The paper introduces an autoregressive diffusion framework for infinite-horizon gaze prediction in videos. By combining a U-Net-based diffusion backbone with a "saliency-aware" latent conditioning mechanism, the model generates continuous, high-resolution gaze trajectories that outperform existing scanpath models in spatio-temporal accuracy.
TL;DR
Researchers from NYU and Stanford have developed a generative framework capable of synthesizing "infinite" human gaze trajectories for videos. By combining Autoregressive Diffusion with Saliency-aware Latents, the model moves beyond static probability maps to create fluid, continuous eye movements that accurately reflect how humans track objects and react to scene dynamics over long durations.
Background: The Gap in Visual Attention
Predicting where humans look is critical for VR/AR foveated rendering and human-robot interaction. However, the field has been stuck between two extremes:
- Saliency Maps: Spatial "heatmaps" that lack any temporal order.
- Scanpaths: Discrete "jumpy" sequences (fixations) that ignore the smooth, high-frequency motion of the actual eye.
Most current models fail after 3-5 seconds because they lack a "memory" of past gaze behavior. This paper introduces a "World Model" approach for behavior—treating gaze as a continuous signal conditioned on the evolving video.
Methodology: Autoregression Meets Diffusion
The core of the method is a duo of technical innovations designed to handle the temporal complexity of video:
1. Autoregressive Gaze Cache
Instead of predicting a whole sequence at once, the model predicts the next segment (e.g., 45 frames) based on a "cache" of the previous 90 frames. This creates a causal chain that ensures temporal sliding-window consistency, effectively allowing for gaze generation of "infinite" length.
2. Saliency-Aware Latent Conditioning
Using raw RGB frames as a condition for diffusion is computationally expensive and noisy. The authors discovered that Saliency Latents (using a compressed UNISAL feature) act as a much stronger prior. By compressing these features into a small latent bottleneck (reducing channels from 256 to 64), they provide the model with a "distilled" map of visual importance.
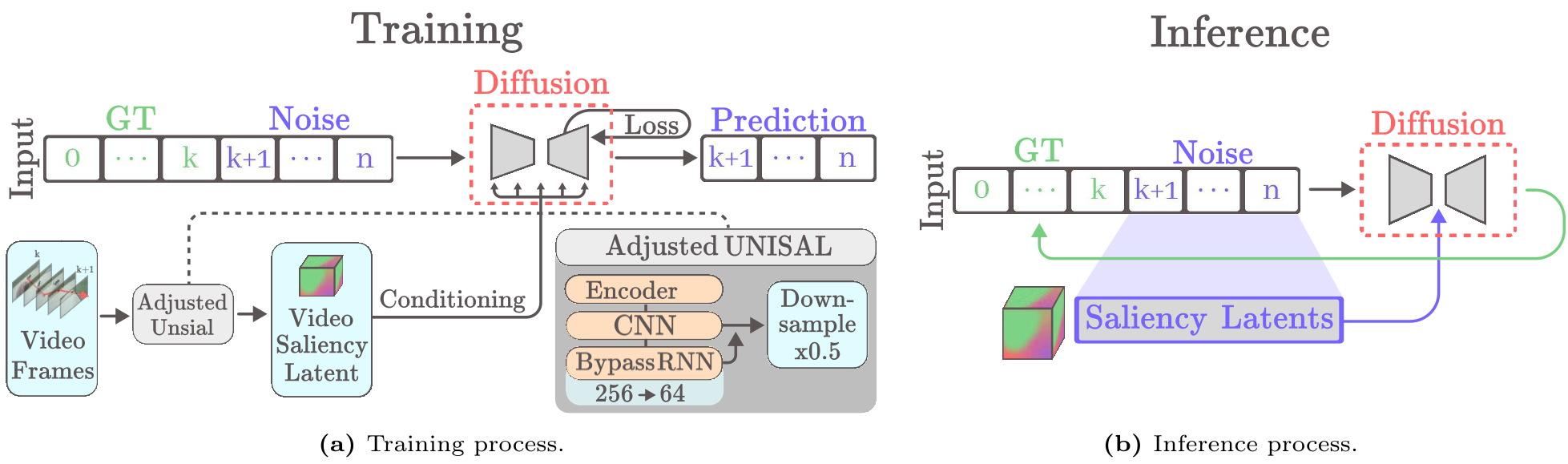 Figure 1: The framework uses a U-Net Diffusion backbone conditioned on both historical gaze coordinates and compressed saliency latents from the video frames.
Figure 1: The framework uses a U-Net Diffusion backbone conditioned on both historical gaze coordinates and compressed saliency latents from the video frames.
Experiments and Results
The model was tested on two major benchmarks: DIEM (in-domain) and DHF1K (generalization).
