The paper introduces HopChain, a scalable data synthesis framework designed to improve fine-grained vision-language reasoning in VLMs. It generates multi-hop, logically dependent reasoning chains grounded in visual evidence, resulting in significant SOTA improvements on models like Qwen3.5-397B across 24 benchmarks.
TL;DR
Researchers from Alibaba Qwen and Tsinghua University have unveiled HopChain, a framework that generates complex, multi-step visual reasoning puzzles. By training Vision-Language Models (VLMs) on these "logically locked" chains, they solved the critical issue of compounding errors in long-reasoning tasks. The result? Massive gains (up to 50% in long-CoT) across STEM, Document AI, and even Video benchmarks.
The Problem: When "Thinking" Distances Itself from "Seeing"
As VLMs move toward Long Chain-of-Thought (CoT) reasoning (similar to OpenAI’s o1 or DeepSeek-R1), a new failure mode emerges: Evidential Drift.
In a long reasoning chain, a model might correctly identify an object in Step 1, but by Step 5, it is hallucinating properties based on its own previous text rather than the actual image. Current training data is often "flat"—if you miss the middle step, you might still guess the right answer. This lacks the "logical friction" needed to train robust grounding.
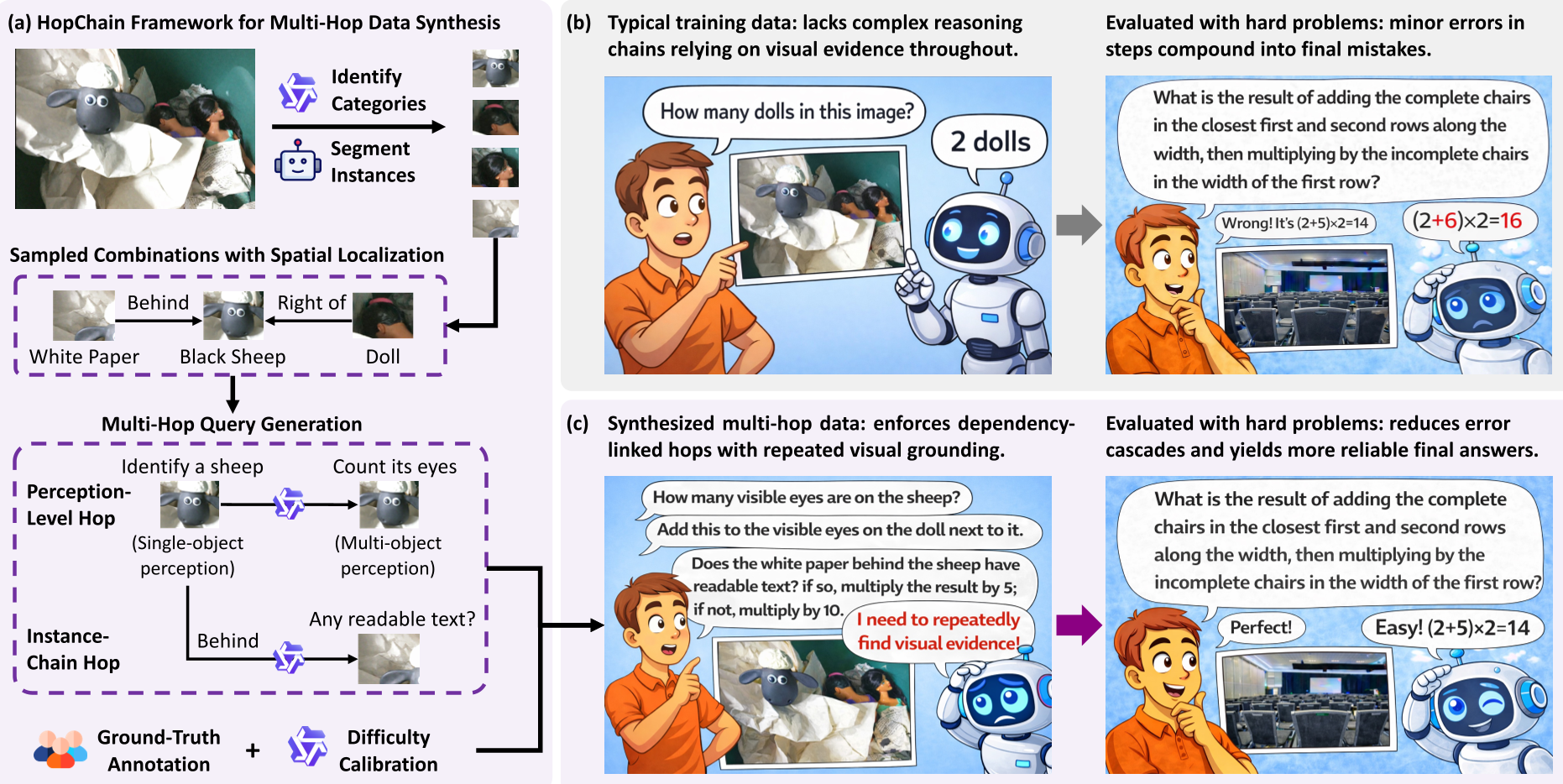
Methodology: The Anatomy of a "Hop"
HopChain forces the model to stay honest by creating queries where Step is impossible without the precise result of Step . They define two types of transitions:
- Perception-level hops: Moving from "What color is this?" (Level 1) to "How many objects are larger than this?" (Level 2).
