本文提出了 Kestrel,一个专为减轻大型视觉语言模型(LVLM)幻觉而设计的无需训练(Training-free)的框架。该框架通过整合显式视觉 Grounding 智能体与证据驱动的迭代自精炼机制,在 POPE 和 MME-Hallucination 基准测试中显著提升了模型表现。
TL;DR
幻觉一直是大型视觉语言模型(LVLM)大规模部署的“拦路虎”。来自 UC Santa Cruz、Apple 等机构的研究者提出了 Kestrel,这是一个无需额外训练的通用框架。它通过将复杂的视觉判断分解为可验证的断言,并引入外部智能体辅助获取硬核视觉证据,实现了对幻觉的精准打击。在主流基准测试中,它不仅大幅刷新了 SOTA,还为模型的每一次修正提供了可追溯的审计链。
背景定位:为何现有的“减幻”方案不够好?
目前的减幻方案主要分为两大派系:
- 训练派:通过强化学习(RLHF)或高质量数据微调。缺点是:太贵!且模型参数一旦更新,灵活性较差。
- 推理派(Training-free):如 VCD、OPERA。虽然便宜,但它们大多在“盲猜”——仅通过调整解码概率来规避幻觉,缺乏对图像事实的物理级校验。
作者敏锐地指出,现有的推理派方案常因“一锤子买卖”式的修正导致过度修正(Over-correction),即把对的改错了。
核心机制:Kestrel 的“法庭审判”流程
Kestrel 的运作方式像极了一个严谨的法庭纪检流程,分为四个核心阶段:
1. 初始化与断言分解
模型首先给出一个原始答案,Kestrel 会将其拆解为多个断言(Claims)。例如,“图中有一个红色的杯子”会被分解为:
- 存在性(是否存在杯子?)
- 属性(杯子是红色的吗?)
2. 智能体 Grounding:获取“铁证”
Kestrel 调用了名为 SAM3 的先进定位智能体。它不只是简单的目标检测,还会生成:
- 分割掩码(Segmentation Overlays):精确圈出物体。
- 局部放大图(Crop-and-zoom):消除视觉模糊。
- 结构化文本证据:将“在此坐标发现物体”转化为法官能读懂的文字。
