Latent-WAM is an end-to-end autonomous driving framework that achieves SOTA trajectory planning using a latent world model. It utilizes a Spatial-Aware Compressive World Encoder (SCWE) and a Dynamic Latent World Model (DLWM) to achieve 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM.
TL;DR
Latent-WAM is an efficient end-to-end autonomous driving framework that prioritizes spatial awareness and temporal dynamics in latent space. By distilling geometric knowledge from a foundation model and using a causal Transformer for world modeling, it achieves a new SOTA of 89.3 EPDMS on NAVSIM v2, surpassing previous perception-free methods by a significant margin with only 104M parameters.
Problem & Motivation: Beyond Pixel-Level Hallucination
The autonomous driving community is currently split between two world-model philosophies:
- Explicit Video Generation: Models like DriveDreamer generate future pixels. While visually impressive, this is computationally expensive and often focuses on "planning-irrelevant" textures (e.g., the color of a building).
- Implicit Latent Prediction: Models like LAW predict future embeddings. These are efficient but historically lack spatial depth and fail to fully exploit ego-motion history, leading to "floating" trajectories or collisions.
The authors of Latent-WAM argue that the bottleneck isn't the data, but the representation quality. They propose that a world model for driving must be "spatially-aware" (knowing where things are in 3D) and "dynamics-informed" (knowing how the world changes based on ego-actions).
Methodology: The Architecture of Intelligence
Latent-WAM consists of two primary pillars:
1. Spatial-Aware Compressive World Encoder (SCWE)
Instead of processing massive image feature maps, Latent-WAM uses a set of learnable queries to compress multi-view images into a compact set of scene tokens. To ensure these tokens aren't just semantic blobs, the authors perform Geometric Alignment. They distill knowledge from WorldMirror (a geometric foundation model) into the DINOv2 backbone.
- Insight: By forcing the backbone to align with geometric priors during training, the model learns to "see" lane boundaries and 3D structures without requiring depth sensors at inference.
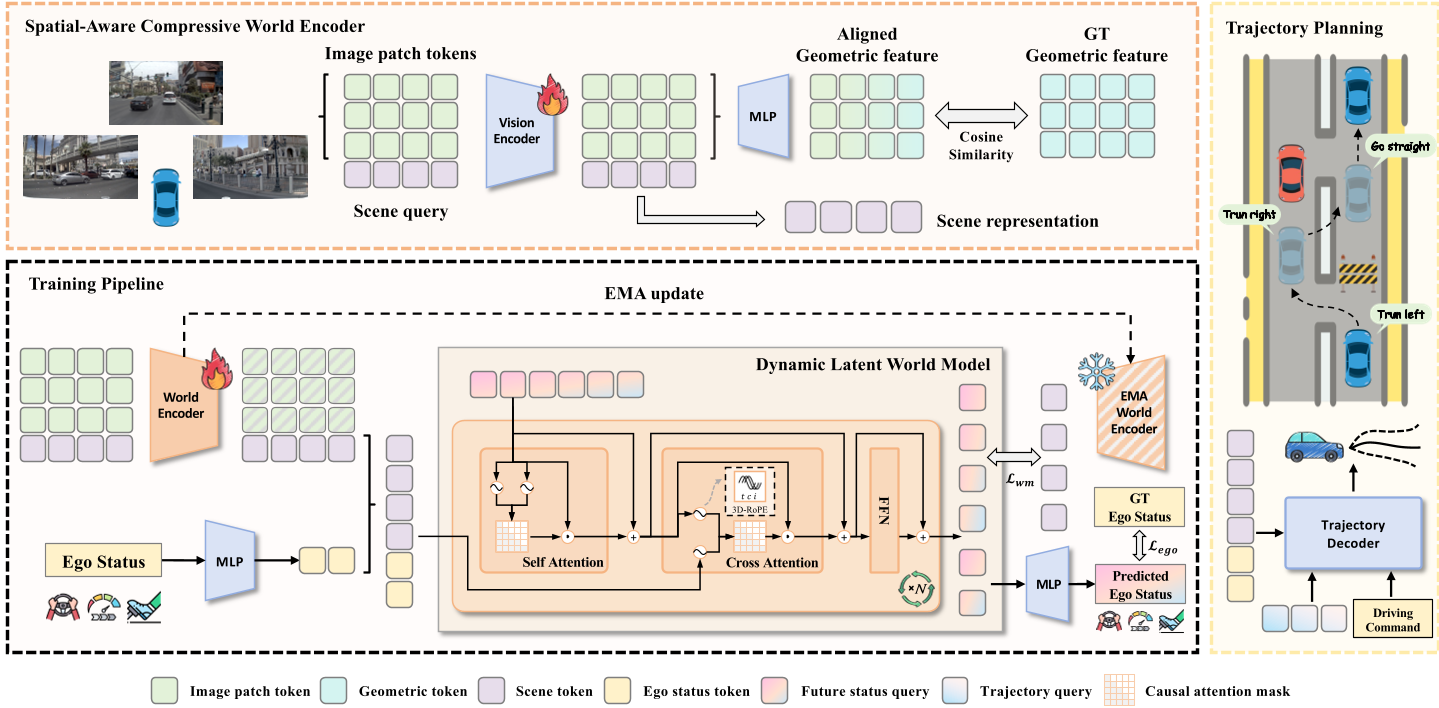
2. Dynamic Latent World Model (DLWM)
The DLWM treats world modeling as a "next-token prediction" task. It uses a Causal Transformer that accepts an interleaved sequence of Scene tokens and Ego tokens (velocity, acceleration, command).