- Instance-chain hops: Moving from Object A to Object B (e.g., "Find the person holding the bag Identify the logo on that bag").
The Synthesis Pipeline
- Category ID: Using a "Thinking" VLM to find all semantic categories.
- Segmentation: Using SAM3 to get precise bounding boxes/masks.
- Query Generation: A high-level VLM constructs a 3-6 hop question ending in a number.
- Verifiable Reward: Because the answer is a number, the model can be trained via RLVR (Reinforcement Learning with Verifiable Rewards) using the SAPO algorithm.

Experimental Results: Scaling the "Thinking" Peak
The authors tested HopChain on the Qwen3.5 family. The results prove that multi-hop data acts as a "reasoning catalyst":
- Generalization: Even though the data was synthesized from static images, it improved Video Understanding (Video-MME) and Document AI (DocVQA) across the board.
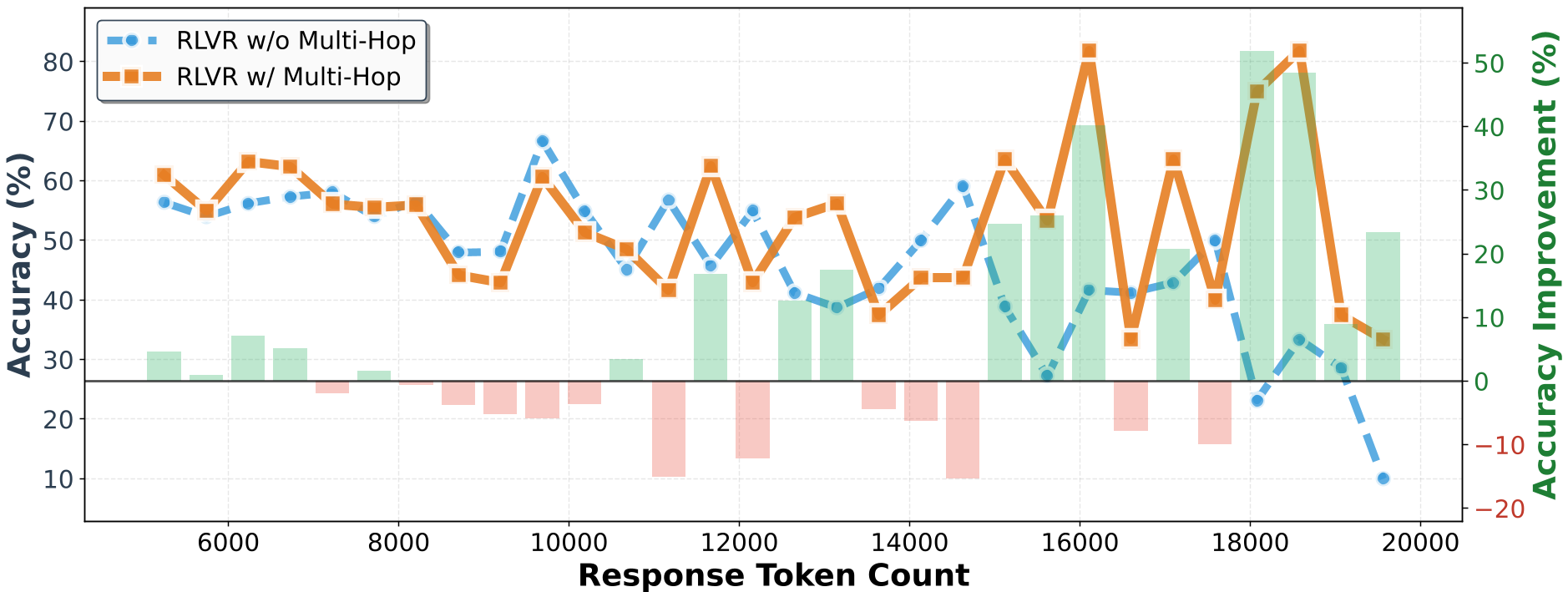
- The Long-CoT Edge: On the most difficult reasoning tasks, the HopChain-trained models outperformed standard RLVR models by over 50 percentage points when the response length exceeded 1000 tokens.
