The paper introduces LEAFE (Learning Feedback-Grounded Agency from Reflective Experience), a post-training framework that internalizes error-recovery capabilities into LLM agents. It achieves SOTA gains in long-horizon tasks like CodeContests and WebShop, notably improving Pass@128 by up to 14%.
TL;DR
Standard RL for agents often hits a ceiling because it only rewards success, ignoring the "why" behind failures. LEAFE changes this by teaching models to backtrack and fix mistakes. By distilling these "reflective" traces back into the model weights, LEAFE expands the model's problem-solving capacity (Pass@k), achieving up to a 14% boost in complex coding tasks.
The Problem: The "Echo Chamber" of Reward-Based RL
Most current LLM agents are trained using Outcome-based RL (RLVR) like GRPO. While effective for simple reasoning, this approach has a hidden flaw: Distribution Sharpening.
Instead of learning new ways to solve problems, the model simply gets better at repeating the few successful paths it already knew. In long-horizon tasks (like web navigation or complex coding), if the agent makes one wrong turn, it stays lost. This is because traditional RL treats environment feedback (like "Invalid Action" or "Syntax Error") as a simple binary "0", wasting the rich diagnostic information provided by the environment.
Methodology: The LEAFE Framework
The authors propose LEAFE (Learning Feedback-Grounded Agency from Reflective Experience), a two-stage pipeline designed to move from outcome-matching to agency-internalization.
Stage 1: Tree-Based Experience Generation
Instead of linear rollouts, LEAFE builds an Exploration Tree:
