In-Place Test-Time Training (In-Place TTT) is a novel framework that enables Large Language Models to dynamically update their weights during inference to adapt to long-context streams. By repurposing existing MLP blocks as "fast weights" and using a theoretically grounded Next-Token-Prediction (NTP) objective, it allows a 4B model to outperform competitive baselines on 128k context tasks as a drop-in enhancement.
TL;DR
Modern LLMs are effectively "frozen" once deployed. In-Place Test-Time Training (In-Place TTT) changes this by turning standard MLP blocks into dynamic memory. By updating the final projection matrix of the MLP during inference using a specialized Next-Token Prediction objective, LLMs can now adapt to massive contexts (up to 128k and beyond) with negligible overhead and no need for architectural redesigns.
Background: The Limits of Static Intelligence
Standard LLMs operate on a "train then deploy" paradigm. While In-Context Learning (ICL) allows models to use recent information, it relies on the fixed capacity of the attention mechanism, which scales quadratically. Test-Time Training (TTT) proposes a "fast weights" approach—updating a subset of parameters on the fly. However, previous TTT attempts usually required custom layers that forced researchers to retrain models from scratch.
The Core Insight: MLPs as Dynamic Memory
The authors observe that MLP blocks already act as a form of key-value memory. Instead of adding a new, randomly initialized TTT layer, why not use the parameters we already have?
1. The In-Place Architecture
In-Place TTT targets the gated MLP architecture. It freezes the up and gate projections (the "slow weights") and treats the down projection () as the "fast weights." During inference, is updated using a gradient step for each chunk of tokens.
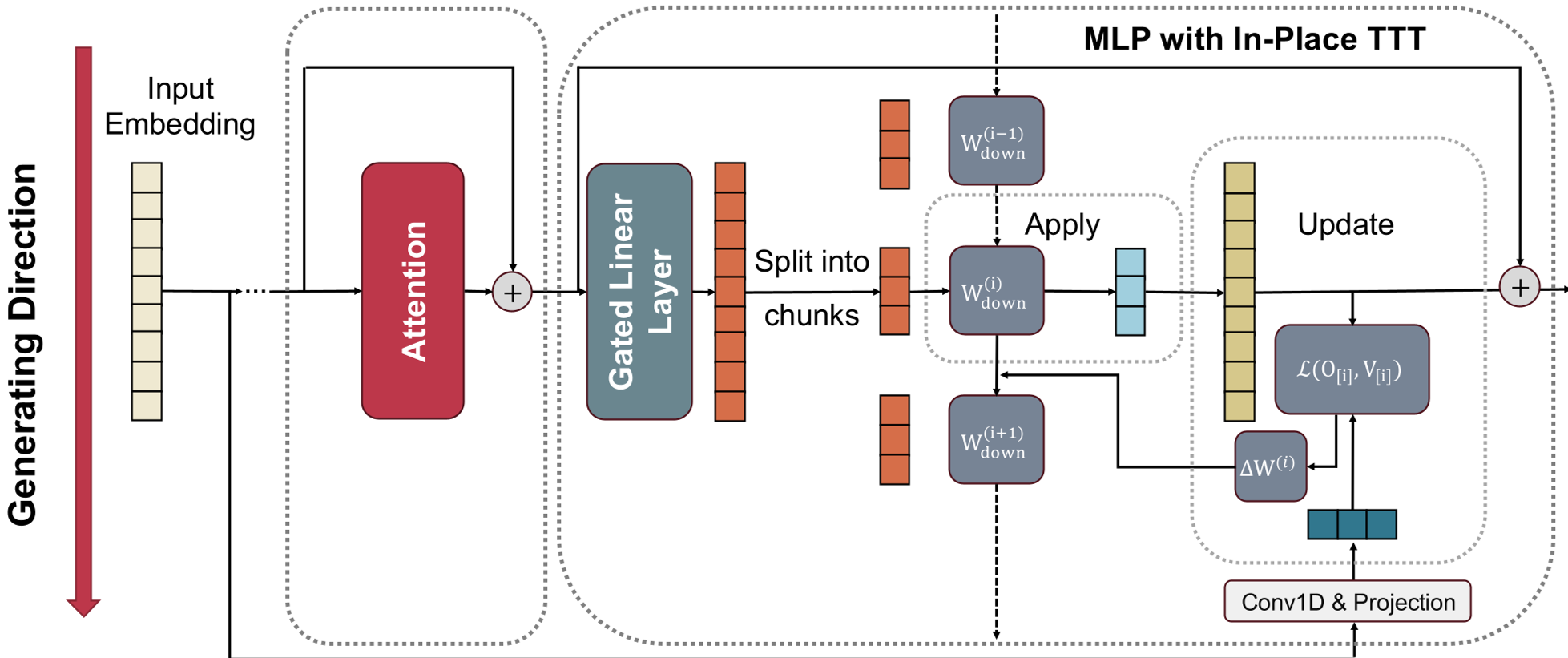 Figure 1: The model operates on input chunks, alternating between applying the current fast weights and updating them based on the new context.
