本文提出了 Identity-as-Presence,一个用于音视频联合生成的统一框架。它通过解耦的身份注入机制,实现了在生成视频中对多个特定人脸外观(Appearance)和人声色(Voice Timbre)的高保真、一致性个性化控制,在多角色交互场景下达到了 SOTA 水平。
TL;DR
腾讯微信视觉团队(WeChat Vision)近期发布了 Identity-as-Presence 框架。这是首个能够同时对多个个体的面部外观和声音音色进行精细化控制的音视频联合生成系统。它不仅解决了“像谁”的问题,更解决了“谁在说”的跨模态对齐难题,支持从单人对白到复杂多人交互的电影级视频合成。
痛点深挖:为什么“对号入座”这么难?
在 AIGC 领域,让 AI 生成一个特定人物的视频已不稀奇。但要实现真正的“个性化数字孪生”,面临三大挑战:
- 模态割裂:以往模型往往视频归视频(如 Animate Anyone),声音归声音(如 VALL-E),通过后期唇形对齐合成。这种物理级拼接缺乏灵魂,动作与语气的微表情同步极差。
- 身份纠缠(Entanglement):当画面中出现多个人物时,AI 经常会把 A 的声音配给 B,或者生成的脸变成了两人的“融合体”。
- 数据匮乏:高质量、同时带有 ID 标注且声画完全同步的音视频对极度稀缺,普通的抓取数据充满噪音。
核心方案:Identity-as-Presence 的技术直觉
1. 统一身份注入:将身份视为“存在”
作者并没有使用复杂的辅助网络。相反,他们将参考的面部图像和参考音频剪辑全部 Token 化(Patchify),直接拼接到 Diffusion Transformer (DiT) 的输入序列中。
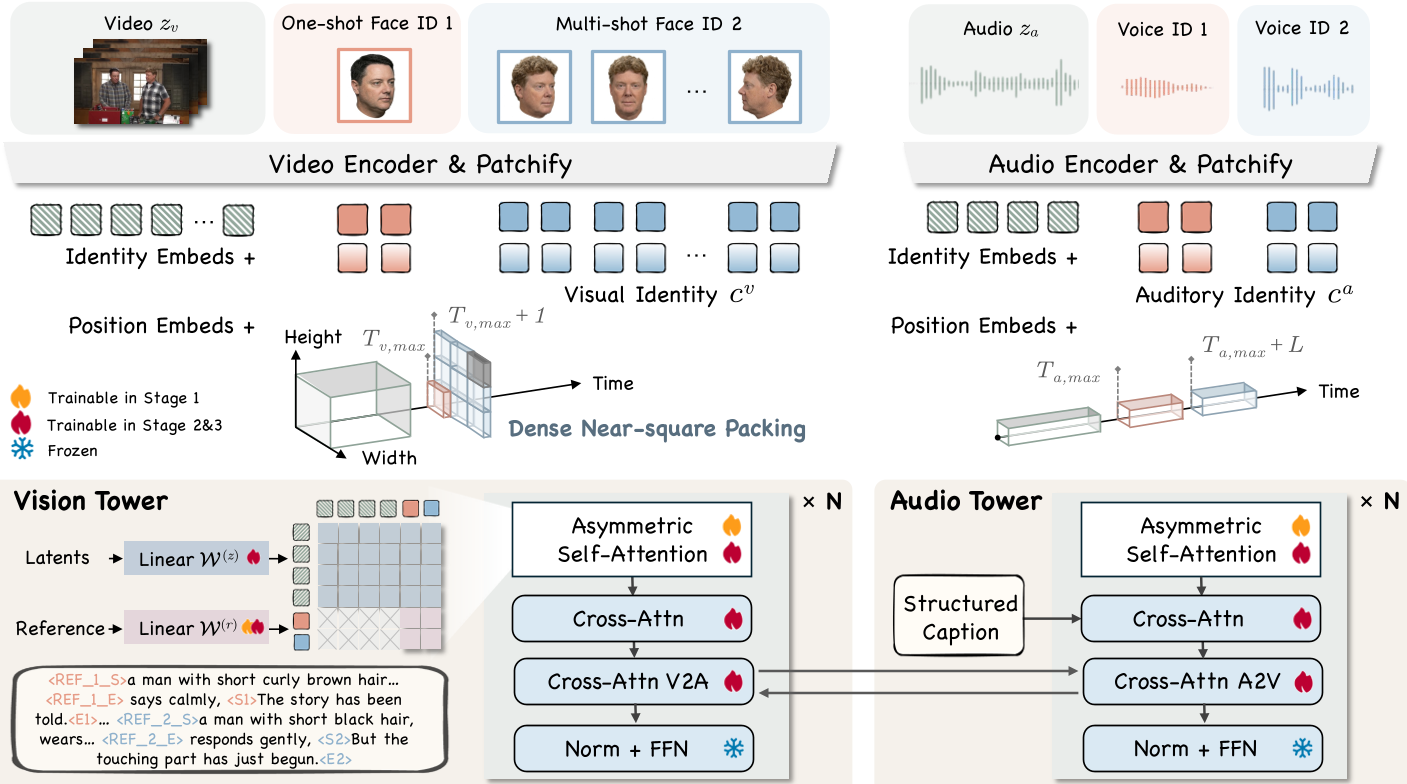
- 共享身份嵌入 (Shared Identity Embeddings):为了让模型知道哪张脸对应哪段声,作者为每个身份分配一个唯一的学习向量 。这个向量像“胶水”一样同时加在对应的视觉 Token 和音频 Token 上,在潜在空间建立起硬连接。
