LaMP (Latent Motion Prior) is a dual-expert Vision-Language-Action (VLA) framework that integrates dense 3D scene flow as a geometric motion prior. By aligning a flow-matching Motion Expert with an Action Expert via gated cross-attention, it achieves SOTA results on LIBERO, LIBERO-Plus, and SimplerEnv-WidowX, notably outperforming π0.5 and OpenVLA.
TL;DR
Researchers have introduced LaMP (Latent Motion Prior), a dual-expert framework that bridges the gap between 2D visual semantics and 3D physical control. By predicting 3D scene flow as an intermediate "latent plan," LaMP allows robots to anticipate physical movements before executing them. It sets new benchmarks across LIBERO and SimplerEnv, proving that 3D geometric foresight is the key to solving long-horizon and out-of-distribution (OOD) manipulation tasks.
The "Representational Mismatch" Problem
Most modern Vision-Language-Action (VLA) models (like OpenVLA or π0) operate by "looking" at a 2D image and "guessing" the next motor command. This works for simple tasks but fails when precision is required.
The fundamental issue is a representational mismatch:
- VLM features are semantic and 2D-centric (optimized for "What is this?").
- Robot manipulation is geometric and 3D-centric (requiring "Where is this moving?").
When a robot encounters a new camera angle or a shifted object, these 2D-centric models often collapse because they never truly understood the 3D dynamics of the scene.
Methodology: The Dual-Expert Architecture
LaMP solves this by introducing a Motion Expert that acts as a world model. Instead of jumping straight to actions, the model first generates a latent motion prior.
1. Dense 3D Scene Flow
Unlike 2D optical flow, LaMP predicts displacements in $(u, v, d)$ space—incorporating depth. This captures scene-level geometry that is "embodiment-agnostic," meaning the motion representation stays the same even if the robot arm changes.
2. Gated Motion Guidance
Merging new 3D features into a pretrained VLM often ruins the original semantic knowledge (Representational Collapse). LaMP uses Gated Cross-Attention, starting with a gate value near zero and allowing the model to "learn" how much 3D foresight it needs for a specific task.
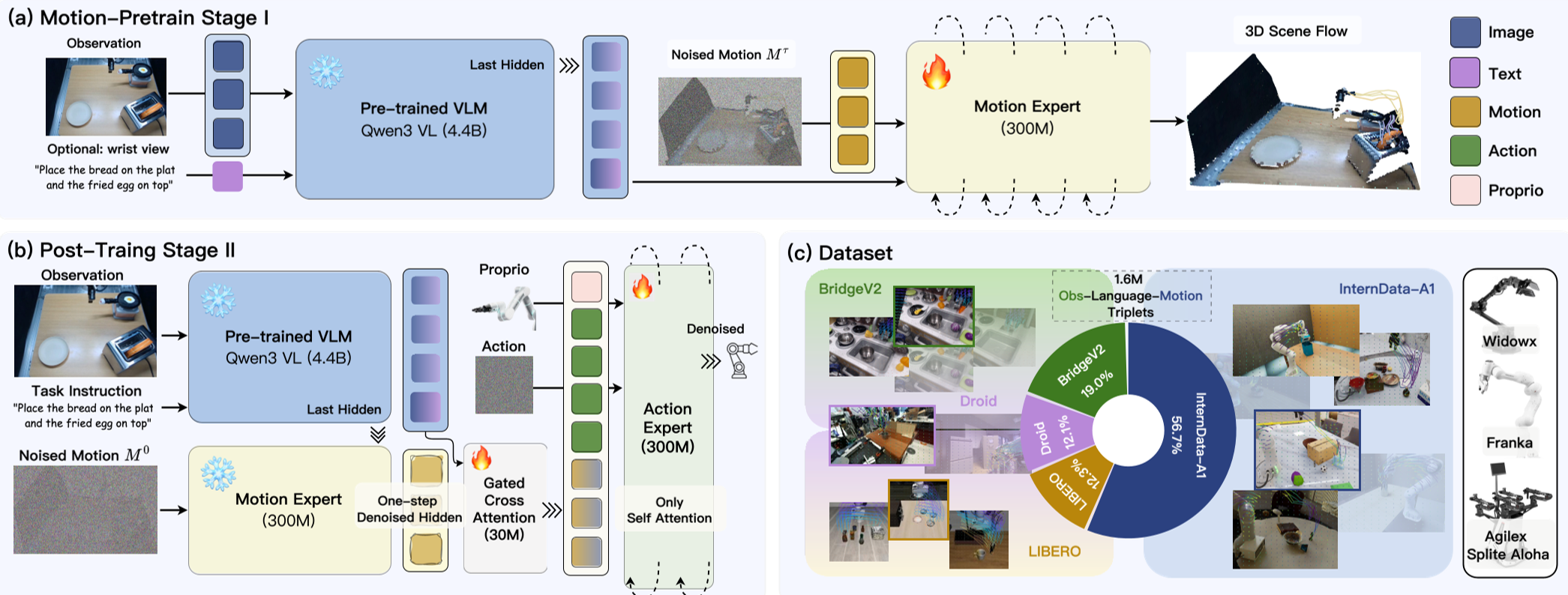
3. Efficiency: One-Step Denoising
Full 3D reconstruction is slow. LaMP cleverly extracts hidden states after just one step of a denoising process. This provides enough "geometric foresight" to guide the Action Expert without the massive computational overhead of generating a full video.