Quantitative Edge
The model excelled in Dynamic Time Warping (DTW) and Maximum Temporal Correlation. These metrics are crucial because they measure how well the timing and rhythm of the generated gaze match a human, rather than just the spatial location.
| Metric | Next Best Model | Ours | | :--- | :--- | :--- | | Levenshtein (↓) | 3.78 (DiffEye) | 3.40 | | Max Temp Corr (↑) | 0.272 (GazeFormer) | 0.314 |
Qualitative Realism
In a human subject study, users were asked to pick which trajectory looked more "human" compared to Ground Truth. The proposed method won in 85% of cases against TPP-Gaze, the strongest baseline. Unlike previous models that "jump" randomly, this model exhibits "Smooth Pursuit"—the ability to track a moving object across the screen naturally.
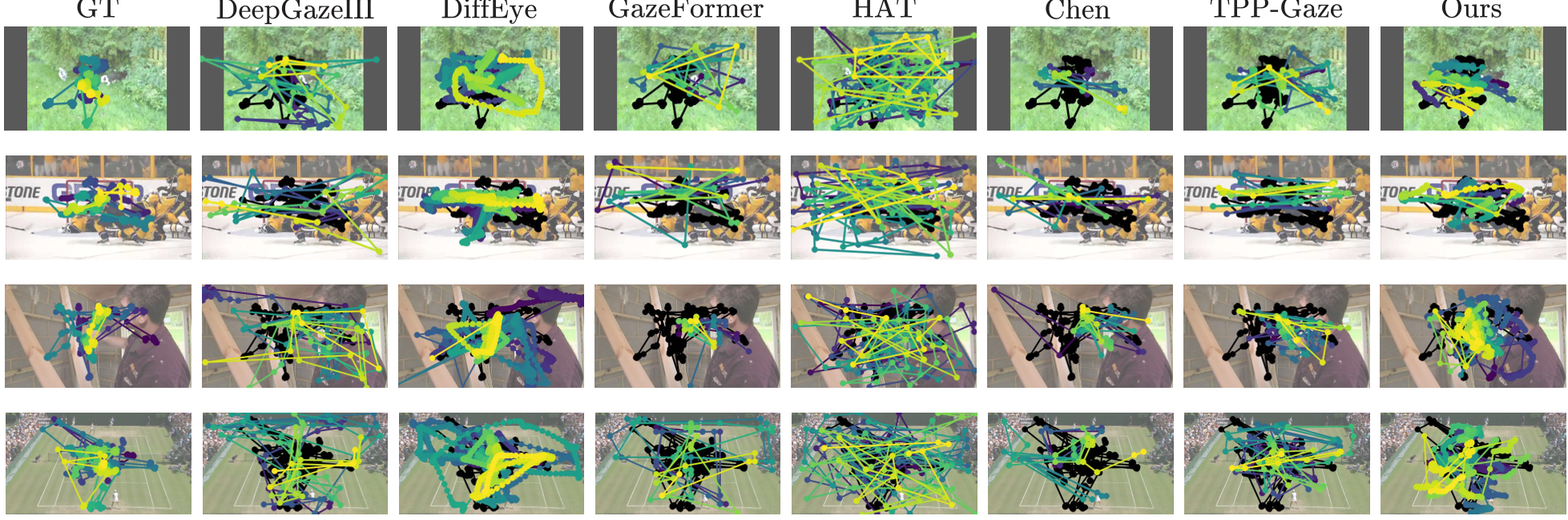 Figure 2: Qualitative comparison showing our model's (colored trajectories) tight alignment with human ground truth (black) across long video durations.
Figure 2: Qualitative comparison showing our model's (colored trajectories) tight alignment with human ground truth (black) across long video durations.
Critical Insight: Why Saliency Latents?
A key takeaway from the ablation study is that general-purpose visual tokens (like MAGVIT2) failed to converge. This suggests that inductive bias matters: tell the model what is "interesting" (via a saliency encoder), and it learns the "eye-tracking" task much faster and more stably than trying to understand the whole image pixels from scratch.
Limitations & Future Work
While the model generates realistic eye movements, it currently operates with a fixed head position. In the real world, eyes and head move in a coordinated "gaze-shift." The authors suggest that a future iteration could jointly model head orientation (6DoF) and eye coordinates for a truly immersive behavioral model.
Conclusion
By treating gaze prediction as an autoregressive diffusion problem, this paper provides a robust path toward "Human-Centric World Models." These models don't just predict what the world looks like; they predict how we will interact with it.
Takeaway: The marriage of autoregression (for long-term logic) and diffusion (for fine-grained detail) is the current SOTA recipe for simulating complex human behaviors.