Tencent Hunyuan presents HY-World 2.0, a unified multi-modal world model framework that bridges 3D generation and reconstruction. Using a four-stage pipeline—panorama generation, trajectory planning, world expansion, and composition—it synthesizes high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes from text, images, or videos, matching closed-source models like Marble while remaining open-source.
TL;DR
Tencent's Hunyuan team has unveiled HY-World 2.0, a powerhouse framework that bridges the gap between purely "imaginative" AI generation and "literal" 3D reconstruction. By combining panorama initialization, semantics-aware path planning, and memory-driven video expansion, it produces interactive 3D Gaussian Splatting (3DGS) environments that are both visually stunning and geometrically consistent. It matches the performance of elite closed-source models while being fully open-source.
The Core Tension: Accuracy vs. Hallucination
In the current AI landscape, we usually have to pick a side:
- Generative Models (like Sora or Stable Diffusion) can create a beautiful living room from a text prompt, but if you "walk" around a corner and come back, the furniture might have shifted. They lack 3D consistency.
- Reconstruction Models (like traditional NeRF or MVS) are great at turning photos into 3D models, but they are helpless if parts of the scene are missing. They lack generative priors.
HY-World 2.0 solves this "bifurcation" by treating world creation as a staged pipeline where imagination handles the "what" and geometric memory handles the "where."
The Four Pillars of World Generation
1. HY-Pano 2.0: The 360° Sandbox
Everything starts with a panorama. Unlike HY-World 1.0, which relied on brittle camera metadata, 2.0 uses a Multi-Modal Diffusion Transformer (MMDiT) to implicitly learn how to map a single perspective image into a full Equirectangular Projection (ERP). This allows the model to "hallucinate" what’s behind the camera with remarkable structural coherence.
2. WorldNav: Planning the Exploration
Once the panorama exists, the model needs to "look around" to flesh out the 3D space. WorldNav utilizes scene parsing to build a Navigation Mesh (NavMesh). It then plans five types of trajectories (Regular, Surrounding, Recon-Aware, Wandering, and Aerial) to ensure every nook and cranny of the scene is observed, avoiding obstacles just like a real-world robot or drone would.
