本文提出了 HP-Edit,一个针对图像编辑任务的人类偏好对齐后训练框架。通过引入任务感知的 HP-Scorer、高质量数据集 RealPref-50K 以及在线强化学习算法 Flow-GRPO,该方法在保持编辑准确性的同时,显著提升了生成图像的视觉审美与真实感。
TL;DR
华为诺亚方舟实验室及其合作团队推出了 HP-Edit,这是首个专门为图像编辑任务设计的“人类偏好对齐”后训练框架。通过自动化评分器(HP-Scorer)和精准的数据集过滤,它成功利用强化学习(Flow-GRPO)让图像编辑模型(如 Qwen-Image-Edit)在保持编辑准确度的同时,显著提升了图像的艺术性和自然度。
背景:为什么 SFT 过后的编辑模型还是“不够好”?
在图像编辑领域,虽然目前的扩散模型(Diffusion Models)已经能通过有监督微调(SFT)完成增、删、改等基础任务,但开发者常常发现:
- 审美断层:SFT 使用的数据集包含大量卡通或质量良莠不齐的合成图,模型虽然学会了“改图”,但改出来的图像往往光影不自然或充满 AI 塑料感。
- 对齐难题:要让模型完全符合人类对“美”和“自然”的定义,需要大量人类标注的偏好数据(Pairwise Data),成本高昂且难以规模化。
HP-Edit 的核心直觉在于:与其教模型“怎么改”,不如提供一个懂审美的“裁判”,让模型在反复的自我尝试中学会“怎么改才好看”。
核心架构:三位一体的 HP-Edit 框架
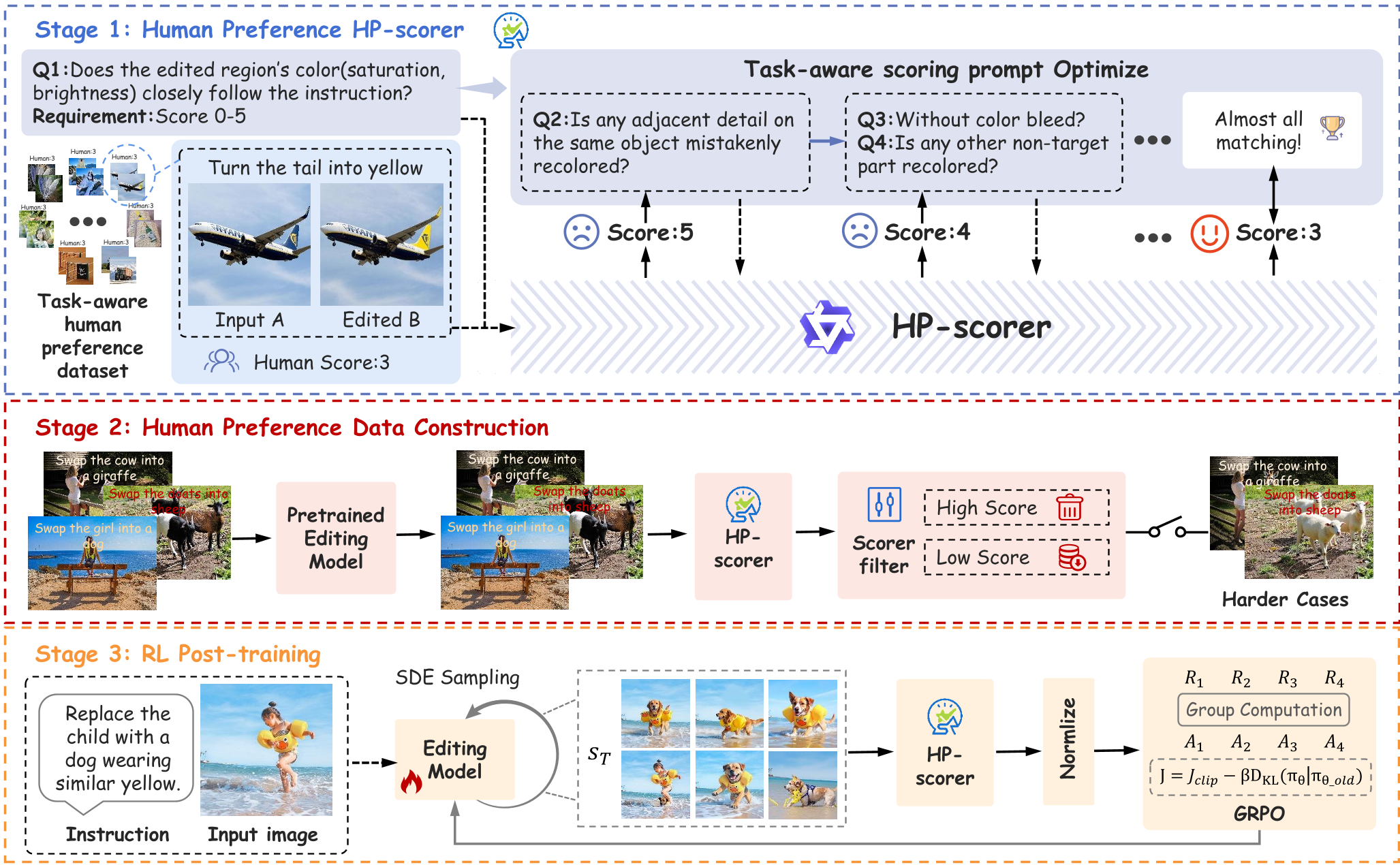
1. 任务感知的 HP-Scorer (智能裁判)
作者利用预训练的视觉大模型(VLM)构建了 HP-Scorer。其独特之处在于针对不同的编辑子任务(如:物体替换、背景虚化、调光)设计了专门的推理 Prompt。例如在“物体交换”任务中,它不仅看物体变没变,还会问:“原物体是否被完全遮盖?”“新物体与环境的光影是否统一?”
