本文提出了 Latent-WAM,一种高效的端到端自动驾驶框架。该框架通过空间感知压缩世界编码器(SCWE)和动态潜世界模型(DLWM),在 NAVSIM v2 榜单上以 89.3 EPDMS 的成绩刷新了 SOTA,成为目前最强的 Perception-free 方法。
TL;DR
Latent-WAM 提出了一个紧凑且强大的端到端自动驾驶世界模型。它通过几何知识蒸馏让模型具备了敏锐的 3D 空间直觉,并通过因果 Transformer 在潜空间(Latent Space)内实现了高效的未来状态预测,最终在 NAVSIM v2 挑战赛中力压群雄,以 104M 的小体量达成了 89.3 EPDMS 的 SOTA 战绩。
背景定位:世界模型 VS. 显式感知
目前的端到端驾驶主要分为两条路线:一条是依赖显式感知(如检测、分割、占用网格),另一条是基于世界模型的学习。显式感知虽然直观,但标注成本昂贵且系统复杂;而现有的世界模型往往陷入“视觉细节”的泥潭(如视频生成任务),或者在空间认知(Spatial Understanding)上表现薄弱。
Latent-WAM 的核心直觉是:规划不需要完美的视频重建,但需要对空间几何以及动态趋势的深度理解。
核心方法:SCWE 与 DLWM
1. 空间感知压缩世界编码器 (SCWE)
为了解决传统方法中特征冗余的问题,作者设计了 SCWE。其精妙之处在于:
- 几何蒸馏 (Geometric Alignment):利用冻结的几何基础模型 WorldMirror 作为“老师”,通过余弦相似度损失,将 3D 几何特征蒸馏到 DINO 视觉骨干网络中。
- 极度压缩:采用 16 个可学习的查询(Queries),将海量的多视角图像 Patch 压缩为极少量的 Scene Tokens,大幅降低了下游时序建模的计算量。
