Kimodo is a high-capacity kinematic motion diffusion model developed by NVIDIA for controllable 3D human motion generation. Trained on the massive "Bones Rigplay" dataset (700 hours of optical mocap), it achieves state-of-the-art results in motion quality and precise control using text prompts and complex kinematic constraints like keyframes and 2D paths.
TL;DR
NVIDIA researchers have unveiled Kimodo, a powerful diffusion-based generative model that bridges the gap between creative text-to-motion and precise technical animation. By training on 700 hours of pristine optical motion capture data and employing a clever two-stage denoiser, Kimodo allows users to generate high-fidelity human and robot motions using a mix of text descriptions, 2D paths, and 3D keyframes.
Background: The Scalability Wall
For years, the human motion synthesis field has been "stuck" on the HumanML3D benchmark—a dataset with only 30 hours of motion. While researchers tried to scale by scraping "noisy" motions from internet videos, the resulting models often suffered from physical inaccuracies (e.g., floating feet, jitter). Kimodo breaks this wall by proving that data quality matters as much as quantity, leveraging a massive professional studio dataset to achieve production-grade results.
Methodology: Engineering the "Physical Intuition"
The core innovation of Kimodo lies in how it represents and denoises motion. Instead of a single "black box" transformer, the authors use a Two-Stage Transformer Denoiser.
1. Decomposed Representation
- Root Stage: First, a dedicated transformer predicts the global trajectory (root motion).
- Body Stage: A second transformer predicts the skeletal pose relative to that root.
- Why it works: By separating the "where the person is going" from "how their limbs move," the model avoids the mathematical instability caused by rapid rotations (like somersaults), significantly reducing "foot skating."
2. The Smoothed Root Insight
Standard models use the pelvis as the root. However, the pelvis bobs up and down and sways side-to-side during walking. Kimodo uses a Smoothed Root Representation, providing a stable reference frame that mimics how animators draw "motion paths" in professional software.
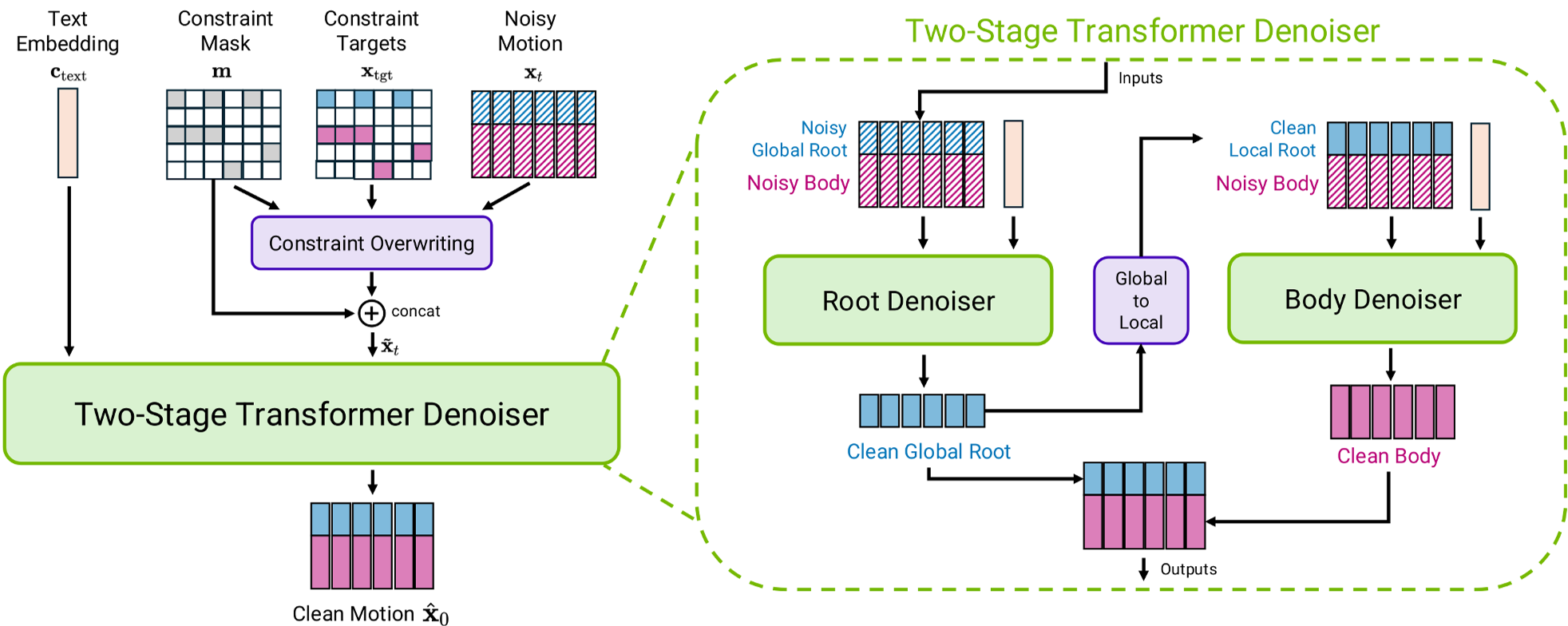 Figure: The Two-Stage Denoiser Architecture showing the flow from global root prediction to local body denoising.
Figure: The Two-Stage Denoiser Architecture showing the flow from global root prediction to local body denoising.
Experiments: The Power of Scale
The researchers conducted an extensive "scaling law" analysis, proving that human motion generation follows similar trends to LLMs:
- Data Size: Increasing data from 70 hours to 700 hours drastically improved the model's ability to follow precise constraints.
- Model Capacity: A "Large" model (282M parameters) outperformed "Small" variants in nuances like dancing and combat styles.
- Direct Control: Unlike prior models that required "test-time optimization" (slow), Kimodo uses direct imputation, allowing it to "overwrite" noise with user constraints instantly.
 Figure: Demonstrating diverse control—from sparse 2D waypoints to dense 3D joint constraints.
Figure: Demonstrating diverse control—from sparse 2D waypoints to dense 3D joint constraints.
From Humanoids to Robots
One of Kimodo's most exciting applications is in Robotics. By retargeting the 700-hour dataset to the Unitree G1 robot skeleton, the authors enabled the robot to "hallucinate" complex recovery motions and object interactions directly from text, bypassing the need for expensive real-world teleoperation.
 Figure: Kimodo generating diverse 'put down' motions for the Unitree G1 robot.
Figure: Kimodo generating diverse 'put down' motions for the Unitree G1 robot.
Critical Insight & Conclusion
Kimodo represents a shift from "toy benchmarks" to "production utility." Its success underscores two major takeaways:
- Architecture Matters: The interleaved two-stage approach is the superior way to handle the hierarchical nature of human skeletons.
- Guidance Logic: By decomposing text and constraint guidance (via and ), users gain fine-grained control over the "creativity" vs. "precision" of the output.
While Kimodo is currently an "offline" authoring tool taking 2-5 seconds per clip, it sets the stage for the next generation of real-time, physically reactive AI agents in gaming and industrial simulation.