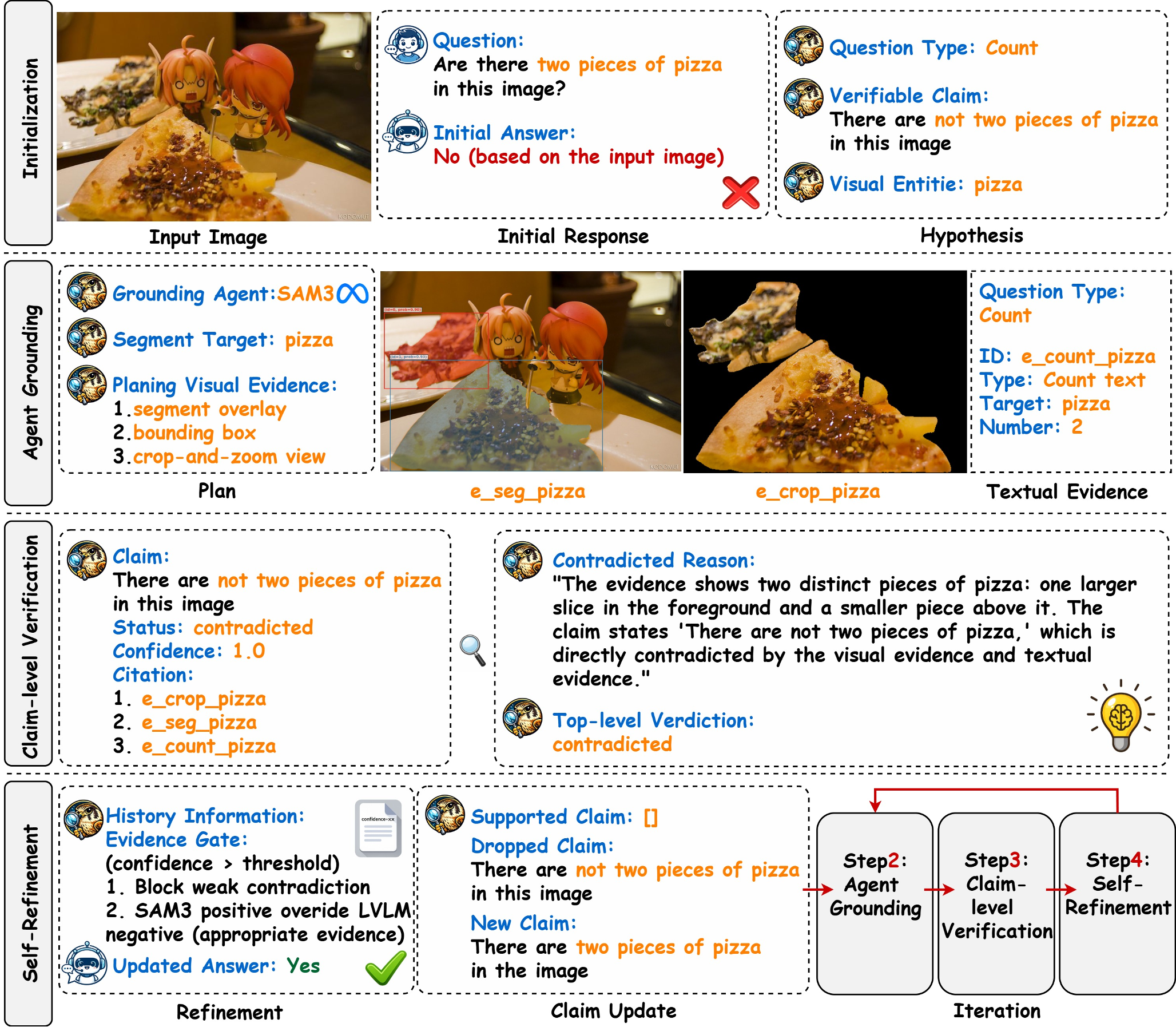
3. 断言级验证
LVLM 扮演“大法官”,根据上一步提取的证据逐一核对断言,并给出置信度分数。
4. 证据门控自精炼
这是 Kestrel 最精妙的地方。它不会盲目相信修正建议。只有当证据足够强、置信度足够高时,才会允许模型翻转(Flip)答案。这种“保守派”策略极大地降低了误伤正确答案的概率。
实验战绩:全线突破
在 POPE 这一经典幻觉测试集上,Kestrel 展示了统治力:
- Qwen3-VL 8B:在 MS-COCO 任务上提升显著,平均超越基线 3% 以上。
- InternVL3.5 8B:即使在如此强大的基座模型上,Kestrel 依然能挖出连模型本身都没意识到的错误。

在具体的错误分布分析中(图 4),我们可以看到 Kestrel 成功修正了大量的错误预测(Error Corrected),而过度修正(Over-corrected)的比例被压制在极低水平,验证了其“保守修正”策略的有效性。
深度洞察:为什么 Kestrel 有效?
- 物理直觉的引入:传统的 Attention 机制容易被统计偏见(例如:看到键盘就认为旁边有鼠标)带偏。Kestrel 通过 SAM3 的物理分割强制模型“看清”实际像素,利用 Inductive Bias 抵消了语言模型的先验偏见。
- 状态化迭代:Kestrel 是有记忆的。在多轮精炼中,它会优先核对上一轮中不确定的断言,形成了一个自我补全的逻辑闭环。
局限性与展望
尽管理想,Kestrel 的缺点也显而易见:推理延迟。由于涉及多次工具调用和 LVLM 判别,整体耗时比单次推理慢了约 24 倍(见表 3)。作者也坦诚,未来需要研究如何通过“自适应调用”等策略来优化效率。
总结
Kestrel 证明了在无需重训练模型的前提下,通过构建一套严密的“证据收录-逻辑核验-保守更新”系统,可以极大地提升 LVLM 的可靠性。在追求 AGI 的道路上,这种具备自我反思和事实对齐能力的设计,或许比单纯增加参数量更为关键。