3. WorldStereo 2.0: Geometric Memory
This is the "engine room" of the project. Traditional video models blur under fast camera motion. HY-World 2.0 bypasses this by working in a Keyframe Latent Space.
- Global-Geometric Memory (GGM): Uses point clouds to keep the big picture (the "skeleton") stable.
- Improved Spatial-Stereo Memory (SSM++): Stitches retrieved historical views with current targets to ensure fine-grained details (like the texture of a rug) don't change as you move.
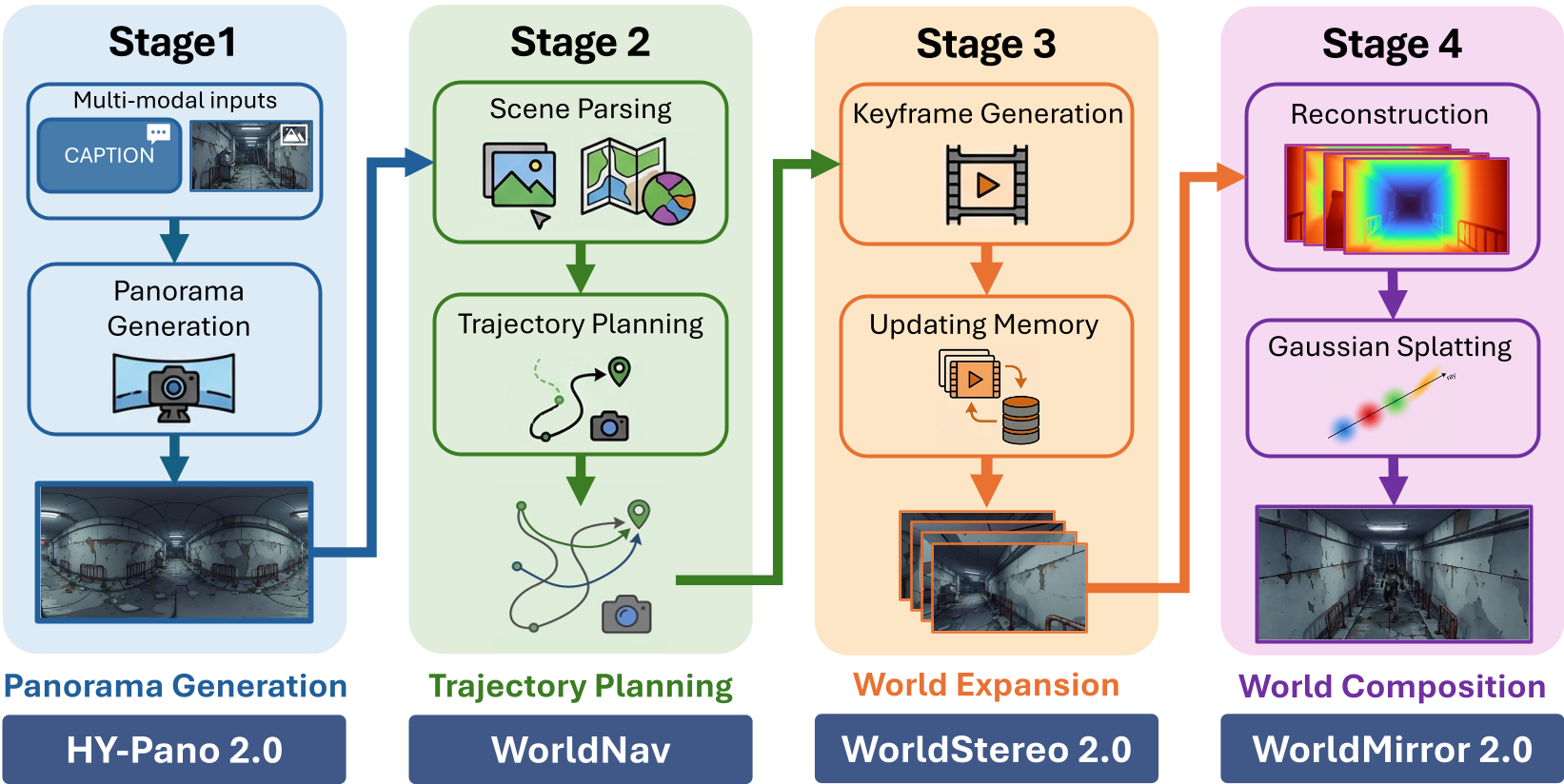
4. WorldMirror 2.0 & Composition: The 3D Finishing
The final step turns these generated images into 3DGS assets. The authors upgraded the reconstruction model (WorldMirror 2.0) with:
- Normalized Position Encoding: Allowing it to handle resolutions much higher than its training data without "breaking."
- Depth-to-Normal Coupling: Ensuring that a wall looks flat not just in terms of color, but in terms of its geometric surface orientation.
Experimental Results: Beating the Benchmarks
The improvements in WorldMirror 2.0 are night-and-day. When testing at high resolutions, the prior version (1.0) saw its camera pose accuracy collapse. Version 2.0, thanks to the normalized encoding, Actually improved its performance as resolution increased.

In direct head-to-head comparisons with Marble (the current gold standard for commercial world models), HY-World 2.0 showed far fewer "floaters" and much sharper textures, especially in challenging outdoor scenarios with complex geometry like cars and fences.
Deep Insights & Future Impact
The true genius of HY-World 2.0 lies in its modular robustness. By separating the "hallucination" (Diffusion) from the "geometry" (3DGS optimization), the authors have created a system where each part can be upgraded independently.
Limitations: While the 10-minute generation time is impressive, it is still "offline." The next frontier will be "online" interactive generation where the world reacts to the user's physics-based interaction in real-time (sub-100ms).
Conclusion: HY-World 2.0 isn't just a research paper; it's a blueprint for the "Spatial Intelligence" required by the next generation of VR and autonomous robots. It proves that with the right memory mechanisms, AI can finally start to "understand" the 3D world as we do.