- 3D-RoPE: To handle the spatio-temporal complexity, the model uses 3D Rotary Position Embeddings to distinguish between time, camera view, and query index.
- Self-Supervision: The model learns by predicting future latent states, supervised by an EMA (Exponential Moving Average) version of its own encoder.
Experiments: Breaking the SOTA
The model was tested on NAVSIM v2 and HUGSIM.
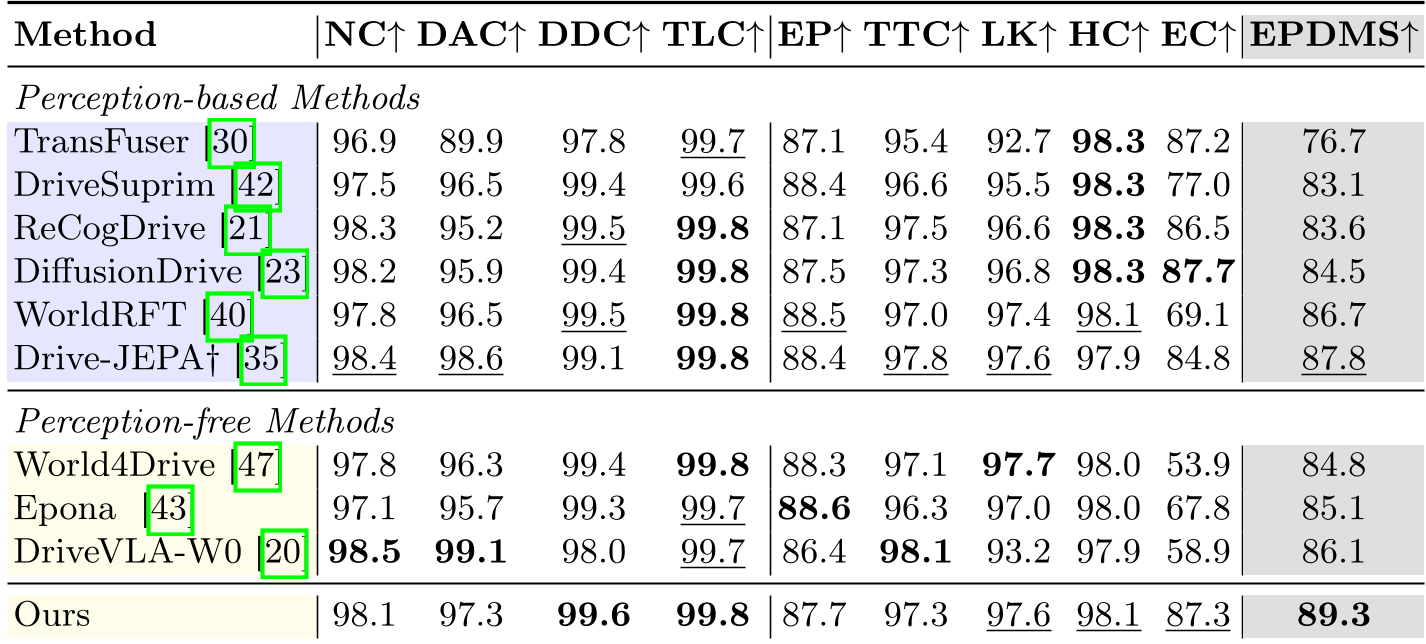
- Quantitative Dominance: On NAVSIM v2, Latent-WAM achieved 89.3 EPDMS, outperforming even "perception-based" models that use explicit 3D labels.
- Zero-Shot Transfer: When trained on NAVSIM and tested on HUGSIM (which uses different sensors and environments like KITTI-360 and Waymo), Latent-WAM maintained a top-tier 28.9 HD-Score, proving the robustness of its latent representations.
Ablation Insight: Why Distillation Wins
A key finding in the ablation study was that Distillation > Concatenation. Simply feeding geometric features into the model actually hurt performance (88.0 EPDMS). However, distilling that knowledge into the backbone's weights allowed the model to internalize 3D logic, reaching 89.3 EPDMS.
Critical Analysis & Conclusion
Takeaway: Latent-WAM proves that world models for driving don't need to be multi-billion parameter monsters or pixel-perfect generators. By focusing on geometric distillation and causal latent transitions, a 104M parameter model can outperform significantly larger baselines.
Limitations: While the model excels in trajectory safety and rule compliance, its "Ego Progress" is slightly lower than some aggressive baselines. This suggests a conservative inductive bias—preferring safety over speed, which is a desirable trait for real-world deployment.
Future Outlook: The success of 3D-RoPE and geometric distillation suggests that "foundation-model-to-driving" knowledge transfer is the most efficient path forward for end-to-end systems.
 Above: Visualization shows how Latent-WAM focuses on lane markings and drivable areas (right) compared to the scattered focus of the baseline (left).
Above: Visualization shows how Latent-WAM focuses on lane markings and drivable areas (right) compared to the scattered focus of the baseline (left).