞察与总结
论文最后指出了几个令人兴奋的未来方向:
- 计算障碍的“祝福”:有时正是因为计算困难,导致我们被迫使用更简单的模型,反而提升了推断的可解释性和正态性。
- 机器去学习(Machine Unlearning):在高维非凸空间,如何真正“擦除”数据印记而不必重训?这需要极高维度的微扰分析。
- 可验证反馈的强化学习(RLVR):在数学、编程等有确定答案的领域,如何利用二进制奖励(对/错)进行稳健的高维策略优化。
结语:高维统计已经从单纯的“降维”进入了“结构化智能”的新阶段。正如文中暗示的那样,维度的诅咒正在被结构的福音所平衡。