2. RealPref-50K:聚焦“困难案例”
作者提出了一个关键的发现:如果数据集里全是模型已经能处理很好的简单任务(5 分样本),强化学习就学不到东西。因此,他们利用 HP-Scorer 对 5 万条真实世界数据进行筛选,剔除高分样本,专门留着模型做不好的“硬骨头”进行 RL 训练,极大提升了训练效率。
3. Flow-GRPO:在线强化学习
为了将传统的 Flow Matching 模型(确定性过程)应用到强化学习中,作者采用了 Flow-GRPO。
- 数学直觉:通过将分步推理看作一个马尔可夫决策过程(MDP),引入随机扰动(SDE 形式),让模型在同一指令下生成多个候选结果。
- 组对齐:通过计算组内图像的相对奖励(Advantage),奖励那些表现优于平均水平的动作,让模型向高分方向进化。
实验战绩:全线 SOTA
在涵盖 8 大常见编辑任务(添加、删除、更换背景、物体交换、颜色修改、背景虚化、重照明、风格迁移)的 RealPref-Bench 上,HP-Edit 展示了压制性的实力:

- 量化提升:各分项评分均有提升值,总体 HP-Score 从 4.472 提升至 4.667。
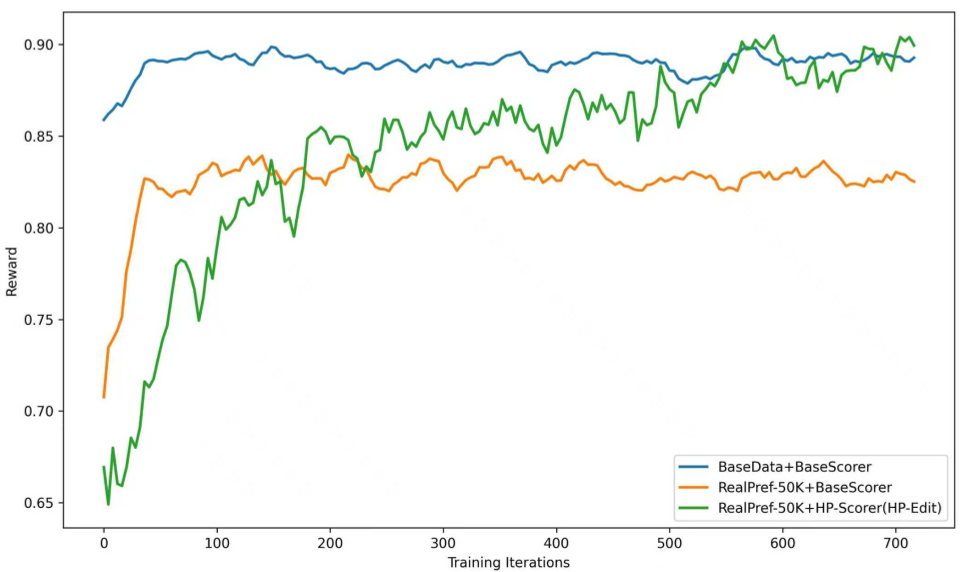
- 画质跃迁:从消融实验看(如下图 reward 曲线),带有 HP-Scorer 指导的训练(绿色曲线)具有最稳定的收益增长,证明了精准奖励函数的必要性。
总结与局限
HP-Edit 证明了 VLM 驱动的自动化评估 + 针对性奖励模型 + 强化学习 路径在视觉任务中的强大生命力。它不仅解决了数据标注难的问题,更为图像编辑引入了宝贵的“审美直觉”。
局限性: 模型目前在处理中英混合文本编辑(如将图中文字从英文改为中文)时仍力有不逮,这反映了基础模型(Base Model)本身在跨语言多模态处理上的短板,也是后续研究的重点方向。
本文由资深学术技术主编重构。HP-Edit 展现了从“有监督微调”向“人类偏好对齐”转型的行业大趋势。