- Ablation: They found that if you shorten the chains (Single-Hop) or provide half-chains, the performance collapses, proving that the interdependency of the hops is the "secret sauce."
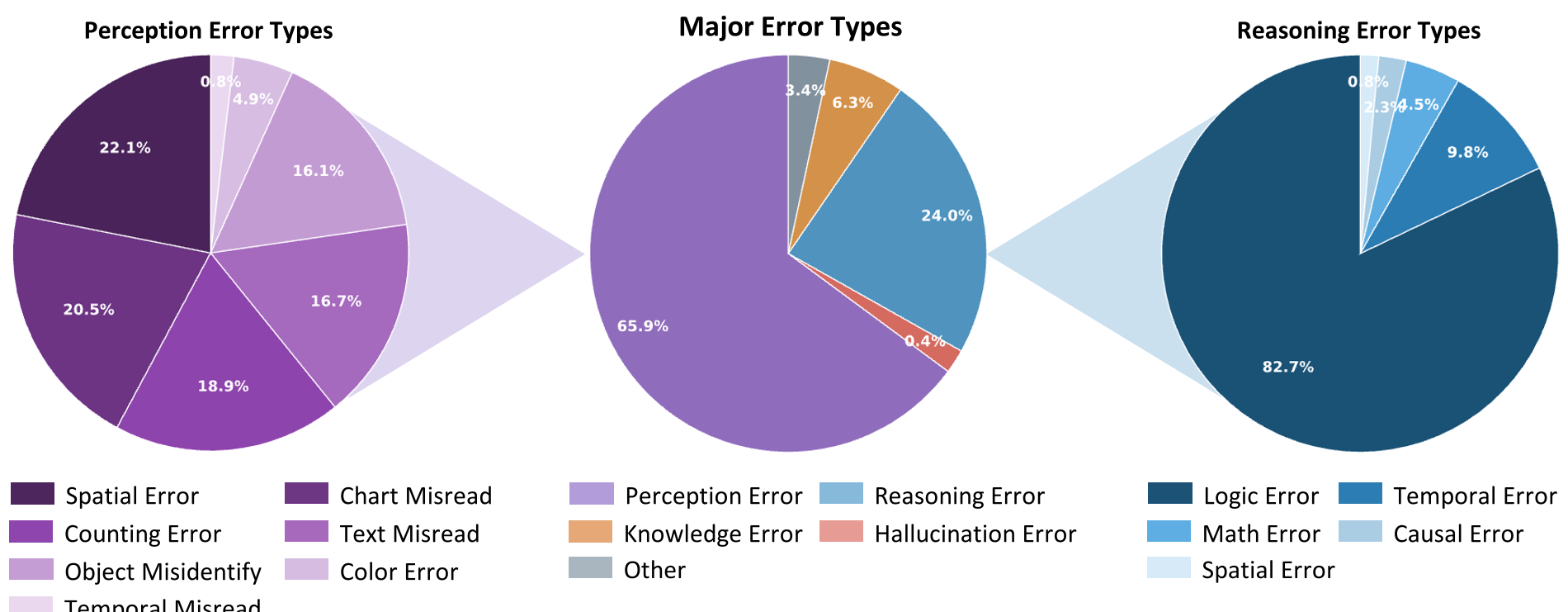
Harder is Better: The Broad Difficulty Range
Interestingly, the study shows that more than half of the synthesized queries reside in the "Partially Correct" bucket for current top-tier models. This represents the "Goldilocks Zone" for Reinforcement Learning—tasks that are neither too easy to be trivial nor too hard to be unlearnable.
Conclusion & Insights
HopChain demonstrates that the next frontier for Multimodal AI isn't just "more data," but structurally superior data. By engineering queries that act as logical circuits—where the signal must pass through multiple visual check-points—we can train VLMs to be as meticulous as they are creative.
For practitioners, the takeaway is clear: if your VLM is hallucinating in long dialogues, the solution isn't just more SFT; it's verifiably coupled multi-hop RL.