The paper introduces Hybrid Memory, a novel paradigm for video world models that maintains consistency for both static backgrounds and dynamic subjects during out-of-view intervals. The authors propose the HyDRA (Hybrid Dynamic Retrieval Attention) architecture and construct HM-World, a large-scale dataset of 59K clips featuring decoupled camera and subject trajectories to evaluate subject re-entry events.
TL;DR
Existing video world models often transition from "simulating reality" to "hallucinating ghosts" the moment a person walks off-camera. This paper introduces Hybrid Memory, a design philosophy where models act as both archivists for the background and trackers for the subjects. By introducing the HyDRA architecture and the HM-World dataset, the authors enable models to "mentally predict" subject trajectories while they are out of sight, ensuring they re-enter the frame with consistent appearance and motion.
The "Static Canvas" Problem
Most current SOTA video models treat the world like a painting. If the camera pans away from a house and back, the house stays put (Static Consistency). However, if a dog runs behind a tree, current models struggle:
- The Frozen Statue: The dog reappears but is stuck in its last seen pose.
- The Phantom: The dog reappears but looks like a completely different breed.
- The Vanishing Act: The model "forgets" the dog existed and renders an empty street.
The core issue is Feature Entanglement. In standard Diffusion Transformers (DiT), background and foreground features are mixed. When retrieving memory, the model often fails to isolate the motion logic of the subject from the static geometry of the scene.
Methodology: Entering the HyDRA
To solve this, the authors propose HyDRA (Hybrid Dynamic Retrieval Attention). The architecture moves away from simple frame-concatenation toward a sophisticated retrieval-based memory.
1. Memory Tokenization
Instead of feeding raw latents back into the model (which introduces noise), HyDRA uses a 3D-convolutional Memory Tokenizer. This expands the spatiotemporal receptive field, creating tokens that are "aware" of where a subject was headed before it left the frame.
2. Spatiotemporal-Driven Retrieval
The "Magic" happens in the Dynamic Retrieval Attention layer. Unlike previous methods that used FOV (Field of View) overlap to find relevant frames, HyDRA calculates a Spatiotemporal Affinity Metric.
As shown in the architecture below, it compares the current denoising target (the "Query") against the memory bank (the "Keys") to find the most relevant historical tokens—even if they occurred in a different part of the 3D space.
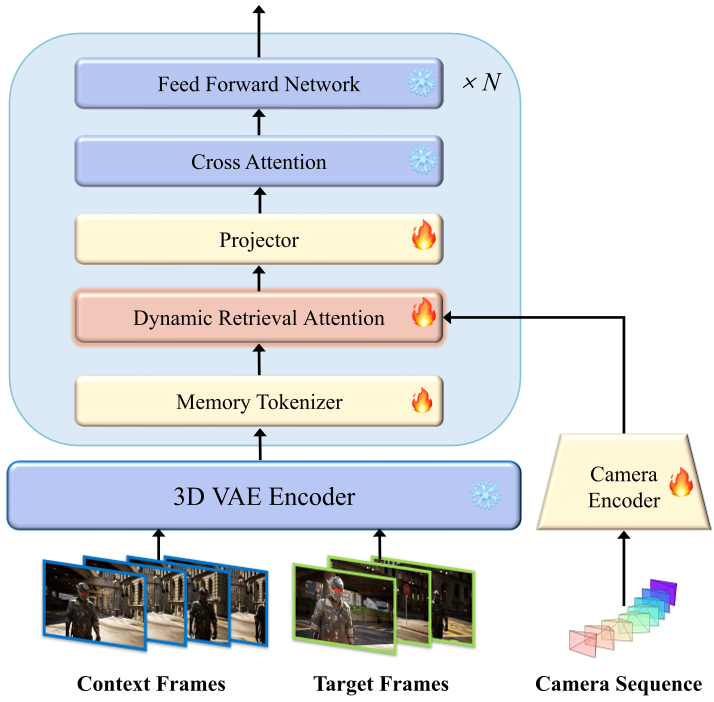 Fig 1: The HyDRA pipeline, showcasing Memory Tokenization and Dynamic Retrieval.
Fig 1: The HyDRA pipeline, showcasing Memory Tokenization and Dynamic Retrieval.
HM-World: A Rigorous Testing Ground
You can't train for Subject Re-entry using random Internet videos where the camera is usually focused on the subject. The authors created HM-World, featuring:
- 59K high-fidelity clips rendered in UE5.
- Decoupled Trajectories: The camera moves independently of the subjects.
- 28 Camera Trajectories: Including "back-and-forth" movements specifically designed to force subjects out of and back into the frame.
Experimental Results: Subject Consistency Redefined
The researchers compared HyDRA against strong baselines like Context-as-Memory and commercial models like WorldPlay.
| Metric | Baseline | Context-as-Memory | HyDRA (Ours) | | :--- | :--- | :--- | :--- | | PSNR | 18.69 | 18.92 | 20.35 | | DSC (GT) | 0.837 | 0.839 | 0.849 | | Subj. Cons. | 0.903 | 0.911 | 0.926 |
The Dynamic Subject Consistency (DSC) metric is particularly telling. It uses YOLOv11 and CLIP to measure how similar the re-entering subject is to its historical self. HyDRA's superior score proves it isn't just generating "a person," but "the same person" in a logical motion state.
 Fig 2: Qualitative comparison showing HyDRA (green) maintaining subject integrity while others (red) fail.
Fig 2: Qualitative comparison showing HyDRA (green) maintaining subject integrity while others (red) fail.
Deep Insight: Why Retrieval Beats FOV
In the ablation studies, the authors found that Dynamic Affinity significantly beats FOV Overlap.
- FOV Overlap is purely geometric. If the camera looks at a new spot, it retrieves nothing, leading to "blank" memory.
- Dynamic Affinity allows the model to say: "I am looking at the street now; let me find the memory of that giraffe that was walking this way 5 seconds ago," regardless of where the camera was then.
Conclusion & Limitations
HyDRA is a major step toward "World Simulators" that actually understand the continuity of objects. However, the authors admit that performance degrades when the scene becomes too crowded (3+ subjects) or when occlusions are highly complex.
The takeaway for the industry is clear: Context is not just a static window; it is a searchable archive. For future autonomous driving and embodied AI, the ability to keep a "mental map" of hidden agents is no longer optional—it's a requirement.