本文推出了 InterLV-Search,这是一个专门用于评估“交织型视文智能搜索”(Interleaved Language-Vision Agentic Search)的新型基准测试。该基准涵盖了从主动视觉证据寻找、受控离线搜索到真实开放网络搜索的三个难度等级,并发布了配套的标准化评估框架 InterLV-Agent。
TL;DR
在传统的多模态任务看来,给模型一张图,让它回答图里有什么,或者是让它去网上搜一张图当作答案,这就算是完成任务了。但 InterLV-Search 告诉我们:这远远不够。真正的智能体应该能像人类一样,在网上看到一张海报上的 Logo 后,突然醒悟:“哦!以此为线索,我下一步得去查那个特定的赞助商”,这种视觉引导搜索路径的能力,正是当前 AI 的断板。
背景定位
目前多模态大模型(MLLM)在封闭域的推理上已经接近人类,但在开放世界搜索中,它们往往表现得像个“电子书呆子”:文字搜索很溜,但一旦涉及到需要从检索到的图片里挖掘线索并进行下一步行动时,就容易陷入死循环或丢失目标。InterLV-Search 是业内首个系统性挑战“交织型视文搜索”的 Benchmark,旨在将视觉证据从“答案”变为“逻辑转换点”。
痛点深挖:视觉证据不只是 Endpoint
现有的 Benchmark(如 MMSearch, VisBrowse)大多存在两个局限:
- 视觉证据受限:视觉信息要么一开始就给你了,要么是你搜寻的终点。
- 搜索链路单一:缺乏“看到图 A -> 产生搜索词 B -> 找到页面 C -> 发现图中细节 D -> 决定去查 E”这种复杂的跨模态反馈环。