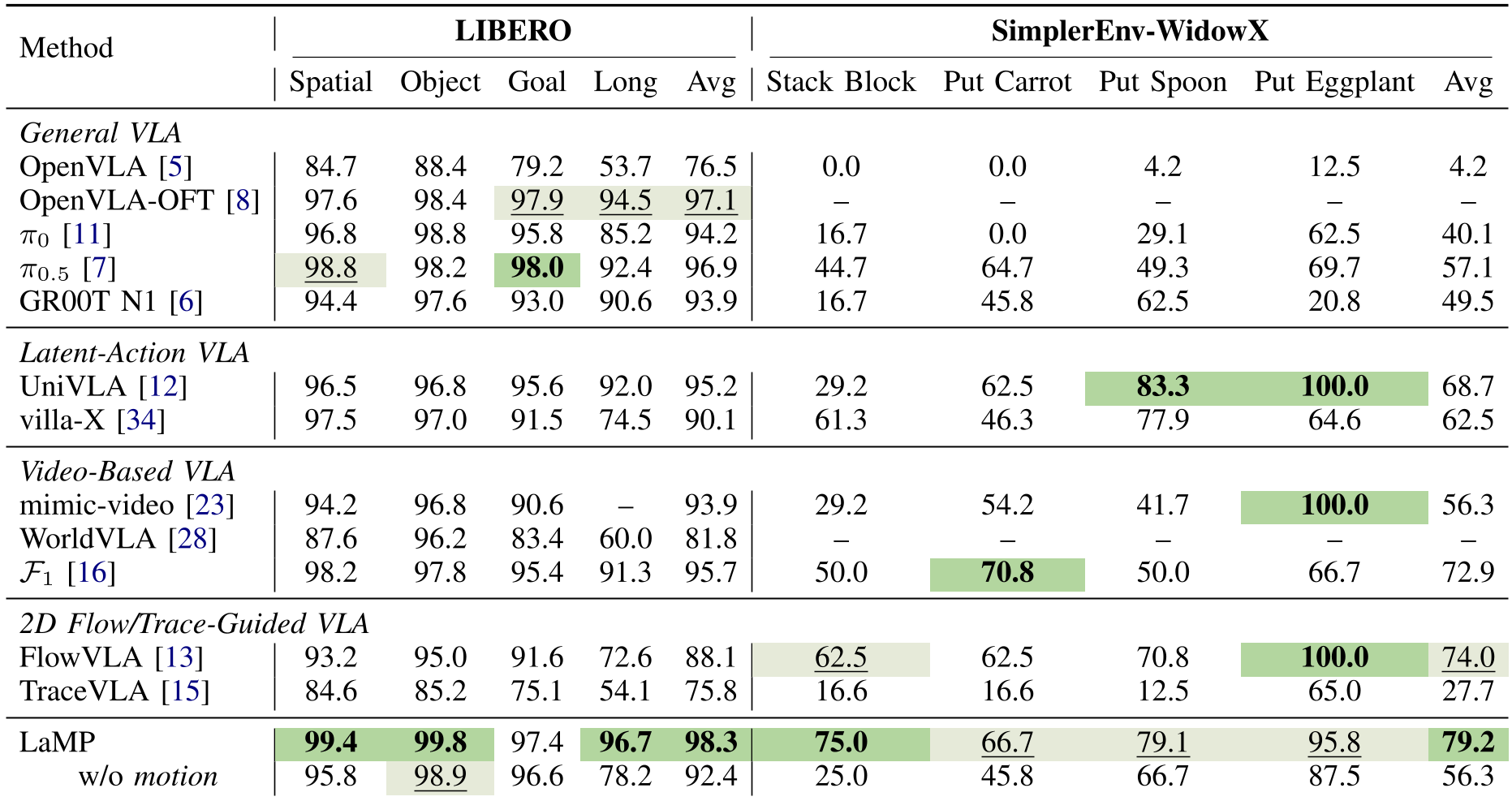
Experimental Results: Precision and Robustness
LaMP was tested against heavyweights like π0.5 and GR00T.
- LIBERO-Long: On multi-stage tasks where errors usually compound, LaMP achieved 96.7%, significantly higher than π0.5 (92.4%).
- Sim-to-Real Robustness: In SimplerEnv-WidowX, which tests how well a model trained on real data works in a simulator, LaMP hit 79.2%, while the next best baseline struggled at 74%.
- OOD Generalization: In the LIBERO-Plus benchmark, LaMP handled camera shifts and robot variations with a 9.7% lead over previous SOTA models.
Visualizing Foresight
In real-world tests (Pick-and-Place, Folding Towels), the Motion Expert's predictions were visualized. As shown below, the model "imagines" the 3D trajectory of the arm and the object, allowing the Action Expert to execute physically grounded movements.

Critical Insights & Future Work
Why it works: The "Gated" mechanism and the use of 3D flow are the MVPs. Ablation studies showed that removing the 3D component (using only 2D flow) caused performance to drop significantly in contact-rich tasks like "Stack Block."
Limitations: Currently, the motion prior is fixed at a $20 imes 20$ grid. For extremely fine-grained tasks (like threading a needle), a higher resolution or adaptive motion representation might be necessary.
The Takeaway: For the next generation of generalist robots, "thinking before acting" means more than just processing language—it means simulating the 3D physics of the immediate future.