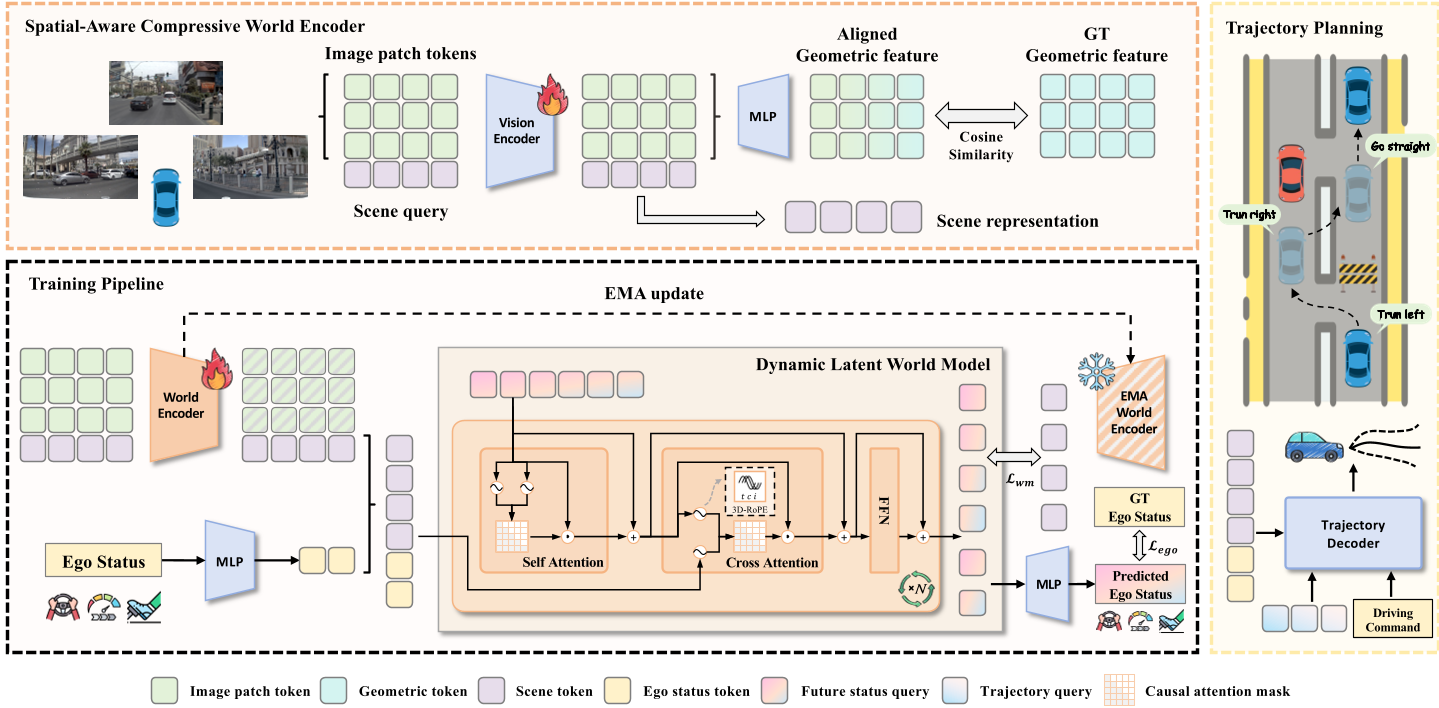
2. 动态潜世界模型 (DLWM)
DLWM 负责预测未来。与简单的单帧预测不同,它采用了:
- 因果 Transformer:通过帧级掩码(Frame-wise Mask)实现多帧并行预测,同时保持时间因果律。
- 3D-RoPE:在旋转位置编码中引入了时间、摄像头视图索引和 Token 位置三位一体的信息,增强了模型对时空间关系的追踪能力。
- Ego 状态耦合:将驾驶指令、速度、加速度等自车信息与视觉特征深度融合,确保“行”与“看”的统一。
实验战绩:Perception-Free 的天花板
在 NAVSIM v2 榜单上,Latent-WAM 表现优异,特别是在安全相关的 NC(无故障碰撞)和规则遵循(DDC, TLC)指标上均处于顶尖水平。
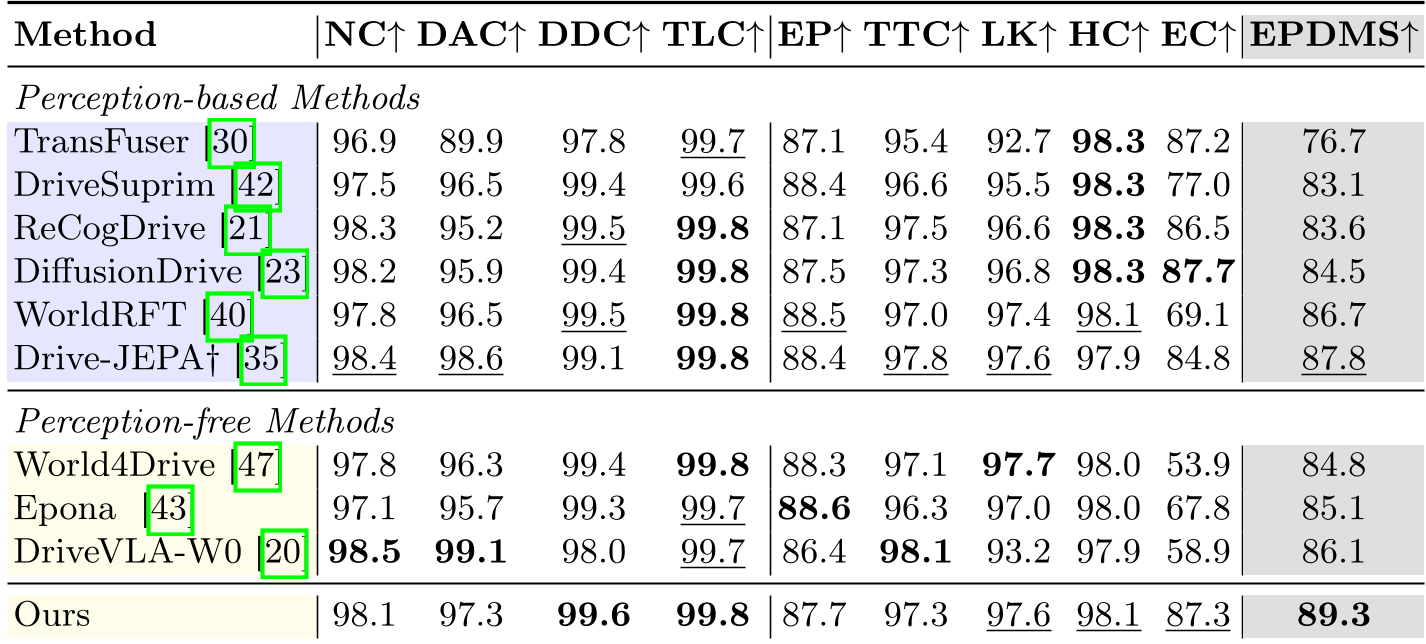
关键洞察:
- 消融实验显示,加入几何信息(Geometry)使 EPDMS 提升了近 1 个百分点,验证了空间感知对由于规划的重要性。
- 注意力可视化:有趣的是,经过几何蒸馏后的模型,其注意力显著集中在车道线、路口边界和障碍物周围,而不再关注天空或建筑等无关背景。
 (上图展示了蒸馏后模型对道路几何结构的精准对齐)
(上图展示了蒸馏后模型对道路几何结构的精准对齐)
深度洞察与总结
Latent-WAM 的成功标志着端到端自动驾驶正从“堆算力、堆生成”向“精细表征、高效建模”转型。
局限性:虽然该模型在公开数据集的表现优异,但其作为一个离线学习的 Planner,在处理极端长尾场景(Corner Cases)时的鲁棒性仍需闭环仿真(Closed-loop)的进一步验证。
未来启示:几何蒸馏无需繁琐的 3D 标注,这为大规模自动驾驶系统的自监督演进提供了一条极具吸引力的路径。