- Periodic Reflection: Every few steps, the agent evaluates its progress.
- Rollback & Summarization: If failing, the agent identifies the exact step where it went wrong and writes a "Experience Summary" (e.g., "I should have checked the inventory first").
- Branching: The environment is reset to that step, and the agent tries again using the summary as a guide.
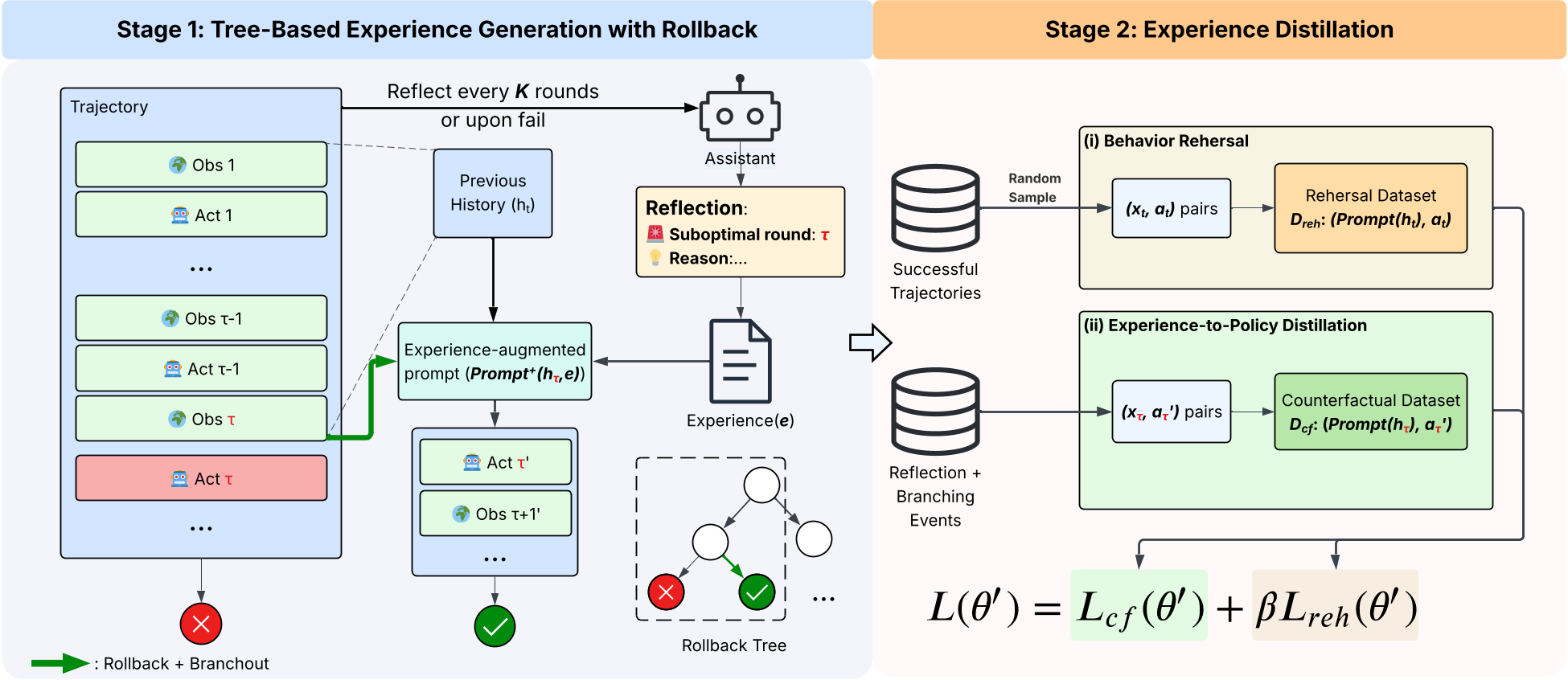
Stage 2: Experience Distillation
The "magic" happens here. The authors fine-tune the model using two losses:
- (Behavior Rehearsal): Keeps the model good at what it already knows.
- (Counterfactual Distillation): Trains the model to take the corrected action even when the "Experience Summary" is NOT present. This forces the model to internalize the logic of recovery into its own parameters.
Experiments: Expanding the Capability Boundary
The most striking result of LEAFE is its Pass@k scaling. While GRPO often plateaus early, LEAFE continues to improve as you give it more attempts (samples).
Key Results on CodeContests & Agent Benchmarks
| Method | Pass@1 | Pass@128 | | :--- | :--- | :--- | | GRPO-RLVR (Qwen2.5-72B) | 20.45% | 36.97% | | LEAFE (Ours) | 17.12% | 47.88% |
Notice the trade-off: GRPO might have a higher Pass@1 (exploitation), but LEAFE has a vastly higher Pass@128 (capability). This proves that LEAFE actually expands the "knowledge support" of the model.
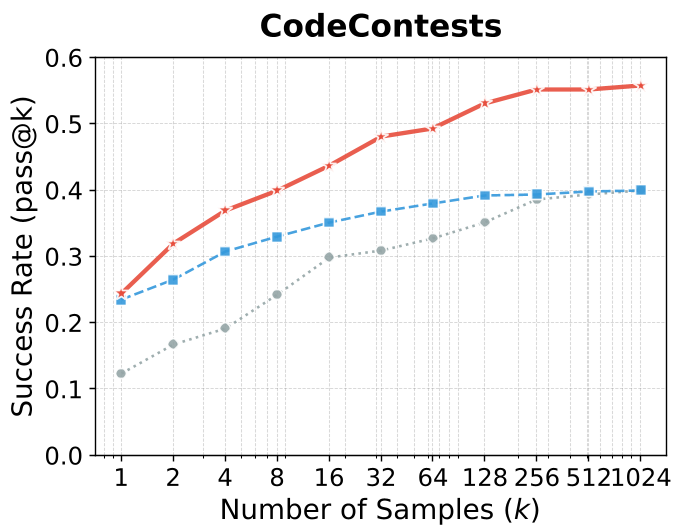
Figure: The red line (LEAFE) shows superior sample efficiency and a higher performance ceiling compared to standard RL (blue).
Critical Insight: Why Does This Work?
