This paper investigates the "illusion of stochasticity" in Large Language Models (LLMs), specifically their inability to reliably sample from probability distributions (e.g., Uniform, Gaussian) required for agentic tasks. Using frontier models like Gemini and Qwen3, the authors reveal that LLMs suffer from deep-seated distributional and positional biases when prompted to act randomly.
Executive Summary
TL;DR: New research from Google DeepMind and NUS reveals that frontier LLMs (Gemini, Qwen3) are mathematically "stochastic-blind." Even when a model perfectly describes a Gaussian distribution in its reasoning trace, it fails to sample from it, instead falling back on training data biases or positional preferences.
Background: This work positions itself as a critical diagnostic of the Agentic LLM paradigm. It argues that the "knowing-doing gap"—where models understand instructions but fail to execute them—is partly caused by a fundamental inability to simulate randomness.
1. The "C" Bias and the Knowing-Doing Gap
When you ask an LLM to generate a randomized multiple-choice test, it doesn't flip a coin. It has a "favorite" answer. As shown in the study, models like Gemini exhibit a massive bias toward placing the correct answer in position "C".
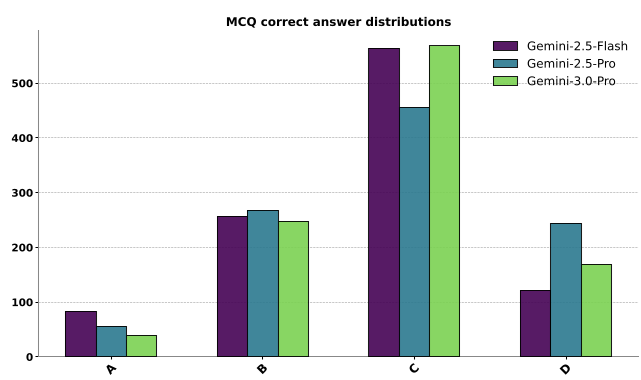
This isn't just a quirk; it’s a failure of reliable sampling. In an adversarial environment, an agent that is predictable is exploitable.
2. Why Can't LLMs Just Sample?
The study tested models on simple distributions: Uniform (Discrete/Continuous) and Gaussian.
The Methodology
The authors used Goodness-of-Fit (GoF) tests (Chi-Square and Kolmogorov-Smirnov). A p-value > 0.05 would indicate "real" randomness. The result? Almost every independent sampling test returned a p-value of 0.00.
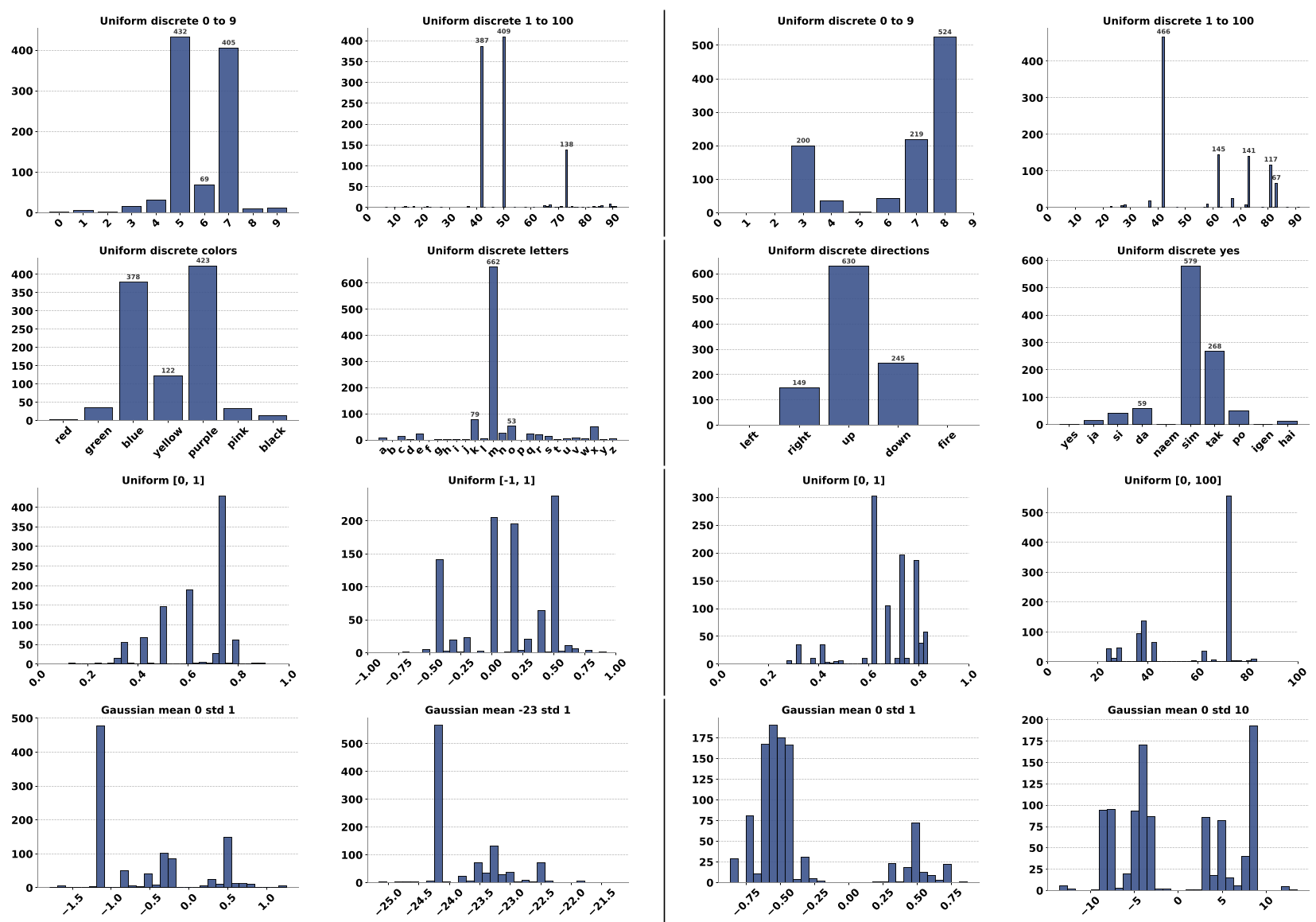
The Insights:
- Distributional Bias: Models love the numbers 7 and 42.
- Positional Bias: The order of options in the prompt changes the "random" choice.