- 结构化时空位置编码:通过一种虚拟的时间轴扩展机制,将视觉身份(空间信息)和音频身份(时间信息)锚定在特定的几何位置,利用 Transformer 的相对位置偏差强化绑定。
2. 解耦参数化与异步注意力机制
为了防止生成过程中的高斯噪声“污染”了参考的身份特征,作者设计了异步自注意力 (Asymmetric Self-Attention)。
- 逻辑如下:生成目标(噪声 Token)可以观察参考信号(身份 Token),但参考信号之间互不干扰,也不受噪声影响。这确保了生成的视频既能灵活变化,又能死死锁住人物的基本特征。
实验与战绩:全方位的超越
在包含 100 个复杂场景的测试集上,Identity-as-Presence 在多项指标上刷写了纪录。

- 身份保真度:相比之前的标杆 Ovi 或 LTX-2,本项目在 VID-SIM(脸部相似度)和 AID-SIM(声音相似度)上显著占优。
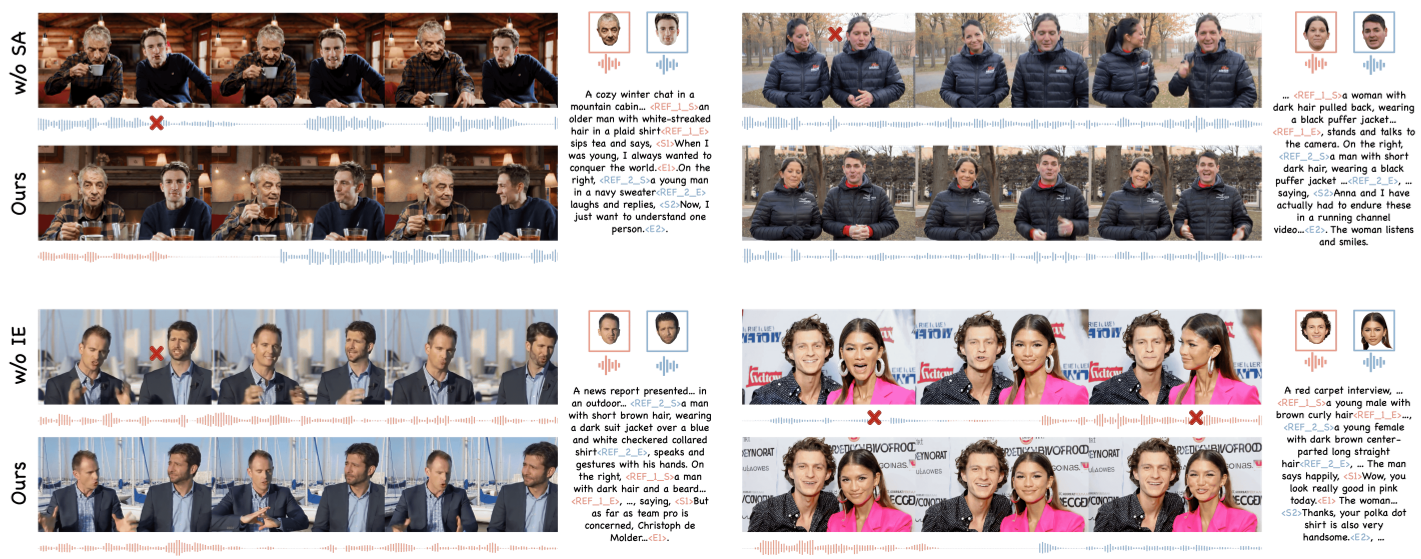
- 多主体控制:在消融实验中(见下图),如果没有“Subject Anchors”,视频中极易出现角色面部崩坏或多声部重叠;而开启后,两个角色的对话轮次和各自的特征清晰可见。
深度洞察:三阶段训练的智慧
为什么这个模型收敛得更快、效果更好? 作者采取了“由易入难”的策略:
- 单模态预训练:在海量 TTS 数据(音频)和人脸视频上分别训练,让模型先学会“怎么说话”和“怎么动”。
- 联合多模态训练:激活跨模态融合层,专门在精选的同步对上学习声画对齐。
- 多视角微调:引入少量高精度多视角数据,解决侧脸、大角度转头时的身份丢失问题。
总结与局限
Identity-as-Presence 为电影制作、虚拟主播和数字记忆提供了强大的技术支撑。它证明了在统一的 DiT 架构下,通过合理的引导机制,我们可以精准地在生成空间中“钉”住特定的身份。
局限性:尽管目前在多角色表现优异,但对于超过 3 人以上的超复杂交互场景(如嘈杂的 Party),声音分离和面部遮挡下的身份保持仍有巨大的研究空间。
本文由资深学术技术主编重构。更多细节请参阅原论文:Identity-as-Presence.