作者认为,真实的视觉搜索是Pivot-based(基于枢纽的)。比如你要查一个 2024 年发布的专辑,如果不去看那张粉色调的封面并识别出其独特风格,你可能永远跳不到下一步关于联名电影的调研。
方法论详解:三级递进的“模态体操”
为了精准定位模型的能力边界,InterLV-Search 设计了三个等级:
1. Level 1: 视觉证据的主动搜寻
模型被告知一个模糊的实体描述,必须通过检索找到对应的图片并回答细节。这是基础:你得先学会如何“去找图”。
2. Level 2: 受控的离线交织链
在基于维基百科的知识图谱内进行。模型必须经历“文本->图像->图像->文本”的转换。
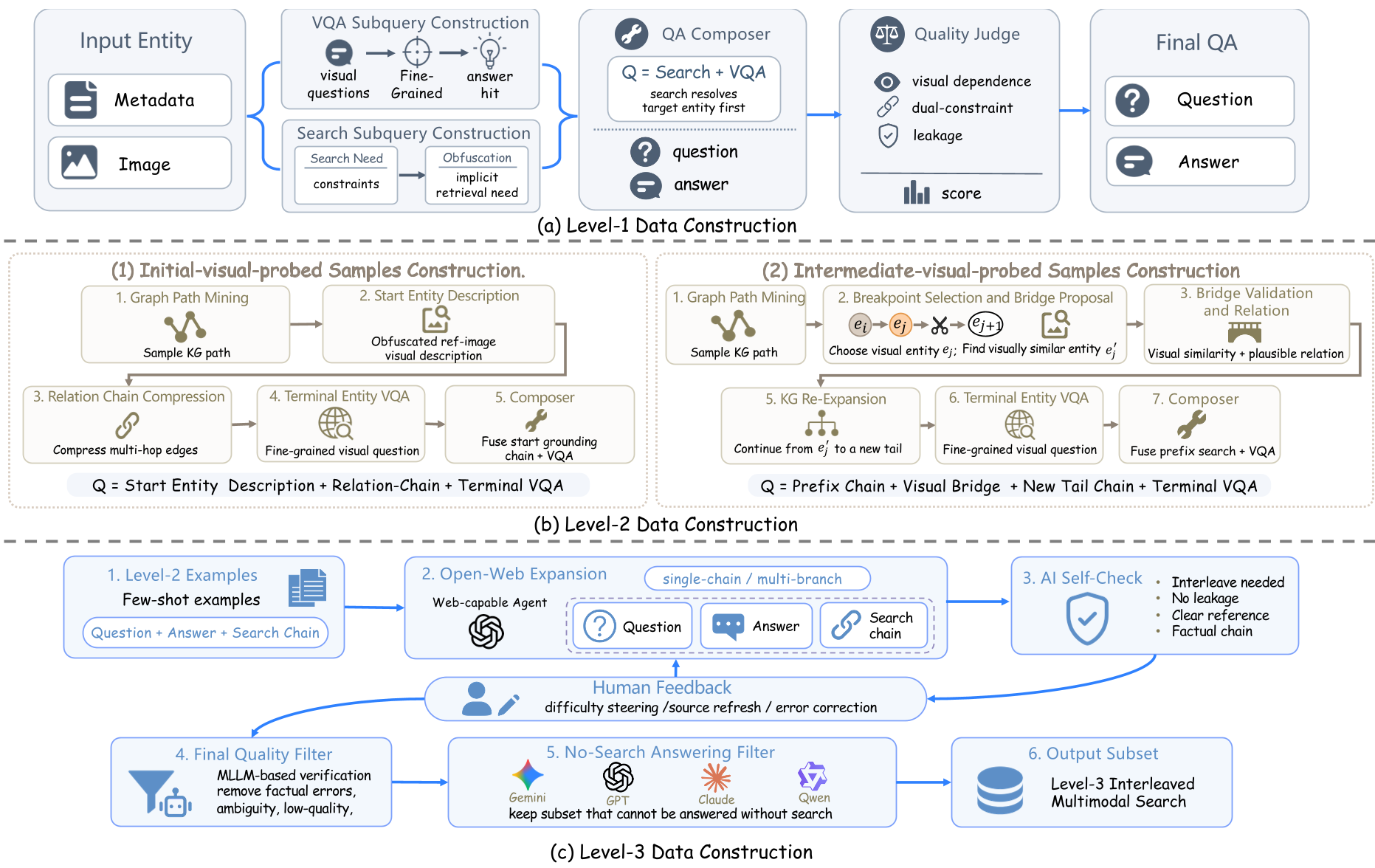 图 2:数据构建流水线。利用 LLM 作为生成器、作曲家和验证器,确保每条路径都必须通过视觉跳跃才能连通。
图 2:数据构建流水线。利用 LLM 作为生成器、作曲家和验证器,确保每条路径都必须通过视觉跳跃才能连通。
3. Level 3: 开放网络的多分支挑战
这是真实战。模型在互联网上冲浪,面对噪声巨大的网页和图片。特别引入了多分支任务:模型需要同时对比多个实体的视觉特征(例如比较三个电影节的海报细节),决定哪条路才是通往真相的唯一解。
实验与结果:强如 GPT-4o 也只勉强及格
作者通过 InterLV-Agent 框架测试了目前顶尖的模型,包括 GPT-5.4(内部代号)、Gemini 1.5 Pro 等。
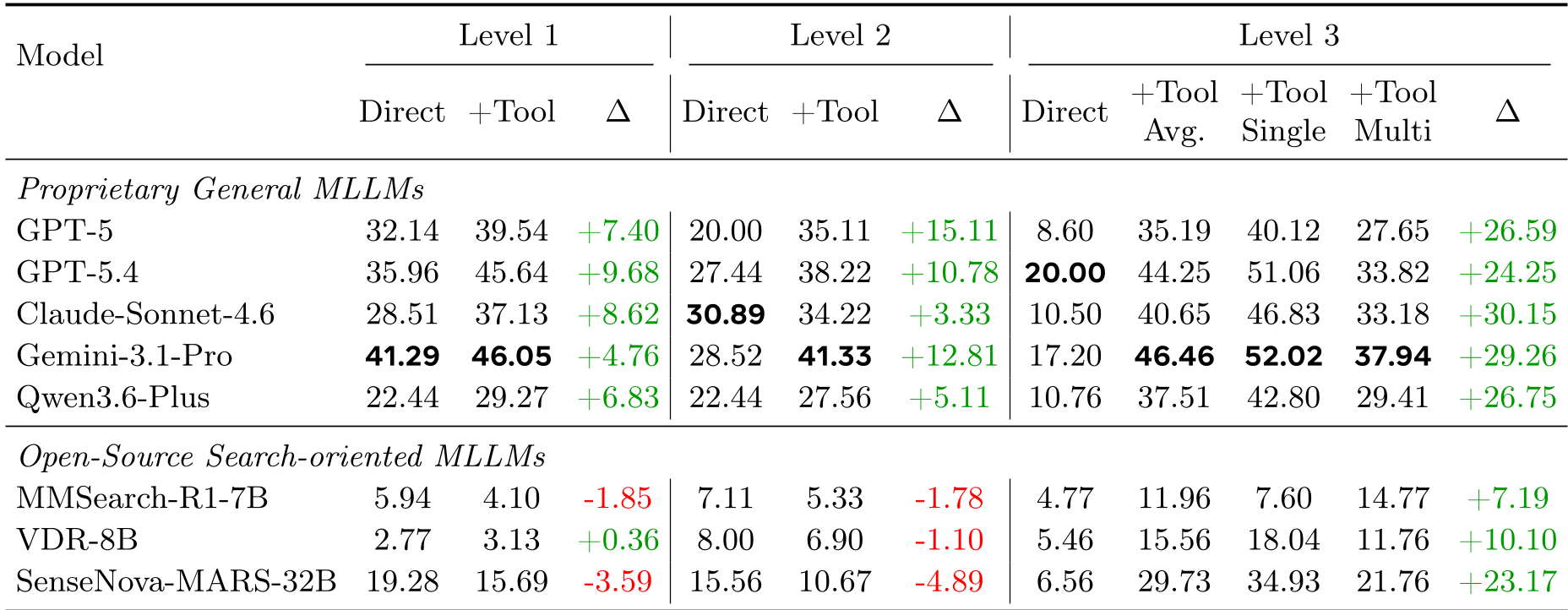 表 2:核心成绩单。我们可以清晰地看到,即使是表现最好的模型,在 Level 3 上的准确率也仅在 40% 左右波动。
表 2:核心成绩单。我们可以清晰地看到,即使是表现最好的模型,在 Level 3 上的准确率也仅在 40% 左右波动。
