Intern-S1-Pro is the first trillion-parameter scientific multimodal foundation model, designed as a "Specializable Generalist." It leverages a massive Mixture-of-Experts (MoE) architecture to achieve state-of-the-art results across 100+ specialized scientific tasks and general AI benchmarks.
TL;DR
The Shanghai AI Laboratory has unveiled Intern-S1-Pro, the world’s first trillion-parameter scientific multimodal foundation model. By scaling the Mixture-of-Experts (MoE) architecture to unprecedented levels and introducing "Grouped Routing," the model doesn't just match human experts in chemistry, biology, and materials science—it often surpasses them. This work establishes a new paradigm: the Specializable Generalist, where massive scale and general reasoning capabilities actually enhance performance in niche scientific domains.
The Scaling Wall and the "Science Language" Gap
Most Large Language Models (LLMs) struggle with science because scientific data is fundamentally different from web text. Chemistry has formulas, biology has protein sequences, and earth sciences rely on complex time-series signals.
Existing models faced two major bottlenecks:
- Expert Imbalance: In massive MoE models, certain "popular" experts get overloaded, leading to memory spikes and training crashes (OOM).
- Gradient Sparsity: Standard routing only updates the "top-k" experts, leaving the rest of the trillion-parameter brain "undertrained."
Methodology: Engineering a Scientific Giant
1. Grouped Routing: Stability at Scale
To solve the MoE imbalance, Intern-S1-Pro introduces Grouped Routing. Instead of letting every token compete for every expert globally, experts are partitioned into mutually disjoint groups mapped to specific hardware devices. Each group must activate its own top experts, ensuring an absolute load balance across the GPU cluster.
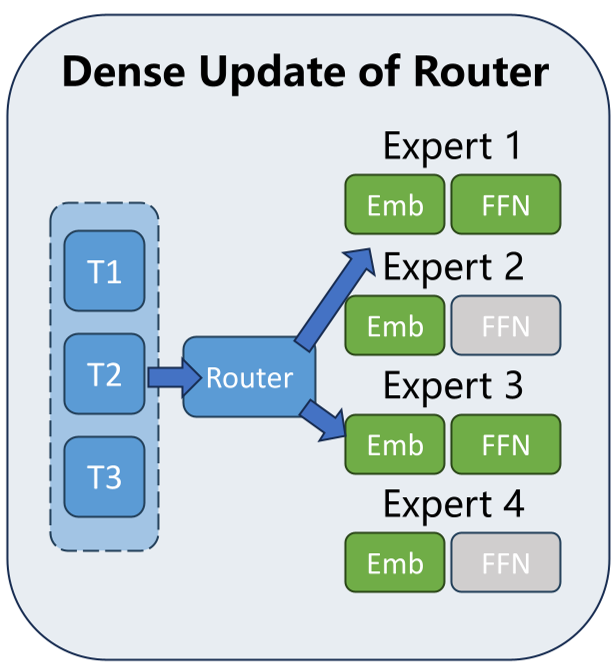 Figure: The expert expansion process and the Grouped Routing design that prevents training instability.
Figure: The expert expansion process and the Grouped Routing design that prevents training instability.
2. The Straight-Through Estimator (STE)
The authors tackled the "dead expert" problem by using a Straight-Through Estimator. While the model only uses 8 experts for inference (efficiency), the backward pass sends gradients through the entire probability distribution. This ensures that the router's "decision-making brain" learns from every single piece of data, not just the experts it chose.
3. Native Time-Series & Vision
Unlike general models that treat time-series as text, Intern-S1-Pro features a dedicated Time-series Encoder with adaptive subsampling. It can handle sequences from 100 to 1,000,000 time steps—crucial for monitoring everything from marmoset vocalizations to earthquake signals.
Experimental Results: The Death of the "Niche Specialist"?
One of the most provocative findings in the paper is found in Section 5.5. The team compared Intern-S1-Pro against a model specifically trained only for biology.
