本文推出了 HY-Embodied-0.5,一系列专为真实室内具身智能体设计的视觉语言基础模型(VLM)。该系列包含 2B 参数的边缘端高效模型 MoT-2B 和 32B 参数的复杂推理模型 MoE-A32B,在 22 个空间与具身测评基准中展现了 SOTA 性能,并成功应用于真实机械臂控制任务。
TL;DR
腾讯 Robotics X 与 HY Vision 团队联合发布了 HY-Embodied-0.5 系列模型。通过创新的 Mixture-of-Transformers (MoT) 架构和深度强化学习(RL)演化,该模型在空间感知、轨迹预测及多步规划上实现了突破性提升。2B 版本的微型模型在具身测评中甚至超越了 4B 以上的大型通用模型,并已在真实机械臂操作中得到了验证。
背景定位:通用 VLM 难以走入物理世界?
尽管当前的 GPT-4o 或 Qwen 系列在看图说话、写代码方面极强,但它们在现实物理环境中往往表现得像个“深度近视”和“行动障碍者”:
- 细粒度感知缺失:无法精准判断物体间的厘米级距离。
- 逻辑断层:知道“要把苹果放进篮子”,但不知道机械臂应该走哪条空间轨迹(Trajectory)。
HY-Embodied-0.5 的出现,正是为了填补从数字理解到物理动作之间的鸿沟。
核心架构:Mixture-of-Transformers (MoT) 与 Latent Tokens
为了让 2B 规模的小模型也能承载复杂的空间推理,作者在架构上动了“大手术”:
1. 模态自适应计算 (MoT)
作者没有采用传统的全参数共享,而是引入了 Mixture-of-Transformers。简单来说,为视觉和文本分配了非共享的参数分支(QKV 和 FFN)。
- 直觉:重度的视觉训练往往会导致语言能力的退化(Catastrophic Forgetting)。MoT 允许模型针对视觉模态进行专门优化,而不破坏语言基座。
2. 视觉潜代币 (Visual Latent Tokens)
受“思维链”启发,作者在视觉输入序列末尾添加了可学习的 Latent Tokens。
- 作用:这些 Token 充当了视觉全注意力和语言因果注意力之间的“桥梁”,能够捕捉 Salient Objects 的精细特征。
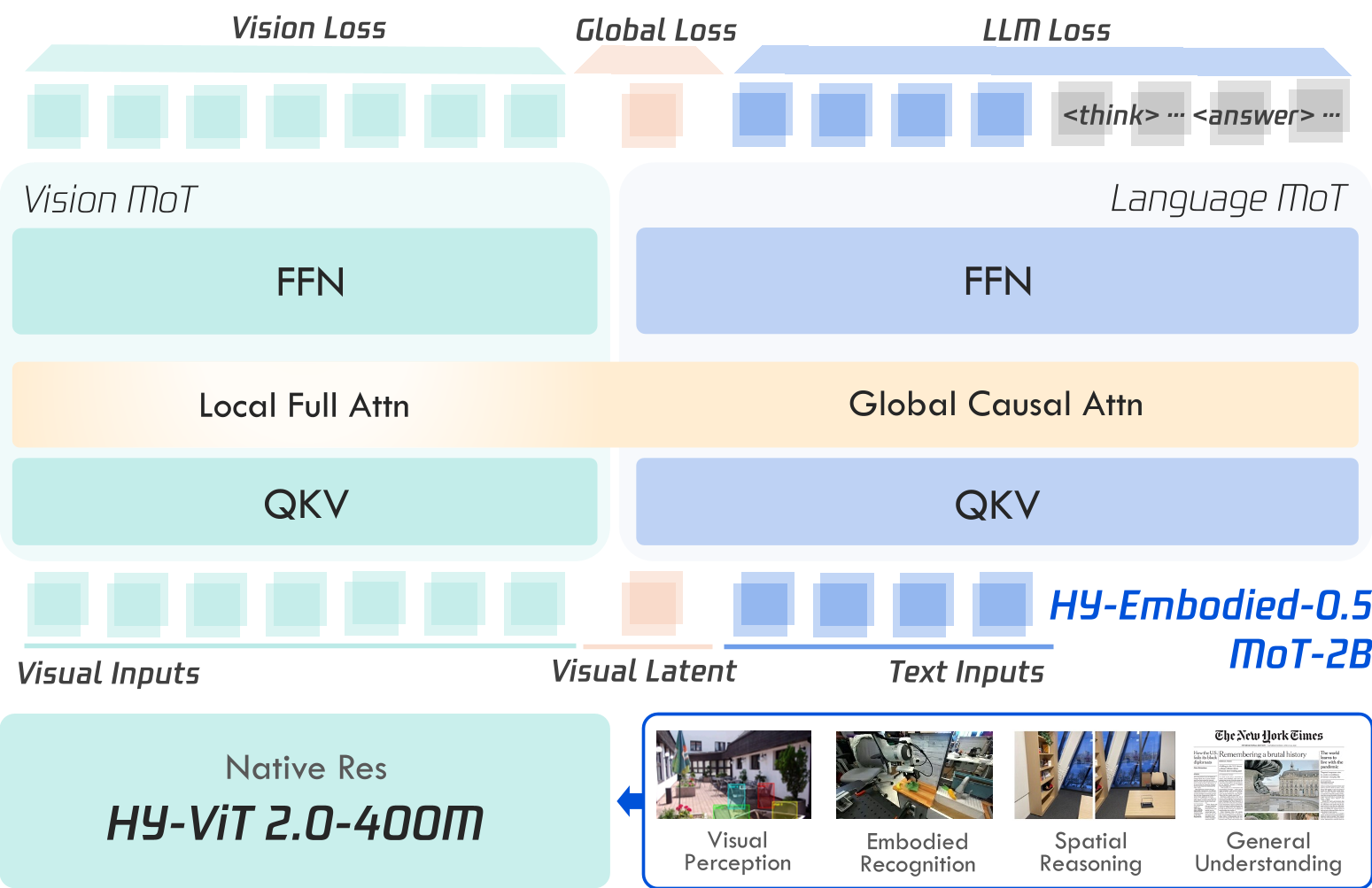 图 2: HY-Embodied-0.5 的 MoT 架构,展示了模态特定的处理流程。
图 2: HY-Embodied-0.5 的 MoT 架构,展示了模态特定的处理流程。
训练范式:从大规模预训练到“深度思考”