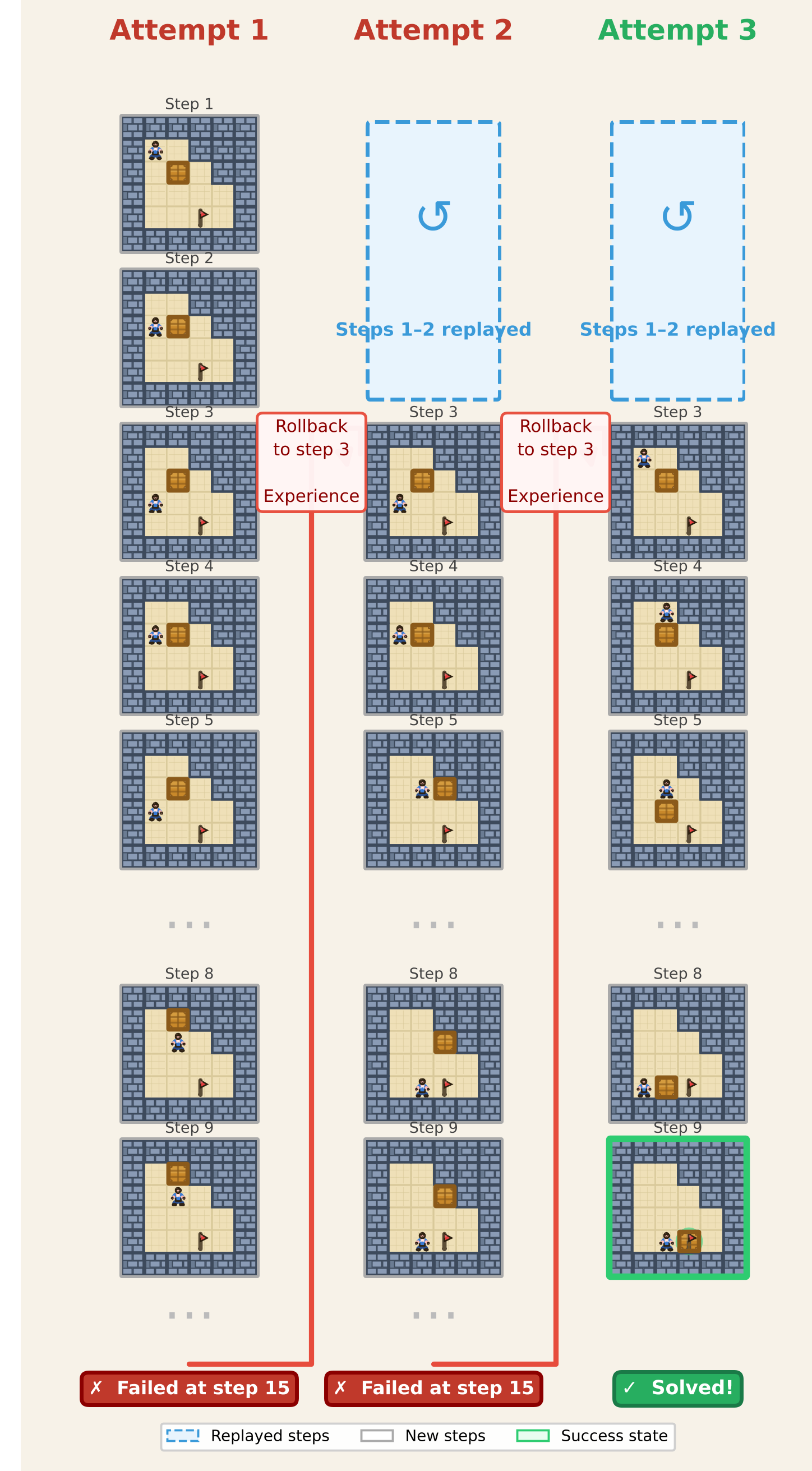
The core "Inductive Bias" here is that error recovery is a learnable skill. In ScienceWorld or Sokoban (pictured below), solving the task requires a specific sequence of "logical pivots." By explicitly supervising the model on these pivots (the rollback points), the authors provide a much denser training signal than a single scalar reward at the end of a 50-step trajectory.
Conclusion & Limitations
Takeaway: LEAFE demonstrates that for autonomous agents, learning from "the road not taken" is just as important as learning from success. It effectively shifts the burden from heavy test-time compute (like Tree-of-Thought search) to the model’s intrinsic weights.
Limitations:
- Requires a verifiable environment that supports "Reset/Rollback."
- Effectiveness depends on diagnostic feedback quality; if the environment just says "Error" without details, the reflection phase becomes much harder.
LEAFE represents a significant step toward agents that don't just follow instructions, but actively debug themselves.