The Result? Intern-S1-Pro, despite being a generalist, crushed the specialist model on the same biological data. On the Protein-Fluorescence task, the specialist scored 2.57, while Intern-S1-Pro scored 78.14.
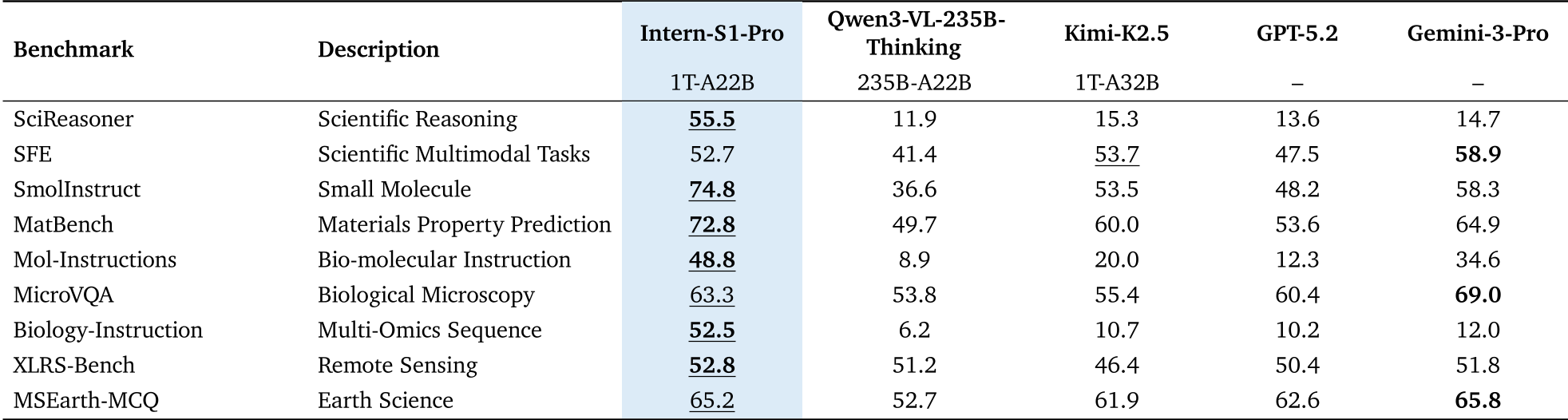 Table: Comparison across SciReasoner, SFE, and other expert-level benchmarks.
Table: Comparison across SciReasoner, SFE, and other expert-level benchmarks.
In broader benchmarks, Intern-S1-Pro scored 55.5 on SciReasoner, dwarfing GPT-5.2 (13.6) and Gemini-3-Pro (14.7).
Deep Insights: Why Does Scale Help Science?
The key takeaway is Synergistic Intelligence. Scientific discovery isn't just about memorizing facts; it's about reasoning through complex, multi-step workflows. By being a "Specializable Generalist," Intern-S1-Pro uses its massive general reasoning "muscles" (derived from 6T tokens of diverse data) to better interpret the structured, rigid logic of scientific data.
The introduction of System Prompt Isolation—where the model uses distinct internal "workspaces" for general and scientific tasks—prevents the creative, fluid nature of natural language from "polluting" the deterministic logic required for chemical synthesis or material property prediction.
Conclusion & Future Outlook
Intern-S1-Pro isn't just a bigger model; it's a structural rethink of how AI interacts with the physical world. By integrating time-series, high-resolution vision (via FoPE), and a trillion-parameter MoE core, it moves us closer to an "AI Scientist" capable of autonomously planning and executing complex research.
Limitations: While memory-efficient due to MoE, RL training at this scale still requires extreme precision (FP8/BF16 mixed) to avoid divergence, suggesting that the barrier to entry for such models remains incredibly high.
Technical Summary: Trillion-parameter MoE, Grouped Routing, SciReasoner SOTA, 6T token pre-training.