论文的亮点之一在于其 Post-training 流水线:
- 冷启动 SFT:构建 100k 高质量的 Chain-of-Thought (CoT) 数据。
- 强化学习 (RL):使用 GRPO 算法。最关键的是任务感知奖励设计 (Task-aware Reward)。对于坐标输出,使用 IoU 奖励;对于动作序列,使用带有惩罚项的轨迹奖励。
- 迭代自进化 (RFT):通过大模型作为 Teacher 来筛选高质量的推理路径,让模型不仅“答对”,还要“想对”。
- 大到小的 On-policy 蒸馏:让 2B 学生模型在自己生成的错误路径上,接受 32B 老师模型的即时纠偏,大幅提升了小模型的推理鲁棒性。
实验结果:边缘侧的性能怪兽
在包含 22 个基准的任务套件中,HY-Embodied-0.5 拿下了惊人的战绩:
- MoT-2B:在 16/22 个榜单中排名第一。在空间理解(Spatial Understanding)领域,其表现远超 Qwen3-VL-2B 和 RoboBrain 2.5。
- MoE-A32B:平均成绩达到 67.0%,在同级别对抗中击败了 Gemini 3.0 Pro。
 表 1: MoT-2B 与各大主流具身/通用 VLM 的性能对比。
表 1: MoT-2B 与各大主流具身/通用 VLM 的性能对比。
真实世界验证:机械臂的“精密操作”
在“挂杯子”(Mug Hanging)这一极具挑战性的任务中,HY-Embodied-0.5 的成功率达到了 75%。这是一个非常硬核的指标,因为该任务不仅需要识别钩子,还需要精确控制末端执行器的空间路径。
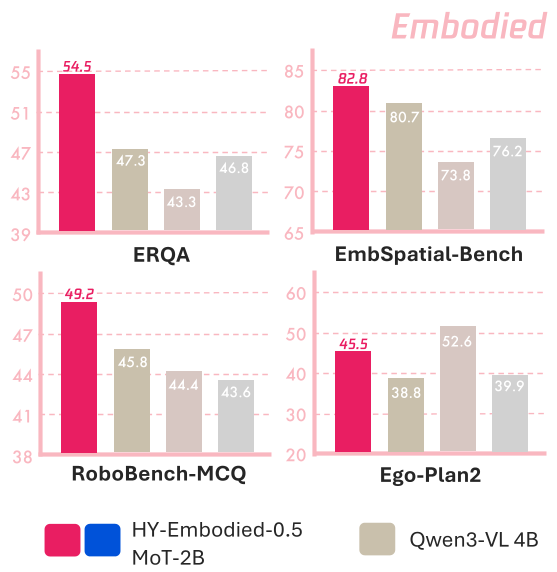 图 1: 视觉感知与真实机器人控制任务的效果展示。
图 1: 视觉感知与真实机器人控制任务的效果展示。
深度洞察:为什么这篇论文重要?
HY-Embodied-0.5 的成功不仅仅是因为数据量大,更在于它将“推理”与“空间几何”完成了深度解耦与对齐。通过 <think> 标签,我们能清晰地看到模型如何分析背景、估算距离。
局限性分析:尽管模型在模拟和受控真实环境中表现出色,但在处理动态、高速移动的物体或极端光照条件下的感知表现仍有待进一步观察。此外,当前的 VLA 模型主要针对具体的运动控制,尚未实现跨异构物理实体的通用化。
总结
HY-Embodied-0.5 证明了通过 Mixture-of-Transformers 架构与迭代式 Post-training 策略,即便是轻量级的模型也能拥有顶级的物理常识推理能力。这为未来在机器人、无人机等算力受限平台上部署真正的“具身大脑”扫清了障碍。