深度分析发现:
- 工具并非万能:开源模型(如 MMSearch-R1)在加入搜索工具后,表现甚至可能下降,说明它们的搜索规划(Planning)和证据集成(Integration)能力极不稳定。
- 视觉检索是瓶颈:实验显示,一旦视觉检索(Ret. R@5)失败,后续的回答几乎全军覆没。模型在从视觉线索提取“搜索关键词”这一步上极其拉胯。
案例实录:为什么 AI 会“看走眼”?
在文中的一个失败案例中,模型需要查一个关于双层巴士的旅游页面。
- 正确逻辑:看到巴士车身上的标志 -> 识别出是 COP30 气候大会的标志 -> 锁定主办城市贝尔蒙 -> 查找该州旗帜 -> 识别对角线颜色。
- AI 的失败:它仅仅在文字层面搜索“双层巴士”和“旅游”,完全忽略了车身涂装这个关键视觉枢纽,最终导致由于信息链断裂而只能乱猜颜色。
 图 9:一条完美的交织搜索轨迹展示。
图 9:一条完美的交织搜索轨迹展示。
总结与洞察
InterLV-Search 的价值在于它揭示了一个残酷的现实:当前的多模态模型仍然是“重理解,轻行动”。
- Takeaway 1:多模态 Agent 必须学会“以图搜文”。
- Takeaway 2:长程记忆(Memory)对于处理多分支搜索至关重要,模型需要记住在不同分支发现的中间结论。
- 未来展望:随着像推理模型(如 DeepSeek-R1, OpenAI o1)在多模态领域的泛化,我们期待看到具备“反思逻辑”的搜索 Agent 出现。
主编点评:这篇文章不只是出了个基准,它实际上是在给多模态 Agent 产品的设计者提了个醒:如果你的 Agent 不具备视觉引导的动作切换能力,它就永远无法在复杂的真实世界信息检索中胜任。