Figure 1: The model operates on input chunks, alternating between applying the current fast weights and updating them based on the new context.
2. The NTP-Aligned Objective
Most TTT methods use a "reconstruction objective" (making the model remember the current token). The authors prove mathematically that this is suboptimal for autoregressive models. They introduce an LM-Aligned Objective:
- Current Target:
- Update: By including future token information via a 1D convolution, the fast weights are explicitly trained to store information that helps predict what comes next, not just what is happening now.
Experimental Performance
The framework was tested as a "drop-in" enhancement for Qwen3 and Llama-3.1.
Continuous Learning & Long Context
In the RULER benchmark, which tests the "effective" context size, the In-Place TTT enhanced Qwen3-4B showed a widening performance gap over the baseline as context length increased, even extrapolating successfully to 256k tokens.
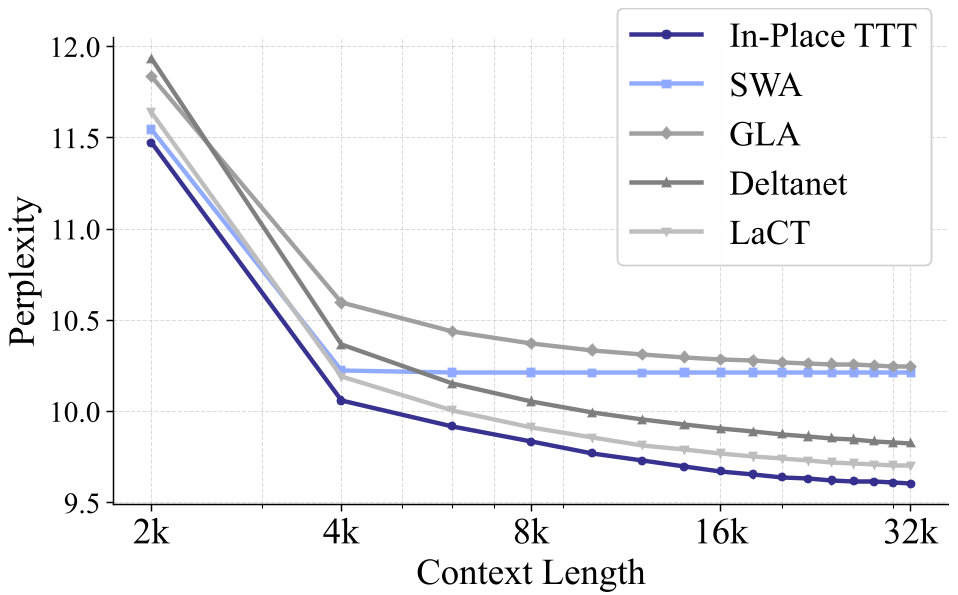 Figure 2: Sliding Window Perplexity comparison showing In-Place TTT (blue) consistently achieving lower error rates than GLA, DeltaNet, and SWA baselines.
Figure 2: Sliding Window Perplexity comparison showing In-Place TTT (blue) consistently achieving lower error rates than GLA, DeltaNet, and SWA baselines.
Efficiency and Scalability
One of the biggest concerns with TTT is the computational overhead. By using Chunk-Wise Updates and Context Parallelism (CP), In-Place TTT keeps throughput high. Experimental results show that the memory and speed overhead is negligible compared to standard full-attention models.
Critical Analysis & Conclusion
In-Place TTT represents a shift from "architectural innovation" to "functional repurposing." By showing that we don't need new layers to achieve TTT, the authors have made dynamic adaptation accessible to existing billion-parameter models.
Takeaways:
- MLPs are underutilized: They have massive capacity that can be converted into a dynamic context buffer.
- Objective Alignment Matters: Training fast weights to predict the next token is significantly more effective than simple auto-encoding.
- Practicality: Because it is "in-place," this can be applied to nearly any existing Transformer-based model with minimal continual training.
Limitations: While the overhead is low, it is not zero. The choice of which layers to "TTT-enable" (e.g., every 6th layer) remains a heuristic that might require tuning for different model families. However, as 2026 approaches, this work paves the way for LLMs that actually "learn" during your conversation.