- Temperature is not a Cure: Even at high temperatures (T=2.0), the fundamental bias toward specific values remains; the model just gets worse at following formatting instructions.
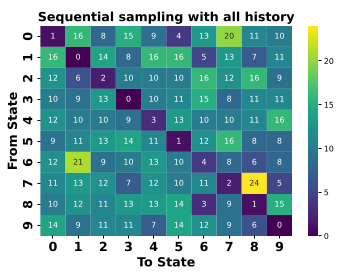
3. The Sequential Sampling Trap
Can we fix this by letting the model see what it picked before?
- Sequential with All History: Improves uniformity but creates "Repulsive Bias"—the model tries too hard not to repeat itself, leading to negative auto-correlation.
- Batched Sampling: Leads to "Periodic Patterns". The model might generate "0, 1, 2... 9" and then repeat that sequence, which is the opposite of true randomness.
4. The Silver Lining: Deterministic Conversion
The most fascinating finding is that LLMs can do math, they just can't "feel" randomness. When provided with an external uniform random seed (e.g., "Here is a number from [0, 1]: 0.639"), frontier models like Qwen3-32B and Gemini-3.0-Pro can execute complex Inverse Transform Sampling to convert that seed into a perfect Gaussian distribution.
Why does this work? Conversion is a deterministic process. LLMs are excellent at following algorithms (bucketization, probit functions) but terrible at originating stochastic states.
5. Critical Analysis & Future Directions
Limitations
- Computational Cost: Simulating a PRNG via Chain-of-Thought is slow and expensive for high-frequency agents.
- State Management: PRNGs are stateful; stateless API calls destroy the "randomness" chain unless the state is manually passed back and forth.
Final Takeaway
If you are building an AI agent that needs to explore an environment (like an RL agent) or randomize choices, do not ask the LLM to be random. Instead:
- Generate a seed using an external tool (Python
randomortime). - Pass that seed to the LLM.
- Let the LLM use its emergent deterministic reasoning to map that seed to the desired action space.
The future of agentic AI isn't in teaching models to "roll dice" internally, but in providing them with high-quality, stateful external samplers.