Kinema4D is a novel action-conditioned 4D generative world model for embodied AI. By disentangling robot control via URDF-based kinematics from environmental reaction synthesis using a Diffusion Transformer, it achieves SOTA performance in simulating physically plausible and geometrically consistent robot-world interactions.
TL;DR
Kinema4D is a breakthrough in Embodied AI simulation that moves beyond 2D video generation. By combining URDF-based kinematics with 4D diffusion transformers, it creates a world model that understands both "what" a robot does and "how" the environment geometrically reacts. With the release of Robo4D-200k, it provides a foundation for zero-shot transfer from simulation to real-world robotics.
Problem & Motivation: The 2D Bottleneck in a 4D World
Standard physical simulators (like MuJoCo) are fast but lack visual realism and require manual tuning of friction and mass. Conversely, recent generative world models (like UniSim or Ctrl-World) offer high visual fidelity but fail at precision.
The authors identify a "trilemma" of dynamics, precision, and spatiotemporal awareness. Most 2D-based models "guess" robot movement from latent tokens, leading to floating arms or "hallucinated" interactions where a gripper passes through a solid object. Kinema4D argues that robot actions are deterministic physical certainties that should guide the generative process, not be part of the prediction.
Methodology: Disentangling Control from Reaction
The core innovation of Kinema4D is the disentanglement of the simulation into two synchronized stages:
1. Kinematic Control (The Causal Driver)
Instead of passing a vector of joint angles to the model, the system:
- Reconstructs a 3D robot asset from sparse orbit videos.
- Uses Inverse Kinematics (IK) to map actions onto a URDF-based chain.
- Projects the resulting movement into a 4D pointmap sequence. This serves as a precise "visual skeleton" that provides the model with exact 3D occupancy data over time.
2. 4D Generative Modeling (The Reactive Engine)
The model uses a Diffusion Transformer (DiT) architecture to fill in the rest. It takes the robot pointmap as a hard constraint and "reasons" about the environment's response. Because it outputs both RGB and Pointmaps, the generated world is geometrically rigorous—every pixel has a depth value that follows the laws of 3D space.
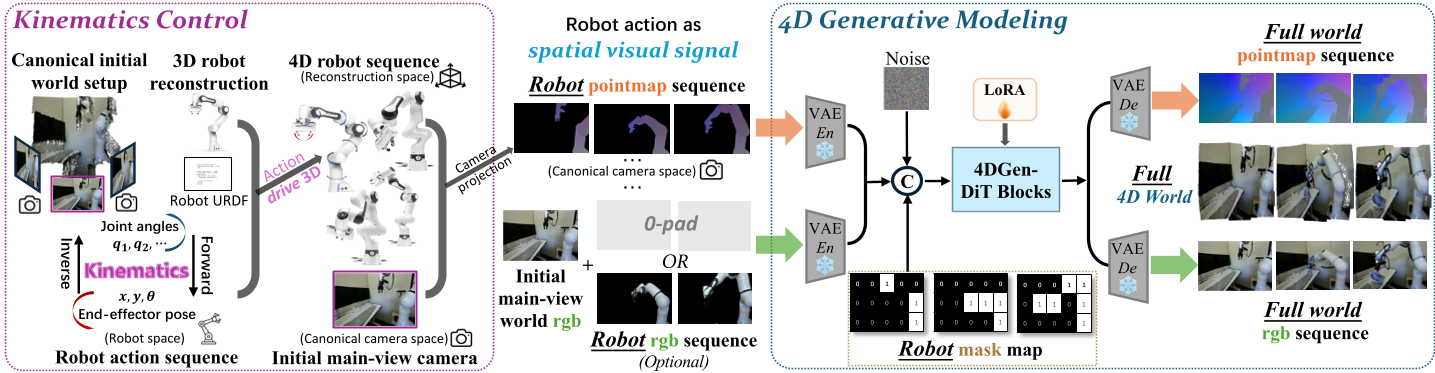 Figure 1: The dual-phase pipeline of Kinema4D, showing the transition from kinematic projection to 4D latent reasoning.
Figure 1: The dual-phase pipeline of Kinema4D, showing the transition from kinematic projection to 4D latent reasoning.
Robo4D-200k: A New Scale of Data
To train such a massive model (14B parameters), the authors curated Robo4D-200k. They unified datasets like DROID, Bridge, and RT-1, using state-of-the-art 4D tracking (ST-v2) to "lift" 2D videos into the 4D metric space. This is currently the largest-scale dataset of its kind, featuring over 200,000 high-quality 4D interaction episodes.
Experiments & Results: Beyond Visual Fidelity
Kinema4D was tested against SOTA generative models across various metrics. Key highlights include:
- Geometric Precision: In 4D evaluations (Chamfer Distance), it significantly outperformed TesserAct, proving that text-guided models cannot match the precision of kinematic-guided models.
- Near-Miss Realism: One of the most impressive feats is the ability to simulate "near-miss" failures. Because the model understands 3D gaps, it correctly shows a gripper failing to grab a block if the kinematics indicate a spatial offset, even if a 2D view looks like they are touching.
 Table 1: Kinema4D leading across PSNR, SSIM, and FVD metrics.
Table 1: Kinema4D leading across PSNR, SSIM, and FVD metrics.
 Figure 2: Visualizing the difference between TesserAct (hallucinated) and Kinema4D (ground-truth aligned).
Figure 2: Visualizing the difference between TesserAct (hallucinated) and Kinema4D (ground-truth aligned).
Critical Insight & Future Outlook
Takeaway: The success of Kinema4D suggests that for embodied AI, embodiment-agnostic modeling is possible. By converting robot-specific actions into a universal pointmap representation, the model can learn from any robot (Franka, UR5, or Mobile Alphas) without being confused by their specific joint configurations.
Limitations: While the model is geometrically consistent, it still lacks explicit physics solvers. It may occasionally violate conservation laws (e.g., objects clipping during high-speed collisions). Integrating differentiable physics into the 4D latent space is the next logical frontier.
Conclusion
Kinema4D represents a shift from "Video Generation" to "World Simulation." By anchoring digital imagination in kinematic reality, it provides a high-fidelity sandbox for training the next generation of generalist robot policies.